Modelo de documento de ID do Document Intelligence
Este conteúdo aplica-se a:![]() v4.0 (GA) | Versões anteriores:
v4.0 (GA) | Versões anteriores:![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
::: Apelido-fim
Este conteúdo aplica-se a: ![]() v2.1 | Última versão:
v2.1 | Última versão: ![]() v4.0 (GA)
v4.0 (GA)
O modelo de documento de identidade (ID) de inteligência de documentos combina reconhecimento ótico de caracteres (OCR) com modelos de aprendizagem profunda para analisar e extrair informações importantes de documentos de identidade. A API analisa documentos de identidade (incluindo os seguintes) e retorna uma representação de dados JSON estruturada.
| País/Região | Tipos de documentos |
|---|---|
| Mundial | Livro de Passaporte, Cartão de Passaporte |
| Estados Unidos da América | Carta de Condução, Bilhete de Identidade, Autorização de Residência (Green card), Cartão de Segurança Social, Bilhete de Identidade Militar |
| Europa | Carta de Condução, Bilhete de Identidade, Autorização de Residência |
| Índia | Carta de Condução, Cartão PAN, Cartão Aadhaar |
| Canadá | Carta de Condução, Bilhete de Identidade, Autorização de Residência (Maple Card) |
| Austrália | Carta de Condução, Cartão com Fotografia, Key-pass ID (incluindo versão digital) |
O Document Intelligence pode analisar e extrair informações de documentos de identificação (IDs) emitidos pelo governo usando seu modelo de IDs pré-construído. Ele combina nossos poderosos recursos de Reconhecimento Ótico de Caracteres (OCR) com recursos de reconhecimento de ID para extrair informações importantes de Passaportes Mundiais e Carteiras de Motorista dos EUA (todos os 50 estados e DC). A API IDs extrai informações importantes desses documentos de identidade, como nome, sobrenome, data de nascimento, número do documento e muito mais. Esta API está disponível no Document Intelligence v2.1 como um serviço de nuvem.
Processamento de documentos de identidade
O processamento de documentos de identidade envolve a extração de dados de documentos de identidade manualmente ou usando tecnologia baseada em OCR. O processamento de documentos de identificação é uma etapa importante em qualquer operação comercial que exija prova de identidade. Os exemplos incluem verificação de clientes em bancos e outras instituições financeiras, pedidos de hipoteca, consultas médicas, processamento de sinistros, indústria hoteleira e muito mais. Os indivíduos fornecem alguma prova de sua identidade por meio de carteiras de motorista, passaportes e outros documentos semelhantes para que a empresa possa verificá-los de forma eficiente antes de fornecer serviços e benefícios.
Exemplo de Carteira de Motorista dos EUA processada com o Document Intelligence Studio
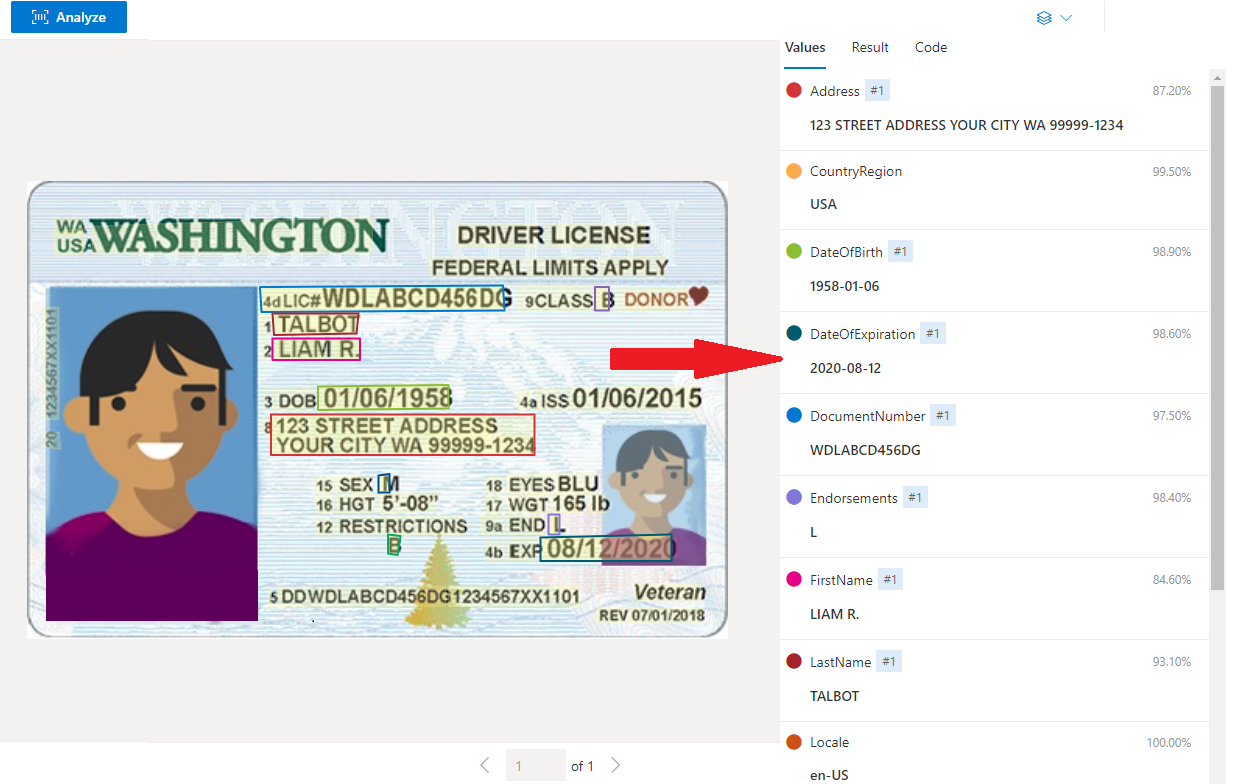
Extração de dados
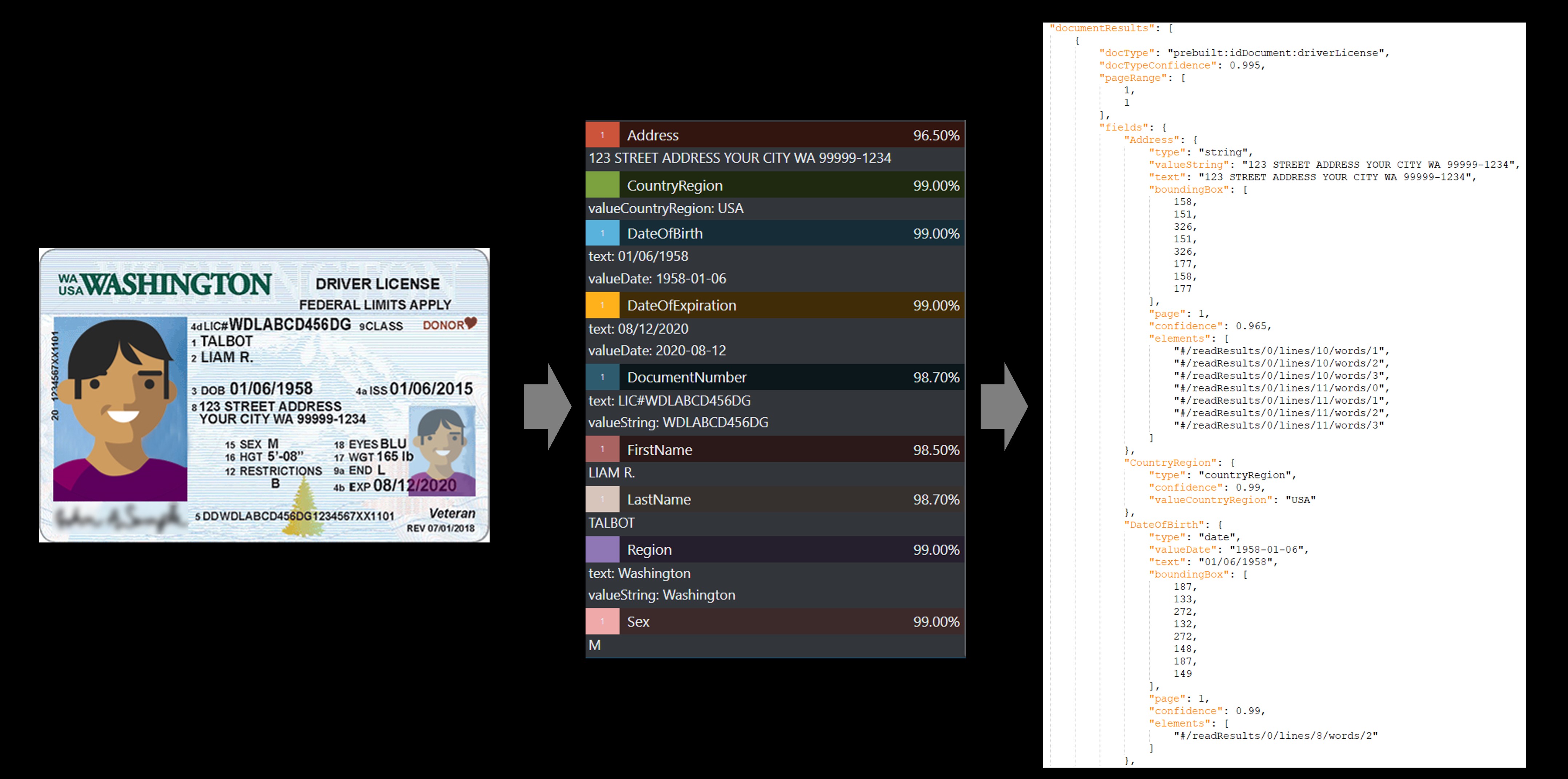
O serviço de IDs pré-construído extrai os valores-chave de passaportes mundiais e carteiras de motorista dos EUA e os retorna em uma resposta JSON estruturada organizada.
Exemplo de carta de condução
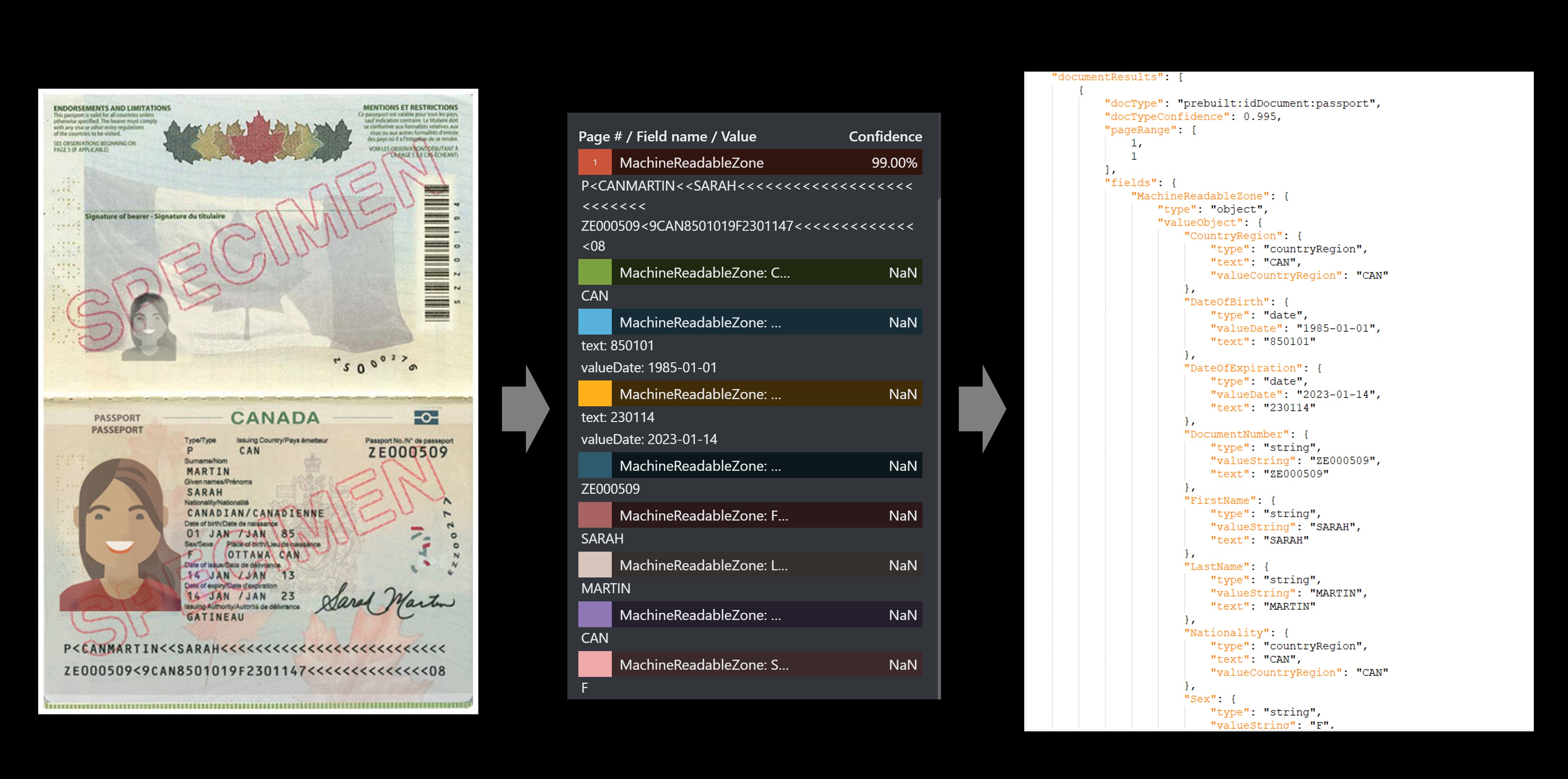
Exemplo de passaporte
Opções de desenvolvimento
O Document Intelligence v4.0: 2024-11-30 (GA) suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de documento de identificação | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
O Document Intelligence v3.1 suporta as seguintes ferramentas, aplicativos e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de documento de identificação | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
O Document Intelligence v3.0 suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de documento de identificação | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
O Document Intelligence v2.1 suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos |
|---|---|
| Modelo de documento de identificação | • Ferramenta de etiquetagem de Inteligência Documental• API REST • SDK de biblioteca cliente• Contêiner Docker de Inteligência Documental |
Requisitos de entrada
Formatos de ficheiro suportados:
Modelo PDF Imagem: JPEG/JPG,PNG,BMP,TIFF, ,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLida ✔ ✔ ✔ Esquema ✔ ✔ ✔ Documento Geral ✔ ✔ Pré-criado ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 pixels x 50 pixels e 10.000 pixels x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a cerca
8de texto pontual a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GB com um máximo de 10.000 páginas. Para 2024-11-30 (GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Formatos de ficheiro suportados: JPEG, PNG, PDF e TIFF.
Número de páginas suportado para ficheiros PDF e TIFF: até 2.000 páginas ou apenas as duas primeiras páginas para subscritores gratuitos.
Tamanho do ficheiro suportado: menos de 50 MB TOTAL; Pixels mínimos: 50 x 50 px; máximo de pixels 10.000 x 10.000 px.
Extração de dados do modelo de documento de identificação
Extraia dados, incluindo nome, data de nascimento e data de validade, de documentos de identificação. Você precisa dos seguintes recursos:
Uma assinatura do Azure — você pode criar uma gratuitamente.
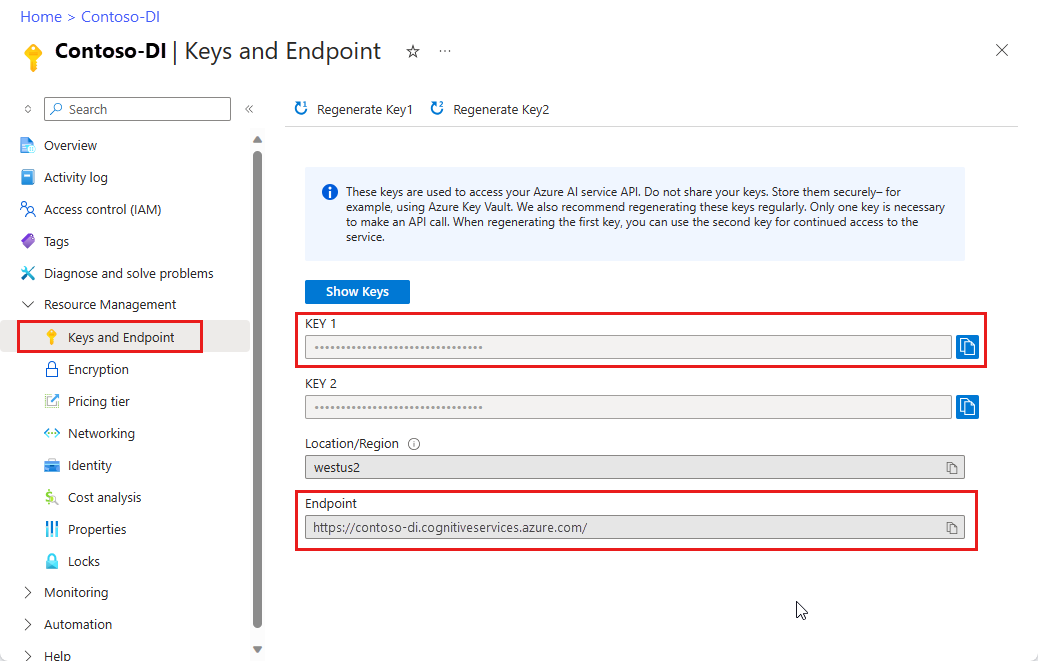
Uma instância de Document Intelligence no portal do Azure. Você pode usar o nível de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter sua chave e o ponto de extremidade.
Nota
O Document Intelligence Studio está disponível com APIs v3.1 e v3.0 e versões posteriores.
Na home page do Document Intelligence Studio, selecione Documentos de identidade.
Você pode analisar a fatura de amostra ou fazer upload de seus próprios arquivos.
Selecione o botão Executar análise e, se necessário, configure as opções Analisar:

Ferramenta de etiquetagem de exemplo de inteligência de documentos
Navegue até a Ferramenta de Exemplo de Inteligência de Documentos.
Na página inicial da ferramenta de exemplo, selecione o bloco Usar modelo pré-criado para obter dados .
Selecione o Tipo de formulário a ser analisado no menu suspenso.
Escolha um URL para o arquivo que você gostaria de analisar a partir das opções abaixo:
- Exemplo de documento de fatura.
- Exemplo de documento de identificação.
- Imagem de recibo de amostra.
- Exemplo de imagem de cartão de visita.
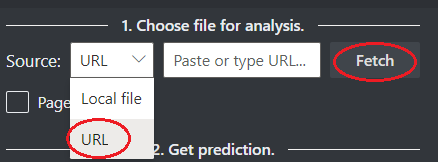
No campo Origem, selecione URL no menu suspenso, cole o URL selecionado e selecione o botão Buscar.
No campo Ponto de extremidade do serviço de Inteligência Documental, cole o ponto de extremidade obtido com sua assinatura do Document Intelligence.
No campo chave, cole a chave obtida do recurso Document Intelligence.

Selecione Executar análise. A ferramenta Document Intelligence Sample Labeling chama a API Analyze Prebuilt e analisa o documento.
Exibir os resultados - veja os pares chave-valor extraídos, itens de linha, texto realçado extraído e tabelas detetadas.
Baixe o arquivo de saída JSON para visualizar os resultados detalhados.
- O nó "readResults" contém todas as linhas de texto com seu respetivo posicionamento de caixa delimitadora na página.
- O nó "selectionMarks" mostra cada marca de seleção (caixa de seleção, marca de rádio) e se seu status está selecionado ou desmarcado.
- A seção "pageResults" inclui as tabelas extraídas. Para cada tabela, o Document Intelligence extrai o índice de texto, linha e coluna, a abrangência de linhas e colunas, a caixa delimitadora e muito mais.
- O campo "documentResults" contém informações de pares chave/valor e informações de itens de linha para as partes mais relevantes do documento.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nota
A ferramenta Exemplo de etiquetagem não suporta o formato de ficheiro BMP. Esta é uma limitação da ferramenta e não do Serviço de Inteligência Documental.
Extrações de campo
Para campos de extração de documentos suportados, consulte a página ID document model schema em nosso repositório de exemplo do GitHub.
Tipos de documentos suportados
O modelo de documento de identificação atualmente suporta carteiras de motorista dos EUA e a página biográfica da extração de passaportes internacionais (excluindo vistos e outros documentos de viagem).
Campos extraídos
| Nome | Tipo | Description | valor |
|---|---|---|---|
| Country | país/região | Código do país em conformidade com a norma ISO 3166 | "EUA" |
| Data de Nascimento | data | Data de nascimento no formato AAAA-MM-DD | "1980-01-01" |
| DatadeExpiração | data | Data de validade no formato AAAA-MM-DD | "2019-05-05" |
| Número do documento | string | Número de passaporte relevante, número da carta de condução, etc. | "340020013" |
| FirstName | string | Nome próprio extraído e inicial do meio, se aplicável | "JENNIFER" |
| LastName | string | Apelido extraído | "RIBEIRO" |
| Nacionalidade | país/região | Código do país em conformidade com a norma ISO 3166 | "EUA" |
| Sexo | sexo | Os possíveis valores extraídos incluem "M", "F", "X" | "F" |
| MachineReadableZone | objeto | Passaporte MRZ extraído, incluindo duas linhas de 44 caracteres cada |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307 715816" |
| DocumentType | string | Tipo de documento, por exemplo, Passaporte, Carta de Condução | "passaporte" |
| Endereço | string | Endereço extraído (apenas Carta de Condução) | "123 ENDEREÇO SUA CIDADE WA 99999-1234" |
| País/Região | string | Região, estado, província, etc. extraídos (apenas Carta de Condução) | "Washington" |
Guia de migração
- Siga nosso guia de migração do Document Intelligence v3.1 para saber como usar a versão v3.0 em seus aplicativos e fluxos de trabalho.
Próximos passos
Tente processar seus próprios formulários e documentos com o Document Intelligence Studio.
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Tente processar seus próprios formulários e documentos com a ferramenta Document Intelligence Sample Labeling.
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.