Modelo de cartão de visita Document Intelligence
Importante
Começando com o Document Intelligence v4.0 e no futuro, o modelo de cartão de visita (cartão de visita pré-construído) foi preterido. Para extrair dados de formatos de cartão de visita, use o seguinte:
| Caraterística | versão | Model ID |
|---|---|---|
| Modelo de cartão de visita | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-businessCard |
[! INCLUDE [aplica-se à v2.1].. /(inclui/aplica-se à v21.md)]
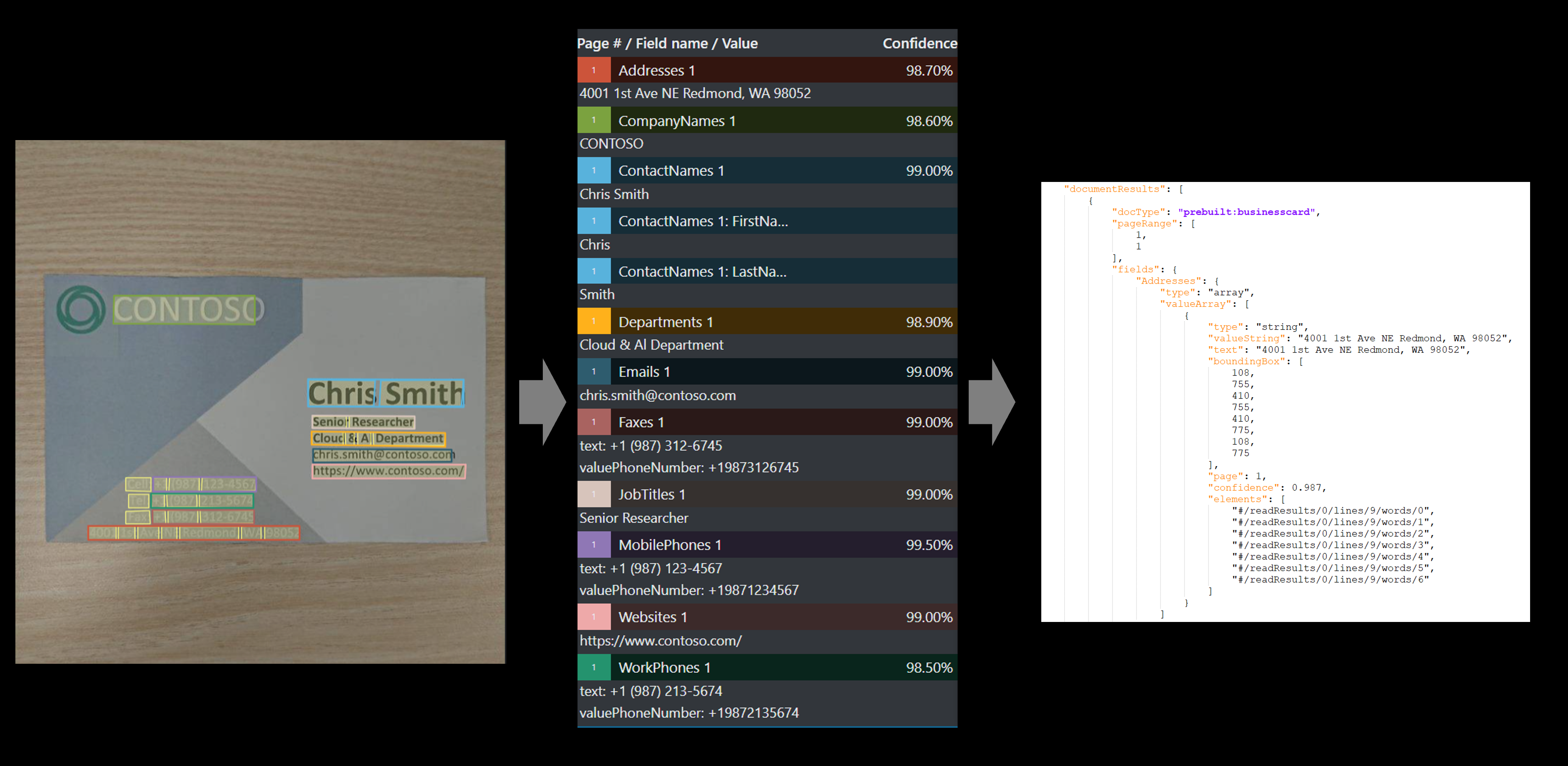
O modelo de cartão de visita Document Intelligence combina poderosos recursos de Reconhecimento Ótico de Caracteres (OCR) com modelos de aprendizagem profunda para analisar e extrair dados de imagens de cartões de visita. A API analisa cartões de visita impressos; extrai informações importantes, como nome, sobrenome, nome da empresa, endereço de e-mail e número de telefone; e retorna uma representação de dados JSON estruturada.
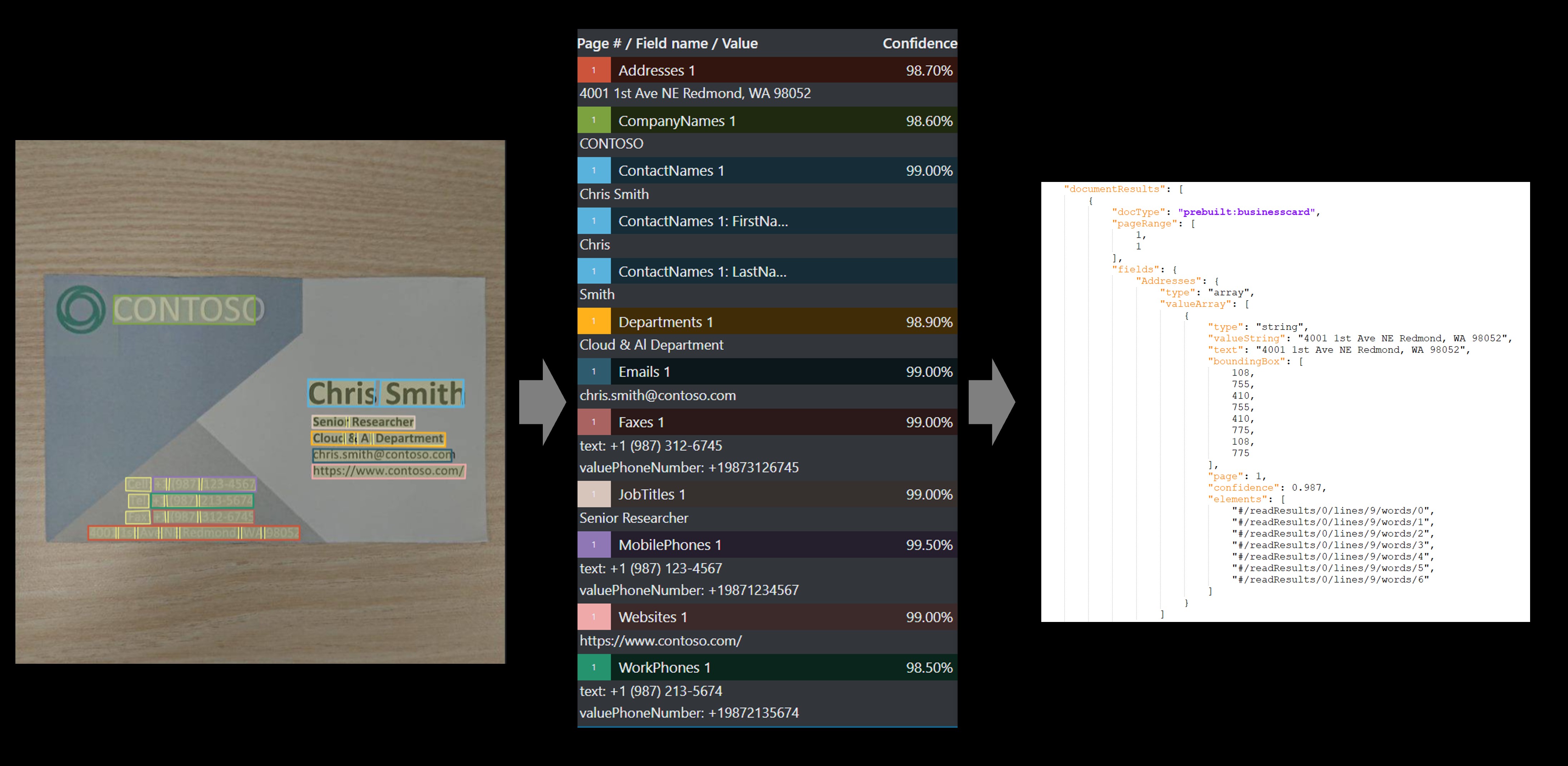
Extração de dados de cartão de visita
Os cartões de visita são uma ótima maneira de representar uma empresa ou um profissional. O logotipo da empresa, fontes e imagens de fundo encontradas em cartões de visita ajudam a promover a marca da empresa e diferenciá-la das outras. A aplicação de OCR e técnicas baseadas em aprendizado de máquina para automatizar a digitalização de cartões de visita é um cenário comum de processamento de imagem. Os sistemas empresariais usados pelas equipes de vendas e marketing normalmente têm integração com a capacidade de extração de dados de cartão de visita para o benefício de seus usuários.
Exemplo de cartão de visita processado com o Document Intelligence Studio

Exemplos de negócios processados com a ferramenta Document Intelligence Sample Labeling
Opções de desenvolvimento
O Document Intelligence v3.1:2023-07-31 (GA) suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de cartão de visita | • Estúdio de Inteligência Documental • API REST • SDK em C# • SDK Python • SDK Java • SDK JavaScript |
cartão de visita pré-construído |
O Document Intelligence v3.0:2022-08-31 (GA) suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de cartão de visita | • Estúdio de Inteligência Documental • API REST • SDK em C# • SDK Python • SDK Java • SDK JavaScript |
cartão de visita pré-construído |
O Document Intelligence v2.1 (GA) suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos |
|---|---|
| Modelo de cartão de visita | • Ferramenta de etiquetagem de Inteligência Documental • API REST • SDK da biblioteca cliente • Contentor Docker de Inteligência Documental |
Experimente a extração de dados do cartão de visita
Veja como os dados, incluindo nome, cargo, endereço, e-mail e nome da empresa, são extraídos dos cartões de visita. Você precisa dos seguintes recursos:
Uma assinatura do Azure — você pode criar uma gratuitamente
Uma instância de Document Intelligence no portal do Azure. Você pode usar o nível de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter sua chave e o ponto de extremidade.
Estúdio de Inteligência de Documentação
Nota
O Document Intelligence Studio está disponível com APIs v3.1 e v3.0.
Na página inicial do Document Intelligence Studio, selecione Cartões de visita.
Você pode analisar o cartão de visita de amostra ou fazer upload de seus próprios arquivos.
Selecione o botão Executar análise e, se necessário, configure as opções Analisar :

Ferramenta de etiquetagem de exemplo de inteligência de documentos
Navegue até a Ferramenta de Exemplo de Inteligência de Documentos.
Na página inicial da ferramenta de exemplo, selecione o bloco Usar modelo pré-criado para obter dados .
Selecione o Tipo de formulário a ser analisado no menu suspenso.
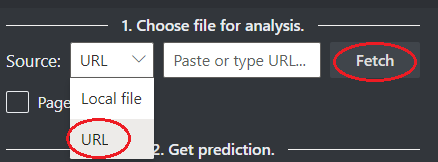
Escolha um URL para o arquivo que você gostaria de analisar a partir das opções abaixo:
- Exemplo de documento de fatura.
- Exemplo de documento de identificação.
- Imagem de recibo de amostra.
- Exemplo de imagem de cartão de visita.
No campo Origem, selecione URL no menu suspenso, cole o URL selecionado e selecione o botão Buscar.
No campo Ponto de extremidade do serviço de Inteligência Documental, cole o ponto de extremidade obtido com sua assinatura do Document Intelligence.
No campo chave, cole a chave obtida do recurso Document Intelligence.

Selecione Executar análise. A ferramenta Document Intelligence Sample Labeling chama a API Analyze Prebuilt e analisa o documento.
Exibir os resultados - veja os pares chave-valor extraídos, itens de linha, texto realçado extraído e tabelas detetadas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nota
A ferramenta Exemplo de etiquetagem não suporta o formato de ficheiro BMP. Esta é uma limitação da ferramenta e não do Serviço de Inteligência Documental.
Requisitos de entrada
Formatos de ficheiro suportados:
Modelo PDF Imagem: JPEG/JPG,PNG,BMP,TIFF, ,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLida ✔ ✔ ✔ Esquema ✔ ✔ ✔ Documento Geral ✔ ✔ Pré-criado ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 pixels x 50 pixels e 10.000 pixels x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a cerca
8de texto pontual a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GB com um máximo de 10.000 páginas. Para 2024-11-30 (GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
- Os formatos de ficheiro suportados: JPEG, PNG, PDF e TIFF
- PDF e TIFF, até 2.000 páginas são processadas. Para assinantes de nível gratuito, apenas as duas primeiras páginas são processadas.
- O tamanho do arquivo deve ser inferior a 50 MB e dimensões de pelo menos 50 x 50 pixels e no máximo 10.000 x 10.000 pixels.
Idiomas e localidades suportados
Para obter uma lista completa dos idiomas suportados, consulte nossa página de suporte a idiomas de modelo pré-criados.
Extrações de campo
Para campos de extração de documentos suportados, consulte a página de esquema de modelo de cartão de visita em nosso repositório de exemplo do GitHub.
Campos extraídos
| Nome | Tipo | Descrição | Texto |
|---|---|---|---|
| NomesContactos | matriz de objetos | Nome de contato extraído do cartão de visita | [{ "Nome": "John", "Sobrenome": "Doe" }] |
| FirstName | string | Primeiro nome (fornecido) do contacto | "João" |
| LastName | string | Último nome (da família) do contacto | "Doe" |
| Nomes das Empresas | matriz de cadeias | Nome da empresa extraído do cartão de visita | ["Contoso"] |
| Departmentos | matriz de cadeias | Departamento ou organização de contacto | ["I&D"] |
| CargosTítulos | matriz de cadeias | Listado Cargo de contato | ["Engenheiro de Software"] |
| E-mails | matriz de cadeias | E-mail de contato extraído do cartão de visita | ["johndoe@contoso.com"] |
| Web Sites | matriz de cadeias | Website extraído do cartão de visita | ["https://www.contoso.com"] |
| Endereços | matriz de cadeias | Endereço extraído do cartão de visita | ["123 Main Street, Redmond, Washington 98052"] |
| Telemóveis | Matriz de números de telefone | Número de telemóvel extraído do cartão de visita | ["+19876543210"] |
| Faxes | Matriz de números de telefone | Número de telefone de fax extraído do cartão de visita | ["+19876543211"] |
| Telefones de trabalho | Matriz de números de telefone | Número de telefone de trabalho extraído do cartão de visita | ["+19876543231"] |
| OutrosTelefones | Matriz de números de telefone | Outro número de telefone extraído do cartão de visita | ["+19876543233"] |
Localidades suportadas
Cartões de visita pré-construídos v2.1 suporta as seguintes localidades:
- pt-PT
- pt-PT
- en-ca
- pt-GB
- en-in
Guia de migração e API REST v3.1
- Siga nosso guia de migração do Document Intelligence v3.1 para saber como usar a versão v3.0 em seus aplicativos e fluxos de trabalho.
Próximos passos
Experimente processar os seus próprios formulários e documentos com o Document Intelligence Studio
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Tente processar seus próprios formulários e documentos com a ferramenta Document Intelligence Sample Labeling
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.