Geração aumentada de recuperação com o Azure AI Document Intelligence
Este conteúdo aplica-se a: ![]() v4.0 (pré-visualização)
v4.0 (pré-visualização)
Introdução
A Geração Aumentada de Recuperação (RAG) é um padrão de design que combina um Modelo de Linguagem Grande (LLM) pré-treinado como o ChatGPT com um sistema de recuperação de dados externo para gerar uma resposta aprimorada incorporando novos dados fora dos dados de treinamento originais. Adicionar um sistema de recuperação de informações aos seus aplicativos permite que você converse com seus documentos, gere conteúdo cativante e acesse o poder dos modelos OpenAI do Azure para seus dados. Você também tem mais controle sobre os dados usados pelo LLM à medida que formula uma resposta.
O modelo Document Intelligence Layout é uma API avançada de análise de documentos baseada em aprendizado de máquina. O modelo de layout oferece uma solução abrangente para recursos avançados de extração de conteúdo e análise de estrutura de documentos. Com o modelo Layout, você pode extrair facilmente texto e elementos estruturais para dividir grandes corpos de texto em partes menores e significativas com base em conteúdo semântico, em vez de divisões arbitrárias. As informações extraídas podem ser convenientemente enviadas para o formato Markdown, permitindo que você defina sua estratégia de fragmentação semântica com base nos blocos de construção fornecidos.
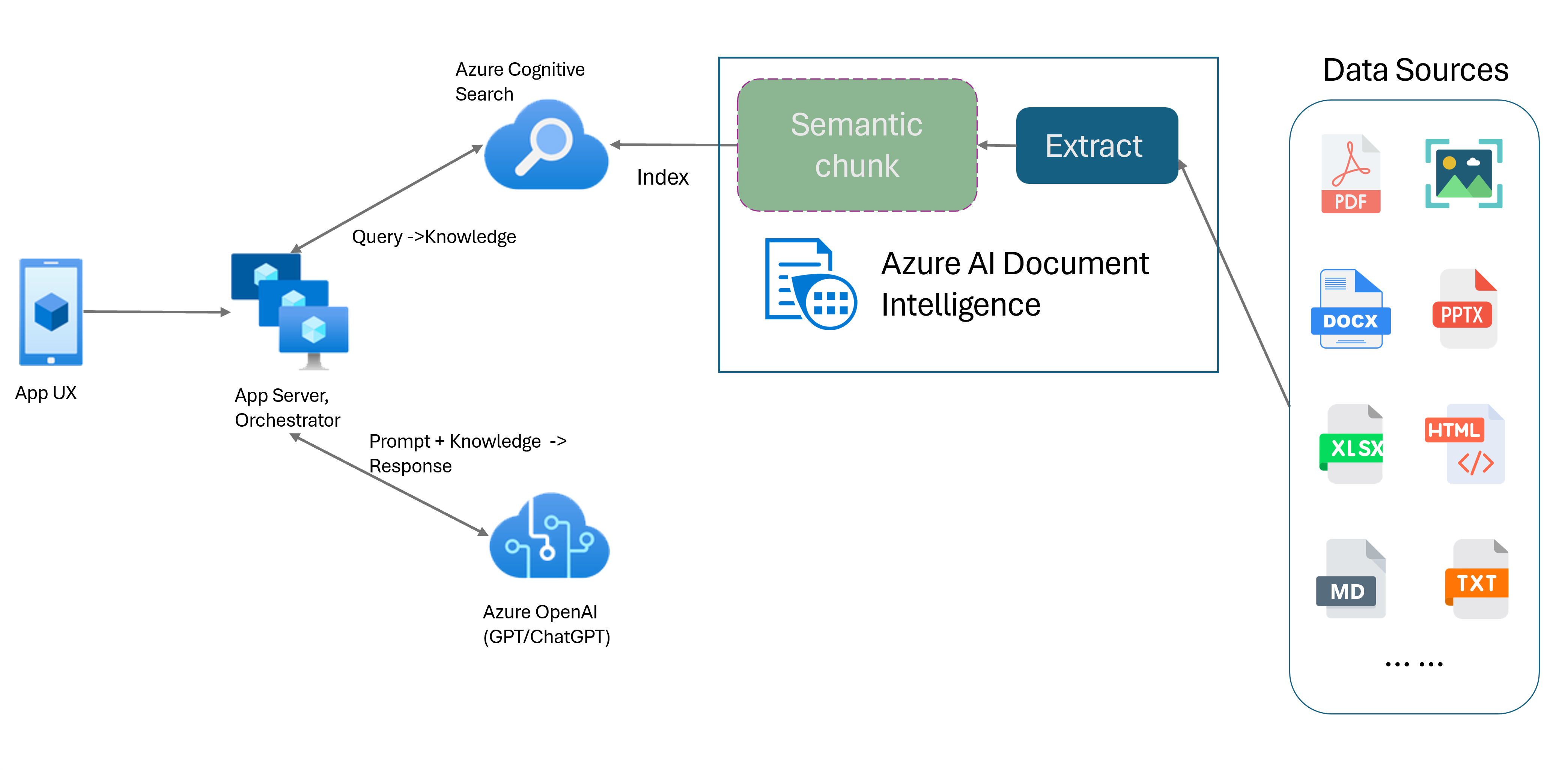
Fragmentação semântica
Frases longas são desafiadoras para aplicações de processamento de linguagem natural (NLP). Especialmente quando são compostas por várias cláusulas, frases verbais ou substantivos complexos, orações relativas e agrupamentos entre parênteses. Assim como o espectador humano, um sistema de PNL também precisa acompanhar com sucesso todas as dependências apresentadas. O objetivo da fragmentação semântica é encontrar fragmentos semanticamente coerentes de uma representação de frase. Esses fragmentos podem então ser processados de forma independente e recombinados como representações semânticas sem perda de informação, interpretação ou relevância semântica. O significado inerente ao texto é usado como um guia para o processo de fragmentação.
As estratégias de fragmentação de dados de texto desempenham um papel fundamental na otimização da resposta e do desempenho do RAG. Tamanho fixo e semântica são dois métodos distintos de fragmentação:
Fragmentação de tamanho fixo. A maioria das estratégias de fragmentação usadas no RAG atualmente são baseadas em segmentos de texto de tamanho fixo conhecidos como blocos. A fragmentação de tamanho fixo é rápida, fácil e eficaz com texto que não tem uma estrutura semântica forte, como logs e dados. No entanto, não é recomendado para textos que exijam compreensão semântica e contexto preciso. A natureza de tamanho fixo da janela pode resultar no corte de palavras, frases ou parágrafos, impedindo a compreensão e interrompendo o fluxo de informações e compreensão.
Fragmentação semântica. Este método divide o texto em partes com base na compreensão semântica. Os limites de divisão são focados no assunto da frase e usam recursos computacionais complexos algorítmicos significativos. No entanto, tem a vantagem distinta de manter a consistência semântica dentro de cada bloco. É útil para tarefas de resumo de texto, análise de sentimento e classificação de documentos.
Fragmentação semântica com modelo de layout de inteligência de documento
Markdown é uma linguagem de marcação estruturada e formatada e uma entrada popular para permitir o agrupamento semântico em RAG (Retrieval-Augmented Generation). Você pode usar o conteúdo Markdown do modelo Layout para dividir documentos com base nos limites de parágrafo, criar blocos específicos para tabelas e ajustar sua estratégia de fragmentação para melhorar a qualidade das respostas geradas.
Benefícios do uso do modelo de layout
Processamento simplificado. Você pode analisar diferentes tipos de documentos, como PDFs digitais e digitalizados, imagens, arquivos de escritório (docx, xlsx, pptx) e HTML, com apenas uma única chamada de API.
Escalabilidade e qualidade de IA. O modelo de layout é altamente escalável em reconhecimento ótico de caracteres (OCR), extração de tabela e análise de estrutura de documentos. Ele suporta 309 idiomas impressos e 12 manuscritos, garantindo ainda mais resultados de alta qualidade impulsionados por recursos de IA.
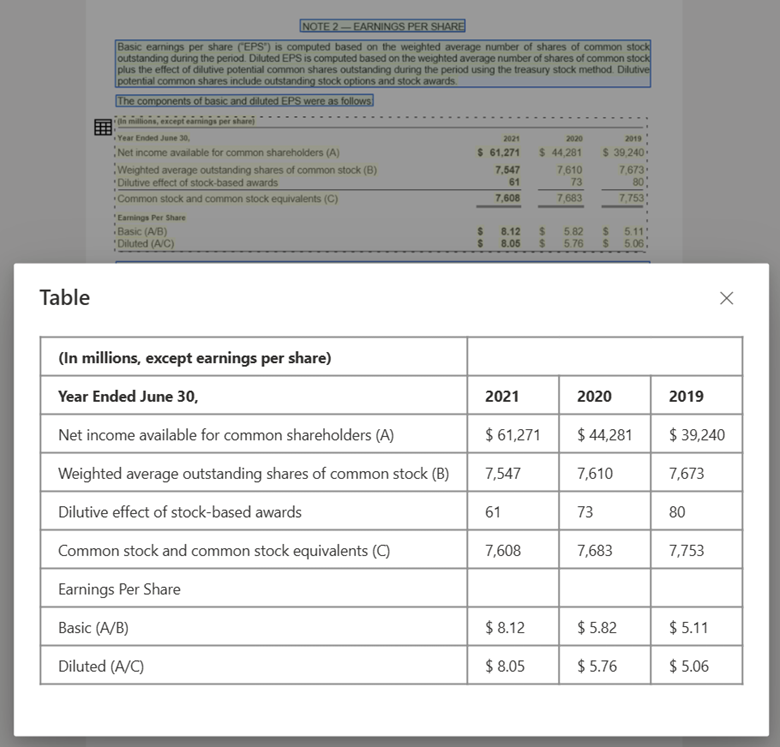
Compatibilidade com modelo de linguagem grande (LLM). A saída formatada em Markdown do modelo de layout é amigável para LLM e facilita a integração perfeita em seus fluxos de trabalho. Você pode transformar qualquer tabela em um documento no formato Markdown e evitar um esforço extensivo analisando os documentos para uma maior compreensão do LLM.
Imagem de texto processada com o Document Intelligence Studio e saída para MarkDown usando o modelo de layout

Imagem de tabela processada com o Document Intelligence Studio usando o modelo de layout
Começar agora
O modelo de layout de inteligência documental 2024-07-31-preview e 2023-10-31-preview suporta as seguintes opções de desenvolvimento:
Estúdio de Inteligência Documental.
.NET • Java • JavaScript • Bibliotecas de cliente de linguagem de programação Python (SDKs).
Pronto para começar?
Estúdio de Inteligência de Documentação
Você pode seguir o início rápido do Document Intelligence Studio para começar. Em seguida, você pode integrar recursos de Document Intelligence com seu próprio aplicativo usando o código de exemplo fornecido.
Comece com o modelo Layout. Você precisa selecionar as seguintes opções de Análise para usar o RAG no estúdio:
**Required**- Execute o intervalo de análise → Documento atual.
- Intervalo de páginas → Todas as páginas.
- Estilo de formato de saída → Markdown.
**Optional**- Você também pode selecionar parâmetros de deteção opcionais relevantes.
Selecione Guardar.
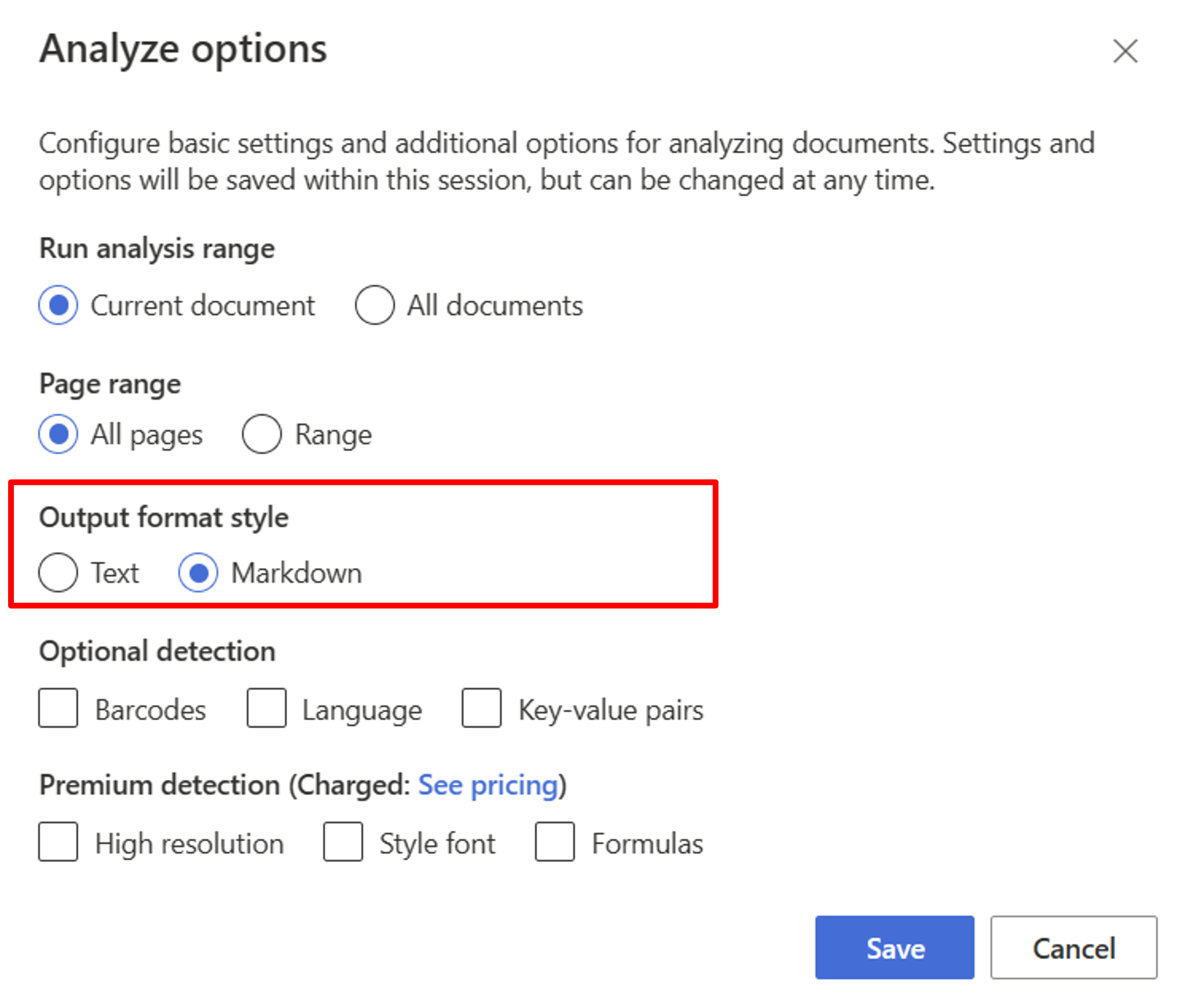
Selecione o botão Executar análise para visualizar a saída.

SDK ou API REST
Você pode seguir o início rápido do Document Intelligence para sua linguagem de programação preferida, SDK ou API REST. Use o modelo de layout para extrair conteúdo e estrutura de seus documentos.
Você também pode conferir repositórios do GitHub para obter exemplos de código e dicas para analisar um documento no formato de saída de markdown.
Crie um bate-papo de documentos com fragmentação semântica
O Azure OpenAI em seus dados permite que você execute o bate-papo com suporte em seus documentos. O Azure OpenAI em seus dados aplica o modelo de Layout de Inteligência Documental para extrair e analisar dados de documentos fragmentando texto longo com base em tabelas e parágrafos. Você também pode personalizar sua estratégia de fragmentação usando scripts de exemplo do Azure OpenAI localizados em nosso repositório GitHub.
O Azure AI Document Intelligence agora está integrado ao LangChain como um de seus carregadores de documentos. Você pode usá-lo para carregar facilmente os dados e a saída para o formato Markdown. Para obter mais informações, consulte nosso código de exemplo que mostra uma demonstração simples para o padrão RAG com o Azure AI Document Intelligence como carregador de documentos e o Azure Search como retriever em LangChain.
O bate-papo com seu exemplo de código acelerador de solução de dados demonstra um exemplo de padrão RAG de linha de base de ponta a ponta. Ele usa o Azure AI Search como um retriever e o Azure AI Document Intelligence para carregamento de documentos e fragmentação semântica.
Caso de utilização
Se você estiver procurando por uma seção específica em um documento, poderá usar a divisão semântica para dividir o documento em partes menores com base nos cabeçalhos de seção, ajudando você a encontrar a seção que está procurando de forma rápida e fácil:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Próximos passos
Saiba mais sobre o Azure AI Document Intelligence.
Saiba como processar seus próprios formulários e documentos com o Document Intelligence Studio.
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.