Guia de início rápido: reconhecer intenções com o entendimento de linguagem conversacional
Pacote de documentação | de referência (NuGet) | Exemplos adicionais no GitHub
Neste guia de início rápido, você usará os serviços de Fala e Linguagem para reconhecer intenções de dados de áudio capturados de um microfone. Especificamente, você usará o serviço de Fala para reconhecer a fala e um modelo de Compreensão de Linguagem Conversacional (CLU) para identificar intenções.
Importante
O Entendimento de Linguagem de Conversação (CLU) está disponível para C# e C++ com o SDK de Fala versão 1.25 ou posterior.
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de idioma no portal do Azure.
- Obtenha a chave de recurso de idioma e o ponto de extremidade. Depois que o recurso de idioma for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
O SDK de fala está disponível como um pacote NuGet e implementa o .NET Standard 2.0. Você instala o SDK de fala mais adiante neste guia, mas primeiro verifique o guia de instalação do SDK para obter mais requisitos.
Definir variáveis de ambiente
Este exemplo requer variáveis de ambiente denominadas LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYe SPEECH_REGION.
Seu aplicativo deve ser autenticado para acessar os recursos de serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a
LANGUAGE_KEYvariável de ambiente, substituayour-language-keypor uma das chaves do seu recurso. - Para definir a
LANGUAGE_ENDPOINTvariável de ambiente, substituayour-language-endpointpor uma das regiões do seu recurso. - Para definir a
SPEECH_KEYvariável de ambiente, substituayour-speech-keypor uma das chaves do seu recurso. - Para definir a
SPEECH_REGIONvariável de ambiente, substituayour-speech-regionpor uma das regiões do seu recurso.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Nota
Se você só precisar acessar a variável de ambiente no console em execução atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas em execução que precisarão ler a variável de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Criar um projeto de Compreensão de Linguagem de Conversação
Depois de criar um recurso de linguagem, crie um projeto de compreensão de linguagem conversacional no Language Studio. Um projeto é uma área de trabalho para criar seus modelos de ML personalizados com base em seus dados. O seu projeto só pode ser acedido por si e por outras pessoas que tenham acesso ao recurso linguístico que está a ser utilizado.
Aceda ao Language Studio e inicie sessão com a sua conta do Azure.
Criar um projeto de compreensão de linguagem conversacional
Para este início rápido, você pode baixar este projeto de automação residencial de exemplo e importá-lo. Este projeto pode prever os comandos pretendidos a partir da entrada do usuário, como ligar e desligar luzes.
Na seção Compreender perguntas e linguagem conversacional do Language Studio, selecione Compreensão de linguagem conversacional.
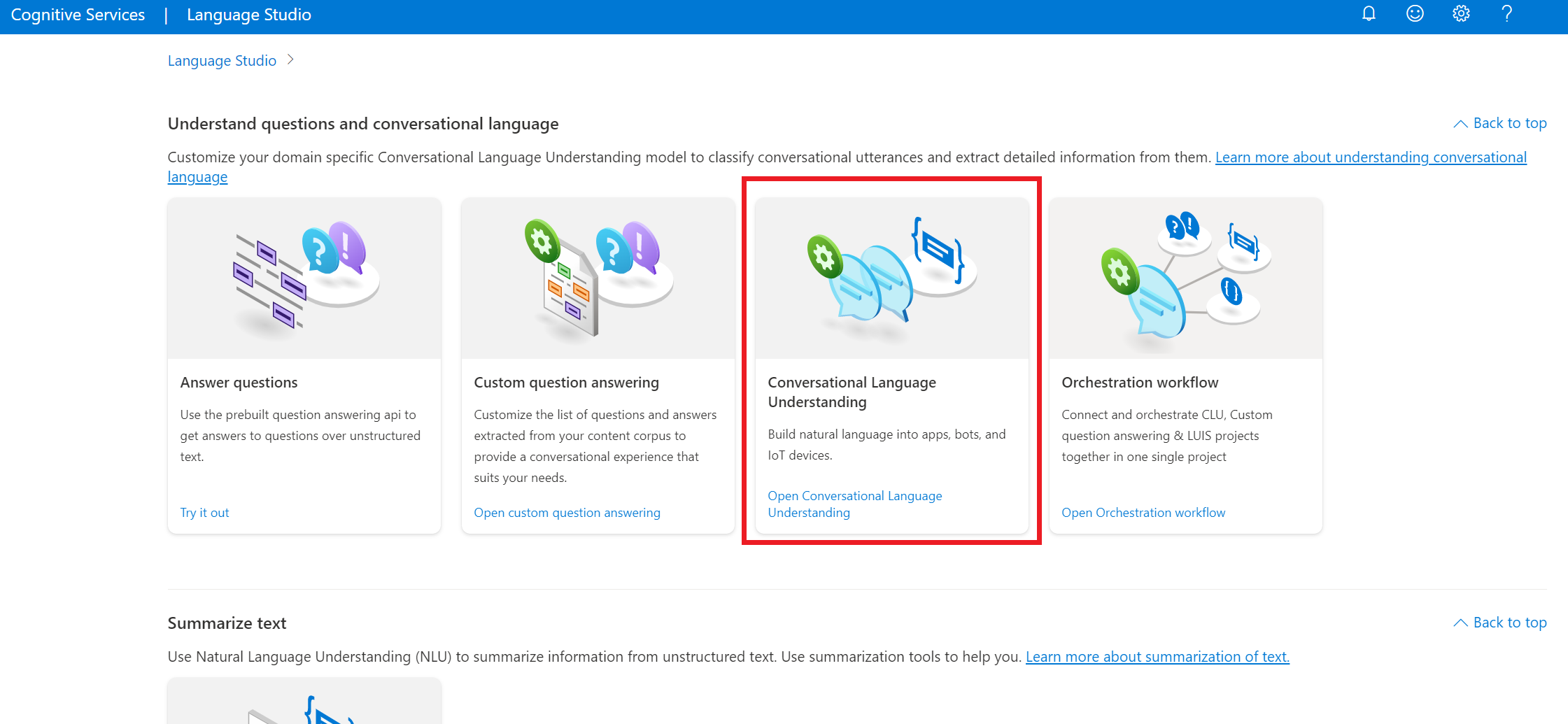
Isso levará você à página Projetos de compreensão de linguagem conversacional. Ao lado do botão Criar novo projeto, selecione Importar.
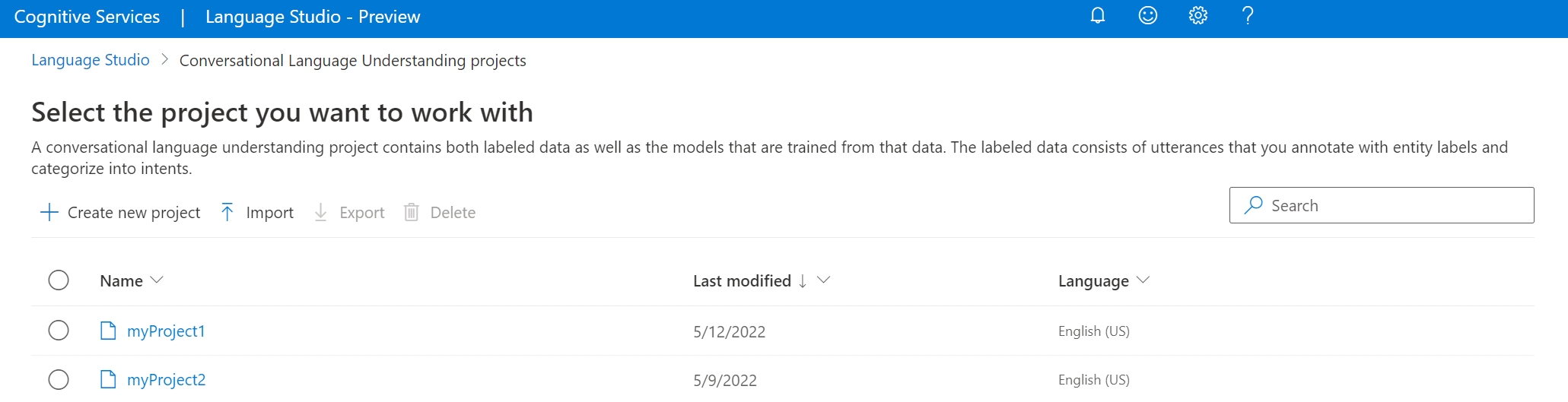
Na janela apresentada, carregue o ficheiro JSON que pretende importar. Certifique-se de que o ficheiro segue o formato JSON suportado.


Quando o upload estiver concluído, você pousará na página de definição de esquema. Para esse início rápido, o esquema já está construído e os enunciados já estão rotulados com intenções e entidades.
Preparar o modelo
Normalmente, depois de criar um projeto, você deve criar um esquema e rotular enunciados. Para este início rápido, já importamos um projeto pronto com esquema construído e enunciados rotulados.
Para treinar um modelo, você precisa começar um trabalho de treinamento. O resultado de um trabalho de treinamento bem-sucedido é o seu modelo treinado.
Para começar a treinar o seu modelo a partir do Language Studio:
Selecione Modelo de trem no menu do lado esquerdo.
Selecione Iniciar um trabalho de treinamento no menu superior.
Selecione Treinar um novo modelo e insira um novo nome de modelo na caixa de texto. Caso contrário, para substituir um modelo existente por um modelo treinado nos novos dados, selecione Substituir um modelo existente e, em seguida, selecione um modelo existente. A substituição de um modelo treinado é irreversível, mas não afetará os modelos implantados até que você implante o novo modelo.
Selecione o modo de treinamento. Você pode escolher o treinamento padrão para treinamento mais rápido, mas ele só está disponível para inglês. Ou pode escolher a formação avançada, que é suportada para outras línguas e projetos multilingues, mas envolve tempos de formação mais longos. Saiba mais sobre os modos de preparação.
Selecione um método de divisão de dados. Você pode escolher Dividir automaticamente o conjunto de testes dos dados de treinamento, onde o sistema dividirá suas declarações entre os conjuntos de treinamento e teste, de acordo com as porcentagens especificadas. Ou você pode usar uma divisão manual de dados de treinamento e teste, essa opção só é habilitada se você tiver adicionado enunciados ao seu conjunto de teste quando rotulou seus enunciados.
Selecione o botão Trem .

Selecione o ID do trabalho de treinamento na lista. Será exibido um painel onde você pode verificar o progresso do treinamento, status do trabalho e outros detalhes para este trabalho.
Nota
- Apenas trabalhos de formação concluídos com sucesso gerarão modelos.
- O treinamento pode levar algum tempo entre alguns minutos e algumas horas com base na contagem de enunciados.
- Só pode ter um trabalho de preparação em execução de cada vez. Você não pode iniciar outros trabalhos de treinamento dentro do mesmo projeto até que o trabalho em execução seja concluído.
- O aprendizado de máquina usado para treinar modelos é atualizado regularmente. Para treinar em uma versão de configuração anterior, selecione Selecionar aqui para alterar na página Iniciar um trabalho de treinamento e escolha uma versão anterior.

Implementar o modelo
Geralmente, depois de treinar um modelo, você revisaria seus detalhes de avaliação. Neste início rápido, você apenas implantará seu modelo e o disponibilizará para experimentar no Language studio, ou poderá chamar a API de previsão.
Para implantar seu modelo a partir do Language Studio:
Selecione Implantando um modelo no menu do lado esquerdo.
Selecione Adicionar implantação para iniciar o assistente Adicionar implantação .
Selecione Criar um novo nome de implantação para criar uma nova implantação e atribuir um modelo treinado na lista suspensa abaixo. Caso contrário, você pode selecionar Substituir um nome de implantação existente para substituir efetivamente o modelo usado por uma implantação existente.
Nota
A substituição de uma implantação existente não requer alterações na chamada da API de Previsão, mas os resultados obtidos serão baseados no modelo recém-atribuído.
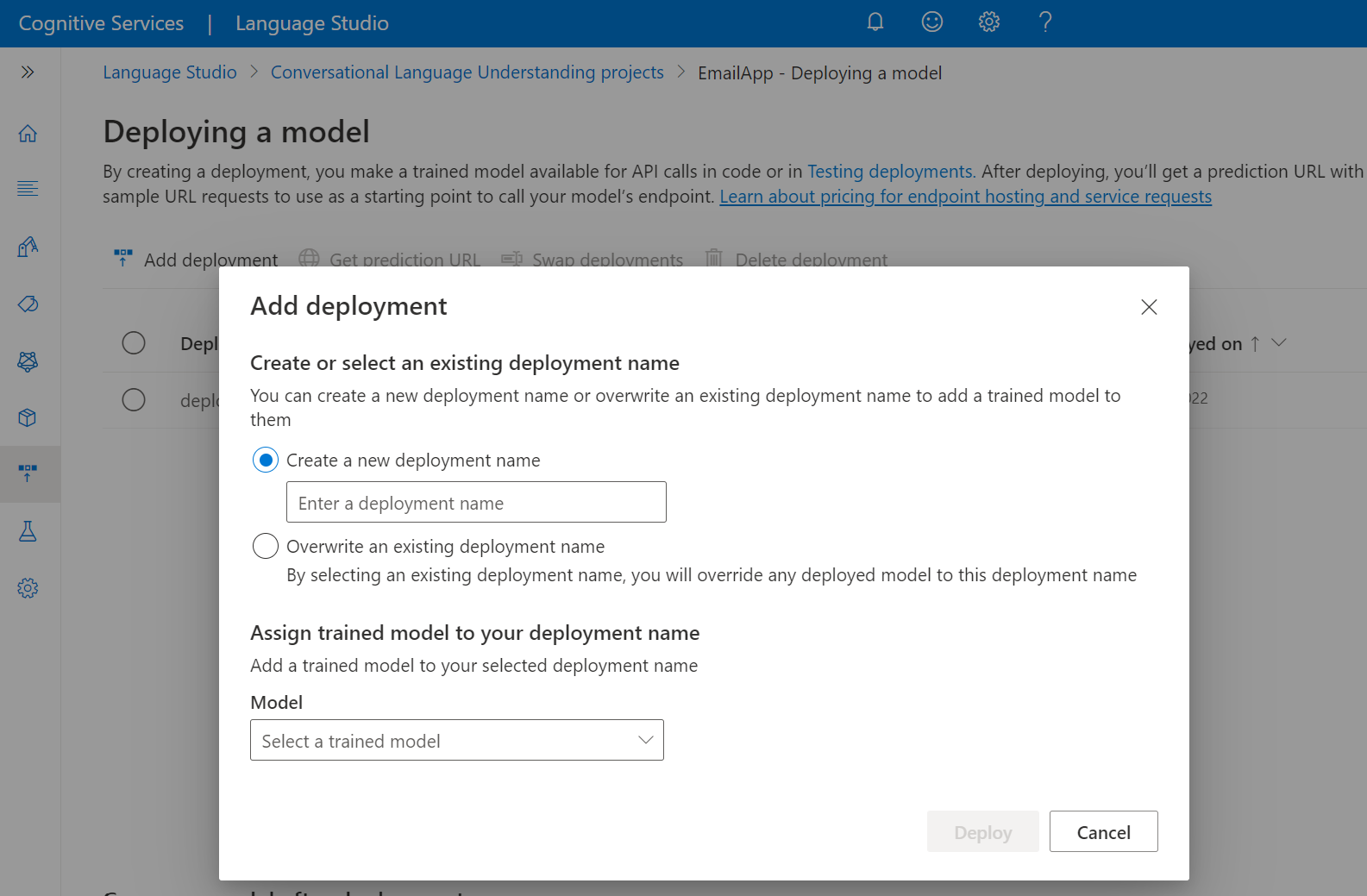
Selecione um modelo treinado na lista suspensa Modelo .
Selecione Implantar para iniciar o trabalho de implantação.
Depois que a implantação for bem-sucedida, uma data de expiração aparecerá ao lado dela. A expiração da implantação é quando o modelo implantado não estará disponível para ser usado para previsão, o que normalmente acontece doze meses após a expiração de uma configuração de treinamento.


Você usará o nome do projeto e o nome da implantação na próxima seção.
Reconhecer intenções a partir de um microfone
Siga estas etapas para criar um novo aplicativo de console e instalar o SDK de fala.
Abra um prompt de comando onde você deseja o novo projeto e crie um aplicativo de console com a CLI .NET. O
Program.csarquivo deve ser criado no diretório do projeto.dotnet new consoleInstale o SDK de fala em seu novo projeto com a CLI do .NET.
dotnet add package Microsoft.CognitiveServices.SpeechSubstitua o conteúdo do pelo código a
Program.csseguir.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }Em
Program.csdefina ascluProjectNamevariáveis ecluDeploymentNamepara os nomes do seu projeto e implantação. Para obter informações sobre como criar um projeto e implantação de CLU, consulte Criar um projeto de compreensão de linguagem conversacional.Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo,es-ESpara o espanhol (Espanha). O idioma padrão éen-USse você não especificar um idioma. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação do idioma.
Execute seu novo aplicativo de console para iniciar o reconhecimento de fala a partir de um microfone:
dotnet run
Importante
Certifique-se de definir as LANGUAGE_KEYvariáveis , LANGUAGE_ENDPOINT, SPEECH_KEYe SPEECH_REGION ambiente conforme descrito acima. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.
Fale ao microfone quando solicitado. O que você fala deve ser saída como texto:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Nota
O suporte para a resposta JSON para CLU por meio da propriedade LanguageUnderstandingServiceResponse_JsonResult foi adicionado no Speech SDK versão 1.26.
As intenções são retornadas na ordem de probabilidade do mais provável para o menos provável. Aqui está uma versão formatada da saída JSON onde o topIntent é HomeAutomation.TurnOn com uma pontuação de confiança de 0,97712576 (97,71%). A segunda intenção mais provável pode ser HomeAutomation.TurnOff com um índice de confiança de 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Observações
Agora que você concluiu o início rápido, aqui estão algumas considerações adicionais:
- Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o
RecognizeOnceAsyncsilêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz. - Para reconhecer a fala de um arquivo de áudio, use
FromWavFileInputem vez deFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Para arquivos de áudio compactado, como MP4, instale o GStreamer e use
PullAudioInputStreamouPushAudioInputStream. Para obter mais informações, consulte Como usar áudio de entrada compactada.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover os recursos de Idioma e Fala criados.
Pacote de documentação | de referência (NuGet) | Exemplos adicionais no GitHub
Neste guia de início rápido, você usará os serviços de Fala e Linguagem para reconhecer intenções de dados de áudio capturados de um microfone. Especificamente, você usará o serviço de Fala para reconhecer a fala e um modelo de Compreensão de Linguagem Conversacional (CLU) para identificar intenções.
Importante
O Entendimento de Linguagem de Conversação (CLU) está disponível para C# e C++ com o SDK de Fala versão 1.25 ou posterior.
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de idioma no portal do Azure.
- Obtenha a chave de recurso de idioma e o ponto de extremidade. Depois que o recurso de idioma for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
O SDK de fala está disponível como um pacote NuGet e implementa o .NET Standard 2.0. Você instala o SDK de fala mais adiante neste guia, mas primeiro verifique o guia de instalação do SDK para obter mais requisitos.
Definir variáveis de ambiente
Este exemplo requer variáveis de ambiente denominadas LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYe SPEECH_REGION.
Seu aplicativo deve ser autenticado para acessar os recursos de serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a
LANGUAGE_KEYvariável de ambiente, substituayour-language-keypor uma das chaves do seu recurso. - Para definir a
LANGUAGE_ENDPOINTvariável de ambiente, substituayour-language-endpointpor uma das regiões do seu recurso. - Para definir a
SPEECH_KEYvariável de ambiente, substituayour-speech-keypor uma das chaves do seu recurso. - Para definir a
SPEECH_REGIONvariável de ambiente, substituayour-speech-regionpor uma das regiões do seu recurso.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Nota
Se você só precisar acessar a variável de ambiente no console em execução atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas em execução que precisarão ler a variável de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Criar um projeto de Compreensão de Linguagem de Conversação
Depois de criar um recurso de linguagem, crie um projeto de compreensão de linguagem conversacional no Language Studio. Um projeto é uma área de trabalho para criar seus modelos de ML personalizados com base em seus dados. O seu projeto só pode ser acedido por si e por outras pessoas que tenham acesso ao recurso linguístico que está a ser utilizado.
Aceda ao Language Studio e inicie sessão com a sua conta do Azure.
Criar um projeto de compreensão de linguagem conversacional
Para este início rápido, você pode baixar este projeto de automação residencial de exemplo e importá-lo. Este projeto pode prever os comandos pretendidos a partir da entrada do usuário, como ligar e desligar luzes.
Na seção Compreender perguntas e linguagem conversacional do Language Studio, selecione Compreensão de linguagem conversacional.
Isso levará você à página Projetos de compreensão de linguagem conversacional. Ao lado do botão Criar novo projeto, selecione Importar.
Na janela apresentada, carregue o ficheiro JSON que pretende importar. Certifique-se de que o ficheiro segue o formato JSON suportado.
Quando o upload estiver concluído, você pousará na página de definição de esquema. Para esse início rápido, o esquema já está construído e os enunciados já estão rotulados com intenções e entidades.
Preparar o modelo
Normalmente, depois de criar um projeto, você deve criar um esquema e rotular enunciados. Para este início rápido, já importamos um projeto pronto com esquema construído e enunciados rotulados.
Para treinar um modelo, você precisa começar um trabalho de treinamento. O resultado de um trabalho de treinamento bem-sucedido é o seu modelo treinado.
Para começar a treinar o seu modelo a partir do Language Studio:
Selecione Modelo de trem no menu do lado esquerdo.
Selecione Iniciar um trabalho de treinamento no menu superior.
Selecione Treinar um novo modelo e insira um novo nome de modelo na caixa de texto. Caso contrário, para substituir um modelo existente por um modelo treinado nos novos dados, selecione Substituir um modelo existente e, em seguida, selecione um modelo existente. A substituição de um modelo treinado é irreversível, mas não afetará os modelos implantados até que você implante o novo modelo.
Selecione o modo de treinamento. Você pode escolher o treinamento padrão para treinamento mais rápido, mas ele só está disponível para inglês. Ou pode escolher a formação avançada, que é suportada para outras línguas e projetos multilingues, mas envolve tempos de formação mais longos. Saiba mais sobre os modos de preparação.
Selecione um método de divisão de dados. Você pode escolher Dividir automaticamente o conjunto de testes dos dados de treinamento, onde o sistema dividirá suas declarações entre os conjuntos de treinamento e teste, de acordo com as porcentagens especificadas. Ou você pode usar uma divisão manual de dados de treinamento e teste, essa opção só é habilitada se você tiver adicionado enunciados ao seu conjunto de teste quando rotulou seus enunciados.
Selecione o botão Trem .
Selecione o ID do trabalho de treinamento na lista. Será exibido um painel onde você pode verificar o progresso do treinamento, status do trabalho e outros detalhes para este trabalho.
Nota
- Apenas trabalhos de formação concluídos com sucesso gerarão modelos.
- O treinamento pode levar algum tempo entre alguns minutos e algumas horas com base na contagem de enunciados.
- Só pode ter um trabalho de preparação em execução de cada vez. Você não pode iniciar outros trabalhos de treinamento dentro do mesmo projeto até que o trabalho em execução seja concluído.
- O aprendizado de máquina usado para treinar modelos é atualizado regularmente. Para treinar em uma versão de configuração anterior, selecione Selecionar aqui para alterar na página Iniciar um trabalho de treinamento e escolha uma versão anterior.
Implementar o modelo
Geralmente, depois de treinar um modelo, você revisaria seus detalhes de avaliação. Neste início rápido, você apenas implantará seu modelo e o disponibilizará para experimentar no Language studio, ou poderá chamar a API de previsão.
Para implantar seu modelo a partir do Language Studio:
Selecione Implantando um modelo no menu do lado esquerdo.
Selecione Adicionar implantação para iniciar o assistente Adicionar implantação .
Selecione Criar um novo nome de implantação para criar uma nova implantação e atribuir um modelo treinado na lista suspensa abaixo. Caso contrário, você pode selecionar Substituir um nome de implantação existente para substituir efetivamente o modelo usado por uma implantação existente.
Nota
A substituição de uma implantação existente não requer alterações na chamada da API de Previsão, mas os resultados obtidos serão baseados no modelo recém-atribuído.
Selecione um modelo treinado na lista suspensa Modelo .
Selecione Implantar para iniciar o trabalho de implantação.
Depois que a implantação for bem-sucedida, uma data de expiração aparecerá ao lado dela. A expiração da implantação é quando o modelo implantado não estará disponível para ser usado para previsão, o que normalmente acontece doze meses após a expiração de uma configuração de treinamento.
Você usará o nome do projeto e o nome da implantação na próxima seção.
Reconhecer intenções a partir de um microfone
Siga estas etapas para criar um novo aplicativo de console e instalar o SDK de fala.
Crie um novo projeto de console C++ no Visual Studio Community 2022 chamado
SpeechRecognition.Instale o SDK de fala em seu novo projeto com o gerenciador de pacotes NuGet.
Install-Package Microsoft.CognitiveServices.SpeechSubstitua o conteúdo do
SpeechRecognition.cpppelo seguinte código:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Em
SpeechRecognition.cppdefina ascluProjectNamevariáveis ecluDeploymentNamepara os nomes do seu projeto e implantação. Para obter informações sobre como criar um projeto e implantação de CLU, consulte Criar um projeto de compreensão de linguagem conversacional.Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo,es-ESpara o espanhol (Espanha). O idioma padrão éen-USse você não especificar um idioma. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação do idioma.
Crie e execute seu novo aplicativo de console para iniciar o reconhecimento de fala a partir de um microfone.
Importante
Certifique-se de definir as LANGUAGE_KEYvariáveis , LANGUAGE_ENDPOINT, SPEECH_KEYe SPEECH_REGION ambiente conforme descrito acima. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.
Fale ao microfone quando solicitado. O que você fala deve ser saída como texto:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Nota
O suporte para a resposta JSON para CLU por meio da propriedade LanguageUnderstandingServiceResponse_JsonResult foi adicionado no Speech SDK versão 1.26.
As intenções são retornadas na ordem de probabilidade do mais provável para o menos provável. Aqui está uma versão formatada da saída JSON onde o topIntent é HomeAutomation.TurnOn com uma pontuação de confiança de 0,97712576 (97,71%). A segunda intenção mais provável pode ser HomeAutomation.TurnOff com um índice de confiança de 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Observações
Agora que você concluiu o início rápido, aqui estão algumas considerações adicionais:
- Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o
RecognizeOnceAsyncsilêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz. - Para reconhecer a fala de um arquivo de áudio, use
FromWavFileInputem vez deFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Para arquivos de áudio compactado, como MP4, instale o GStreamer e use
PullAudioInputStreamouPushAudioInputStream. Para obter mais informações, consulte Como usar áudio de entrada compactada.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover os recursos de Idioma e Fala criados.
Documentação | de referência Exemplos adicionais no GitHub
O Speech SDK for Java não suporta reconhecimento de intenção com compreensão de linguagem conversacional (CLU). Selecione outra linguagem de programação ou a referência Java e exemplos vinculados desde o início deste artigo.