Turbo boost data loads from Spark using SQL Spark connector
Reviewed by: Dimitri Furman, Xiaochen Wu
Apache Spark is a distributed processing framework commonly found in big data environments. Spark is often used to transform, manipulate, and aggregate data. This data often lands in a database serving layer like SQL Server or Azure SQL Database, where it is consumed by dashboards and other reporting applications. Prior to the release of the SQL Spark connector, access to SQL databases from Spark was implemented using the JDBC connector, which gives the ability to connect to several relational databases. However, compared to the SQL Spark connector, the JDBC connector isn’t optimized for data loading, and this can substantially affect data load throughput.
As an example, utilizing the SQLBulkCopy API that the SQL Spark connector uses, dv01, a financial industry customer, was able to achieve 15X performance improvements in their ETL pipeline, loading millions of rows into a columnstore table that is used to provide analytical insights through their application dashboards.
In this blog, we will describe several experiments that demonstrate the major performance improvement provided by the SQL Spark connector.
You can download the SQL Spark Connector here
Dataset
Dataset size: 117 million rows
Source: Azure Blob Storage containing 50 parquet files.
Spark Cluster: 8+1 node cluster, each node is a DS3V2 Azure VM (4 cores, 17 GB RAM)
Scenario 1: Loading data into SQL Server
SQL Version: SQL Server 2017 CU 5 on RedHat 7.4
Azure VM Size: DS16sV3 (16 cores, 64 GB RAM)
Storage: 8 P30 disks in Azure Blob Storage
Database Recovery Model: Simple
Performance in SQL on windows v/s SQL on Linux is comparable and for brevity we only depict results on SQL Server on Linux.
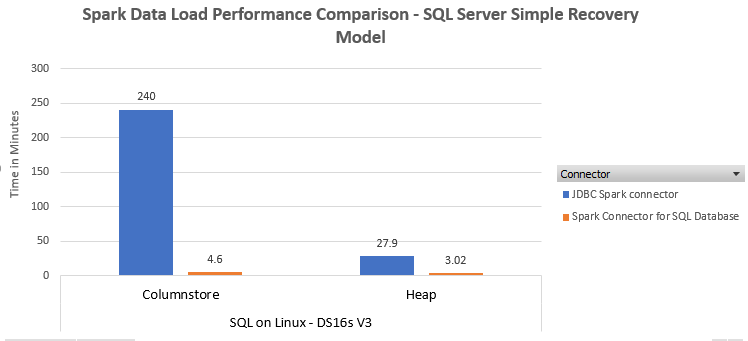
Loading into a heap
Using Spark JDBC connector
Here is a snippet of the code to write out the Data Frame when using the Spark JDBC connector. We used the batch size of 200,000 rows. Changing the batch size to 50,000 did not produce a material difference in performance.
[code lang="scala"]
dfOrders.write.mode("overwrite").format("jdbc")
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.option("url", "jdbc:sqlserver://server.westus.cloudapp.azure.com;databaseName=TestDB")
.option("dbtable", "TestDB.dbo.orders")
.option("user", "myuser")
.option("batchsize","200000")
.option("password", "MyComplexPassword!001")
.save()
Since the load was taking longer than expected, we examined the sys.dm_exec_requests DMV while load was running, and saw that there was a fair amount of latch contention on various pages, which wouldn’t not be expected if data was being loaded via a bulk API.
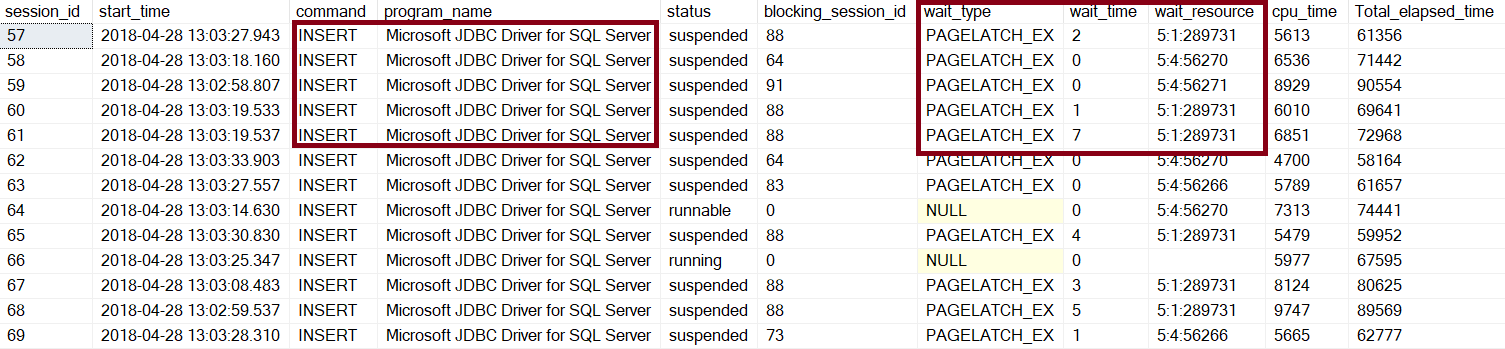
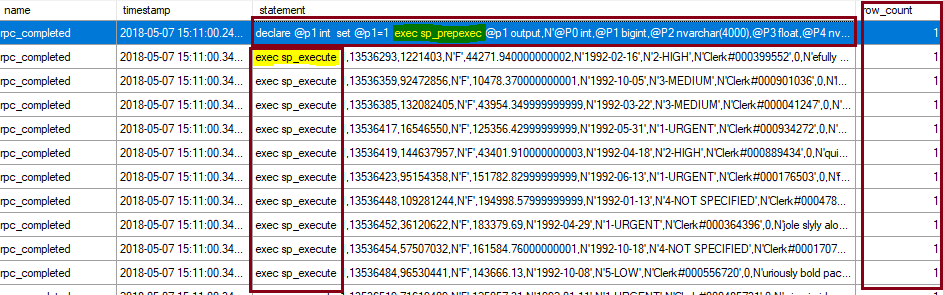
Examining the statements being executed, we saw that the JDBC driver uses sp_prepare followed by sp_execute for each inserted row; therefore, the operation is not a bulk insert. One can further example the Spark JDBC connector source code, it builds a batch consisting of singleton insert statements, and then executes the batch via the prep/exec model.
This is an 8-node Spark cluster, each executor with 4 CPU’s and due to sparks default parallelism, there were 32 tasks running simultaneously with multiple insert statements batched together. The primary contention was PAGELATCH_EX and just like any latch contention the more parallel sessions requesting for the same resource, the more the contention.

Using SQL Spark connector
The SQL Spark connector also uses the Microsoft JDBC driver. However, unlike the Spark JDBC connector, it specifically uses the JDBC SQLServerBulkCopy class to efficiently load data into a SQL Server table. Given that in this case the table is a heap, we also use the TABLOCK hint ( "bulkCopyTableLock" -> "true") in the code below to enable parallel streams to be able to bulk load, as discussed here. It is a best practice to use the BulkCopyMetadata class to define the structure of the table. Otherwise, there is additional overhead querying the database to determine table schema.
[code lang="scala"]
import com.microsoft.azure.sqldb.spark.config._
import com.microsoft.azure.sqldb.spark.connect._
import com.microsoft.azure.sqldb.spark.query._
import com.microsoft.azure.sqldb.spark._
import com.microsoft.azure.sqldb.spark.bulkcopy._
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "o_orderkey", java.sql.Types.INTEGER, 0, 0)
bulkCopyMetadata.addColumnMetadata(2, "o_custkey", java.sql.Types.INTEGER, 0, 0)
//trimming other columns for brevity… only showing the first 2 columns being added to BulkCopyMetadata
val bulkCopyConfig = Config(Map(
"url" -> "server.westus.cloudapp.azure.com",
"databaseName" -> "testdb",
"user" -> "denzilr",
"password" -> "MyComplexPassword1!",
"dbTable" -> "dbo.orders",
"bulkCopyBatchSize" -> "200000",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
dfOrders.bulkCopyToSqlDB(bulkCopyConfig)
Looking at the Spark UI, we see a total of 50 tasks that this DataFrame write is broken into, each loading a subset of the data:
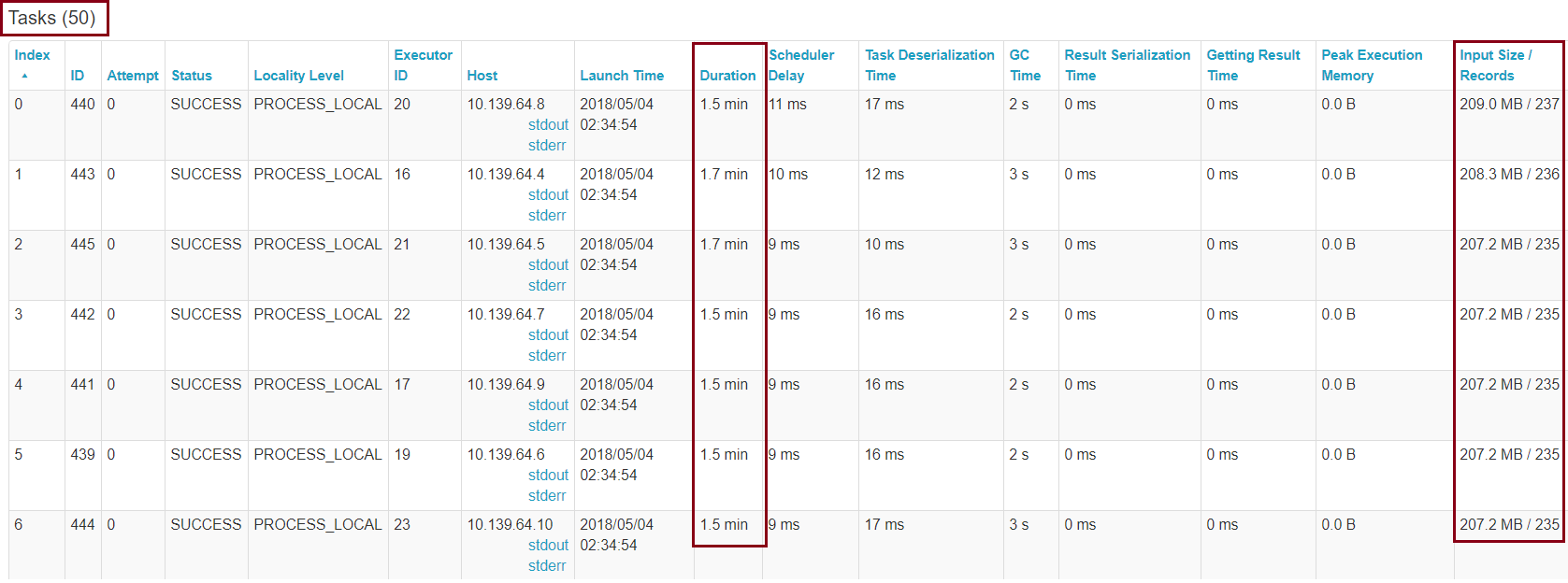
Further investigating the statements, we see the familiar INSERT BULK statement, which is an internal statement used by the SQL Server bulk load APIs. This proves that we are indeed using the 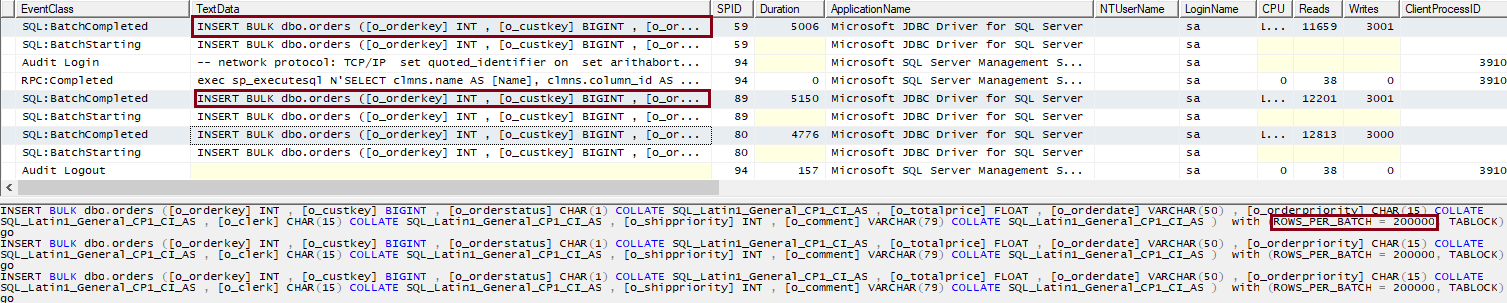 SQLBulkCopy API.
SQLBulkCopy API.
There is no longer page latch contention, rather now we are waiting on network IO or client fetching the results

Loading into a clustered columnstore table
With JDBC connector
Load performance in the columnstore case will be far worse with the JDBC connector than in the heap case. Given that the JDBC connector emits single row insert statements, all this data lands in the delta store. And we are back with more severe latch contention this time around. You can read about many more details of loading data into columnstore tables in this blog 😊.
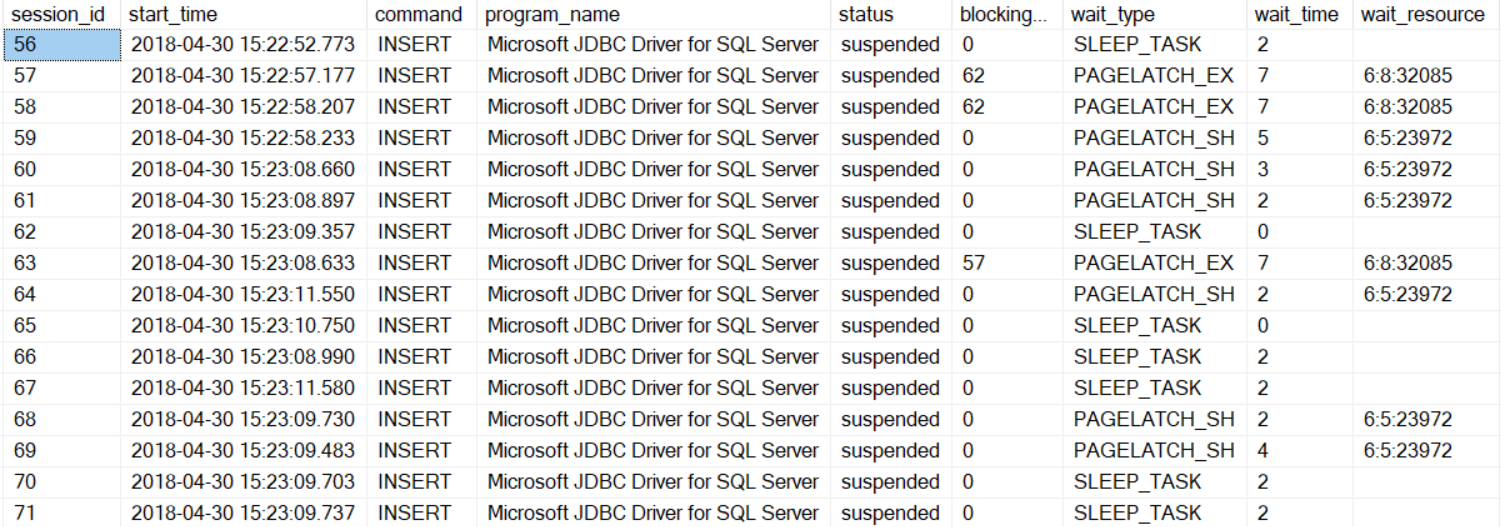
If we examine the sys.dm_db_column_store_index_physical_stats DMV, we notice that all rows are going into an OPEN rowgroup that is a delta store until that rowgroup is filled up and closed. These rows will then have to be compressed by tuple mover into compressed segments later.

Using SQL Spark connector
For the bulk load into clustered columnstore table, we adjusted the batch size to 1048576 rows, which is the maximum number of rows per rowgroup, to maximize compression benefits. Having batch size > 102400 rows enables the data to go into a compressed rowgroup directly, bypassing the delta store. Also, you have to set TABLOCK hint to false, else you will be serializing the parallel streams.
[code lang="scala"]
import com.microsoft.azure.sqldb.spark.config._
import com.microsoft.azure.sqldb.spark.connect._
import com.microsoft.azure.sqldb.spark.query._
import com.microsoft.azure.sqldb.spark._
import com.microsoft.azure.sqldb.spark.bulkcopy._
val bulkCopyConfig = Config(Map(
"url" -> "server.westus.cloudapp.azure.com",
"databaseName" -> "testdb",
"user" -> "denzilr",
"password" -> "MyComplexPassword1!",
"dbTable" -> "dbo.orders",
"bulkCopyBatchSize" -> "1048576",
"bulkCopyTableLock" -> "false",
"bulkCopyTimeout" -> "600"
))
dfOrders.bulkCopyToSqlDB(bulkCopyConfig)
When bulk loading in parallel into a columnstore table, there are a few considerations:
- Memory grants and RESOURCE_SEMAPHORE waits. Depending on how many parallel streams, you could run into this issue, and it could end up bulk inserting into delta row groups. For more information, see this blog.
- Compressed rowgroups could be trimmed due to memory pressure. You would see the trim_reason_description column in the sys.dm_db_column_store_row_group_physical_stats DMV as “MEMORY_LIMITATION”.
In this case, you see that rows land in the compressed rowgroup directly. We had 32 parallel streams going against a DS16sV3 VM (64GB Ram). There are cases where having too many parallel streams, as a result of memory requirements for a bulk insert can cause rowgroups to get trimmed due to memory limitations.

Scenario 2: Loading data into Azure SQL Database
SQL version: Azure SQL Database
Database performance level: P11
There are a couple of differences that need to be noted, which make the Azure SQL Database tests fundamentally different than the tests with SQL Server on a VM.
- Database recovery model is Full, vs. Simple recovery model that was used with SQL Server in VM. This prevents the use of minimal logging in Azure SQL Database.
- P11 is a Premium database, therefore it is in an availability group used to provide built-in HA within the service. This adds an overhead of committing every transaction on multiple replicas.
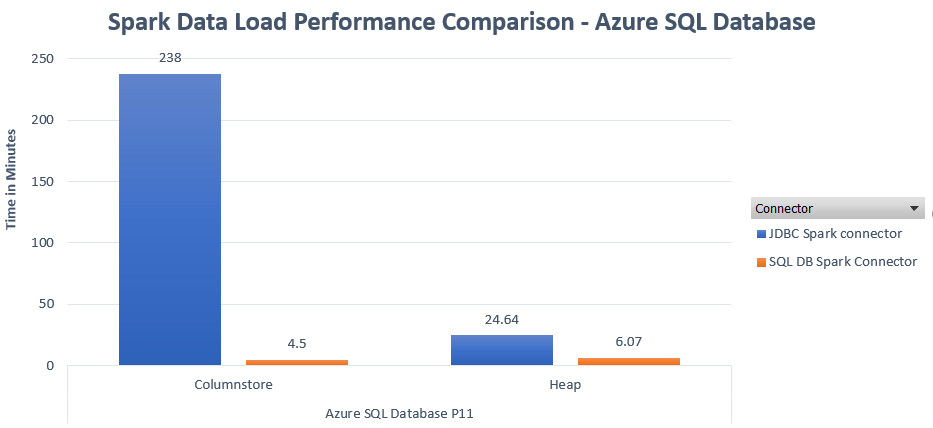
When loading into Azure SQL Database, depending on the performance level of the database, you may see other wait types such as LOG_RATE_GOVERNOR, which would be an indicator of a bottleneck. There are multiple ways to monitor resource utilization in Azure SQL Database to detect resource bottleneck, e.g. the sys.dm_db_resource_stats DMV. If a resource bottleneck exists, the database can be easily scaled up to a higher performance level to achieve higher throughput during data loads. More on Azure SQL Database monitoring can be found here.

Recapping a few considerations relevant to data loading from Spark into SQL Server or Azure SQL Database:
- Use the Spark SQL connector. We have just shown that in the bulk insert scenario, we get fundamentally better performance, by an order of magnitude, than with the Spark JDBC connector.
- For tables that are heaps, use the TABLOCK hint to allow parallel streams. This is particularly relevant for staging tables, which tend to be heaps.
- For bulk loads into columnstore tables, do not use the TABLOCK hint, as that would serialize parallel streams.
- For bulk loads into columnstore tables, ensure that batch size is >= 102400 so that row go directly into a compressed rowgroup. Ideally start with the batch size of 1048576
- For partitioned tables, see the section on partitioned tables in the Data Loading performance considerations with Clustered Columnstore indexes Depending on the number of rows per partition, they could land in the delta store, which would affect bulk insert performance.