Checkpoint process for memory-optimized tables in SQL 2016 and implications on the log
Reviewed by: Alejandro Saenz, Jos de Bruijn; Joe Sack, Mike Weiner,Kun Cheng, Raghavendra TK
A durable memory-optimized table (created as SCHEMA_AND_DATA) will have it’s transactions recorded into the transaction log so that on failure, recovery is possible. This logging ensures the durability of the transactions. Unlike disk-based tables, memory-optimized tables do not use WAL ( write-ahead logging) protocol, transactions are written to the log only on a commit and dirty data is never written to disk.
The checkpoint process is a background process used by SQL Server to ensure that in the event of a crash, the time it takes to recover isn’t very long.
Checkpoints for disk-based tables
A checkpoint for disk-based tables will result in flushing dirty pages to disk and in the simple recovery model the log will also be truncated. For disk-based tables, the database engine supports automatic, indirect and manual checkpoints. Automatic checkpoints for disk-based tables are based on the recovery interval configuration option. In addition, with SQL Server 2016, the default on newly created databases is to have “indirect” checkpoint enabled which shortens that recovery time period.
Checkpoints for memory optimized tables
For memory-optimized tables, the checkpoint process flushes both the data streams that contain all new versions of records and the delta stream that contains deleted versions of records to data and delta files. Each pair of data/delta files constitutes a checkpoint file pair or CFP and these files have the extensions .hkckp. All the data/delta files are written to sequentially or as streaming IO rather than random IO. To prevent the files from growing indefinitely , the checkpoint process will also do a “merge” if it is possible to merge subsequent checkpoint file pairs that have been closed.

Checkpoint behavior differences with memory-optimized tables
Checkpoint for memory optimized tables is done by a background worker thread in the In-Memory OLTP engine which is separate than the checkpoint thread for disk-based tables. Automatic checkpoint for memory-optimized tables will execute based on the following condition:
- If the log has produced 1.5 GB since the last checkpoint, this will trigger the Engine to checkpoint memory optimized tables.
This difference in behavior in checkpoint can cause confusion with regards when the log is purged when you have memory optimized tables. For disk based tables, the log is truncated on a log backup for full recovery model or an automatic checkpoint for a database in simple recovery mode. This changes when we have a memory optimized table, a transaction log backup doesn’t necessarily truncate the log until the thresholds specified above are met.
Of course, at any time though, a manual checkpoint command can be issued.
Also, with SQL Server 2016 there is a special case, based on the conditions below, which will vary the checkpoint characteristics for memory-optimized tables. This is referred to as the “Large checkpoint” process, which is enabled on larger machines if all of the following conditions are true
- The server has 16 or more logical processors
- The server has 128GB or greater memory.
- The server is capable of greater than 200MB/sec I/O measured for the IO subsystem of that database.
Details on this behavior are provided below in the section titled Large checkpoint for memory-optimized tables
Memory-optimized table checkpoint behavior example
Here is an example that shows what happens with checkpoints on memory-optimized tables. In summary we will:
- Create a database
- Establish the log chain by taking a backup
- Populate some data and commit, thereby growing the log
- Take a log backup
The expectation is that after the log backup, the log space used will be minimal unless there is some open transaction/ un-replicated transaction, or some other factors that prevents the log from being purged.
Example:
CREATE DATABASE [InMemoryOLTP]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'IMOLTP', FILENAME = N'c:\temp\InMemoryOLTP.mdf'),
FILEGROUP [IMOLTP_InMemory] CONTAINS MEMORY_OPTIMIZED_DATA DEFAULT
( NAME = N'IMOLTP_InMemory', FILENAME = N'c:\temp\InMemoryOLTP')
LOG ON
( NAME = N'IMOLTP_log', FILENAME = N'c:\temp\InMemoryOLTP_log.ldf')
GO
USE InMemoryOLTP
GO
CREATE TABLE dbo.SalesOrder_MemOpt
(
order_id int identity not null,
order_date datetime not null,
order_status tinyint not null,
amount float not null,
Constraint PK_SalesOrderID PRIMARY KEY NONCLUSTERED HASH (order_id) WITH (BUCKET_COUNT = 10000)
) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
-- Create Natively compiled procedure to speed up inserts.
CREATE PROCEDURE [dbo].[InsertSalesOrder_Native_Batch]
@order_status tinyint = 1,
@amount float = 100,
@OrderNum int = 100
WITH
NATIVE_COMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT,LANGUAGE = 'us_english')
declare @counter int = 1
WHILE @counter <= @OrderNum
BEGIN
INSERT INTO dbo.SalesOrder_MemOpt values(getdate(),@order_status,@amount)
SET @counter= @counter+1
END
END
GO
-- Create backup to start chain, don't need the backups
CHECKPOINT
go
BACKUP DATABASE InMemoryOLTP to disk = 'c:\temp\test.bak' WITH INIT,COMPRESSION
BACKUP LOG InMemoryOLTP to disk = 'c:\temp\test.bak' WITH COMPRESSION
GO
-- Check Log Space used column for DB
DBCC SQLPERF(logspace)
GO
-- Check Log Space, file checkpoint stats, file states
-- Do we have any reason why the log can't be purged?
SELECT log_reuse_wait_desc,*
FROM sys.databases
WHERE name = 'InMemoryOLTP'
GO
-- What percentage of the log is used for this DB?
DBCC sqlperf(logspace)
GO
-- How much log is generated since last checkpoint?
SELECT log_bytes_since_last_close /(1024*1024) as Log_bytes_since_last_close_mb,time_since_last_close_in_ms, current_checkpoint_id,*
FROM sys.dm_db_xtp_checkpoint_stats
GO
-- Have checkpoint files been flushed?
SELECT state_desc,
file_type_desc,
count(state_desc) count,
sum(file_size_in_bytes)/(1024*1024) file_size_in_mb_bytes,
Avg(file_size_in_bytes)/(1024*1024) Avgfile_size_in_mb_bytes
FROM sys.dm_db_xtp_checkpoint_files
GROUP BY state_desc, file_type_desc
ORDER BY file_size_in_mb_bytes desc
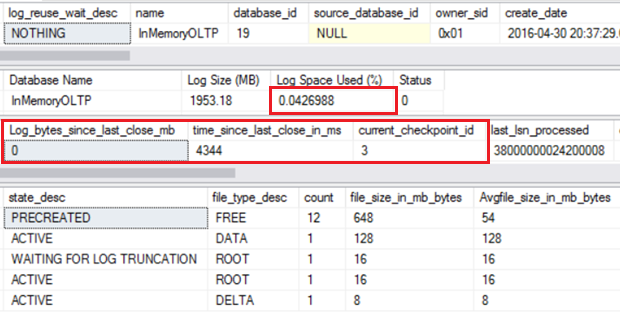
-- This proc inserts 900K rows 20 times
-- Attempt to grow the log to ~ 1GB
BEGIN TRAN
EXEC dbo.[InsertSalesOrder_Native_Batch] 1,100,900000
DELETE FROM dbo.SalesOrder_MemOpt WITH(SNAPSHOT)
COMMIT
GO 20
-- Backup the log
-- Do you expect the log to be purged?
BACKUP LOG InMemoryOLTP TO DISK = 'c:\temp\test.bak' WITH INIT,COMPRESSION
GO
As shown below, we have ~ 1GB of Log generated since last checkpoint, and after the backup log, the log spaced used % is still at 51%, and there is 1 active data file only which indicates the data/delta file stream has not been flushed to disk given this was a new database. 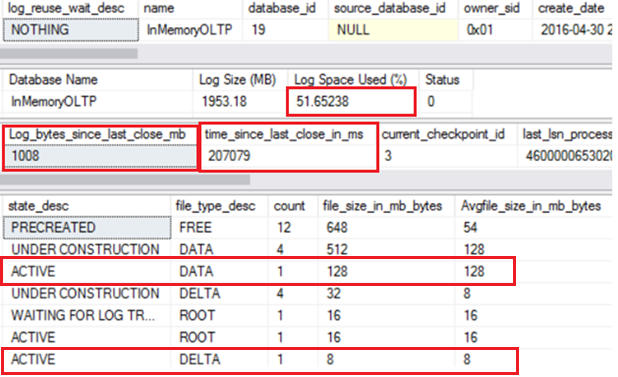
Now when we issue a manual checkpoint, the active files go up to 5 as data/delta files are flushed, and log bytes since last checkpoint go to 0. However, the log spaced used is still at 51% as we are in full recovery model and a backup log will free that up.
-- Manual checkpoint
CHECKPOINT
GO
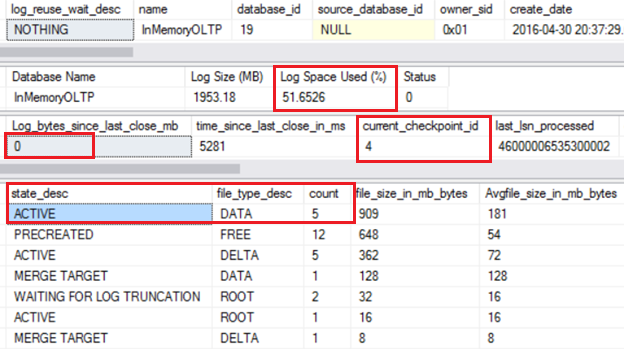
After the backup the Log space used drops to minimal amount as expected.
-- Backup to Free up the log
BACKUP LOG InMemoryOLTP to DISK = 'c:\temp\test.bak' WITH INIT, COMPRESSION
GO
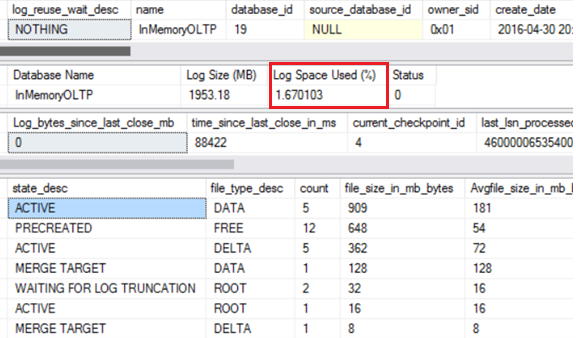
Had we waited until 1.5 GB of Log was filled up, no manual checkpoint would have to be issued and the log would be purged based on the size based threshold.
Large checkpoint for memory-optimized tables
Large checkpoints were designed for high throughput systems with very high log generation rates of up-to 1GB/sec. The purpose is to ensure that the checkpoint process would not be continually executing and would scale efficiently.
In the SQL error log, you will see messages indicating that we have detected that is a larger machine and as such by default “Large checkpoints” are used.
2016-04-29 21:03:58.080 Server SQL Server detected 4 sockets with 8 cores per socket and 16 logical processors per socket, 64 total logical processors; using 64 logical processors based on SQL Server licensing. This is an informational message; no user action is required.
…
2016-04-29 21:03:58.080 Server Detected 1048541 MB of RAM. This is an informational message; no user action is required.
…
2016-04-29 21:04:00.110 Server In-Memory OLTP initialized on highend machine.
With Large checkpoints enabled, there are the following behavior changes:
- Data files created are now 1GB and delta files are 128MB instead of the smaller 128MB/16MB sizes.
- Automatic checkpoints are executed when 12 GB of the log is filled up since the last checkpoint.
Given this new behavior with SQL Server 2016, there are a few scenarios to consider where large checkpoints do have ramifications:
- In particular, on test systems where a workload may be executed and then paused at some point (not continuous workload running) you may notice that on small databases you can have 5GB of FREE files pre-created on disk and 12GB of log not cleared even after a log backup.
- There is the potential big increase in the recovery time if a crash occurs with lots of log between checkpoints. In the case of Large checkpoints, there could be up to 12GB of produced log between checkpoints that may need to be recovered on a failure.
The primary design point of large checkpoints was for the very high throughput systems with high log generation rate. If your average Log generation rate is less than 300MB/sec outside of short spikes, you do not need Large Checkpoints. In CU1, the default behavior has been changed and reverted back to not use Large Checkpoints. Fore more details see:
Comments
- Anonymous
May 22, 2016
Thanks for a great article -- You might want to clarify that the "1.5 GB since the last checkpoint" that triggers a checkpoint for memory-optimized tables does not have to be activity exclusively related to memory-optimized tables.- Anonymous
June 23, 2016
That is correct
- Anonymous