Windows Azure Storage性能调优(二)
上一篇我们提出的方法都是通过减少网络传输时间来提升性能。接下来,我会简介一下WAS的系统结构,然后解释如何设计程序来减少WAS端执行时间。
WAS架构
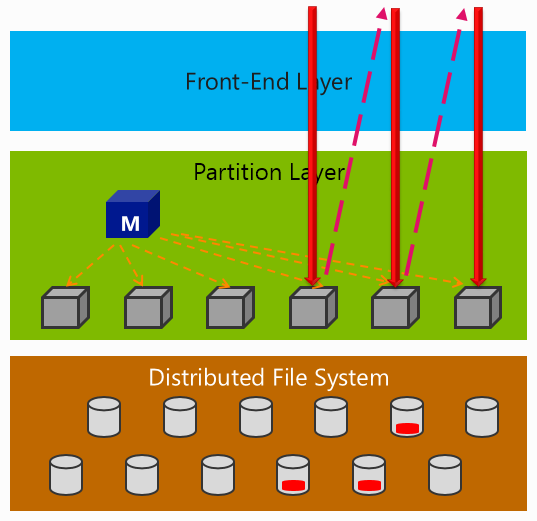
Windows Azure Storage是一个三层架构,分为前端(FE)、分区层(Partition)、分布式存储层(DFS)。
前端负责接受客户端HTTP(S)连接,验证身份,计费以及写日志。
分布式存储层为实际的物理存储。无论Blob,File,Queue还是Table,其最终都已Binary形式存放在此层。此层确保数据在三个独立的物理节点上保存备份,避免数据丢失。
分区层提供了逻辑数据结构的访问能力。它理解数据的逻辑抽象结构,能够按照用户的请求来正确存取DFS层数据。同时,分区层实现了跨数据中心的备份同步功能。

WAS的设计目标是存储海量数据,实现大并发访问。海量存储由分布式存储层来实现,而大并发的目标是如何实现的呢?
从物理存储来看,大并发的压力来自于磁盘I/O和网络带宽。在DFS层,数据的物理存储单位是Extent,100MB-1GB不等。每个对象(Blob,Table或Queue)都由一个或多个Extent拼接而,除此之外,数据还有三个备份。这些Extent离散分布在多台独立的服务器上,因此,用户对对象的访问被分摊在多台服务器上,以达到高吞吐量。
数据逻辑结构的处理需要耗费Memory和CPU资源。Partition层将逻辑数据拆分为多个Partitions,比如:每个Blob, Queue即为一个Partition,Table中PartitionKey相同的所有实体存放在一个Partition。Partition层每台服务器负责服务一组Partitions,Master服务器会检测每台服务器的负载,并动态调整Partitions的分配。由于所有数据都存放在DFS层,因此负载调整会非常迅速。通过动态负载均衡,Partition层确保有足够的资源来响应客户请求。
WAS性能目标
微软在MSDN上公布了WAS的性能目标,这些数据是WAS的性能上限,若用户使用WAS超过指标时,WAS会返回给客户503(Server Busy)或500(Operation Timeout)。当用户接到此类错误时,建议用户采用回退的方式重试操作,这样可以缓解短暂高峰造成的WAS服务压力。
简要来说,性能目标有两层:Partition级和Storage Account级。Storage Account级的目标如下:
Total Account Capacity |
Total Request Rate (assuming 1KB object size) |
Total Bandwidth for a Geo-Redundant Storage Account |
Total Bandwidth for a Locally Redundant Storage Account |
500 TB |
Up to 20,000 entities or messages per second |
*Ingress: Up to 10 gigabits per second *Egress: Up to 20 gigabits per second |
*Ingress: Up to 20 gigabits per second *Egress: Up to 30 gigabits per second |
* Ingress refers to all data (requests) being sent to a storage account.
* Egress refers to all data (responses) being received from a storage account.
Partition级别的性能目标为:
Target Throughput for Single Blob |
Target Throughput for Single Queue (1 KB messages) |
Target Throughput for Single Table Partition (1 KB entities) |
Up to 60 MB per second, or up to 500 requests per second |
Up to 2000 messages per second |
Up to 2000 entities per second |
若要了解更多细节,可以访问如下官方文档
https://msdn.microsoft.com/en-us/library/azure/dn249410.aspx
分散工作负载
了解到WAS的性能目标后,开发者在设计时就要尽量避免达到性能上限。
举个实例。两个Role通过WAS Queue来做消息中转,消息吞吐量在高峰时段可能达到10K,那么如果设计人员只使用单Queue,则Queue会成为性能瓶颈,无论增加多少Role虚拟机数量,吞吐量被始终限制在2000 messages/sec左右。解决方案就是使用多个Queue来分散工作负载。
同样的道理,用户要避免使用一个WAS Account来放置过多的虚拟机磁盘,否则有可能达到WAS Account级的性能上限20,000事务/s。建议每个WAS Account最多放置40块虚拟机磁盘。
避免Table热区
前面提到过,一个Table中PartitionKey相同的实体放置在同一个Partition里,而Partition的性能上限是2000实体访问/s。如果应用程序设计不当的话,有可能出现Table的某些Partition访问过于频繁,造成WAS响应慢或者报错(500,503)。举个具体的例子:一个日志系统,使用日期做PartitionKey,那么所有的写操作都会hit当日的Partition。如下通过测试,给大家一个直观的感觉。
场景: 一个博客系统,使用WAS Table来存储博客内容。现有两种设计:
设计1 : PartitionKey=date, RowKey=BlogThreadID+PostID
代码如下:

设计2 : PartitionKey=date+BlogThreadID, RowKey=PostID
代码和设计1类似,唯独修改了PartitionKey

两种设计保存的数据内容是一致的,只是PartitionKey和RowKey的格式不同。最终执行效率能有多大区别呢?我这里使用压力测试来检验,结果差别巨大!
设计1,随着用户负载增加,服务延迟越来越高,吞吐量维持在1380/s

设计2,随着用户负载增加,服务延迟平稳,而吞吐量达到了2600/s

可见,开发者在设计PartitionKey,RowKey时要避免Hot Partition,否则其造成的性能差距是巨大的。
设计2仍然存在问题:Partition按照PartitionKey字符串排序,编号相近的Partition很有可能被分配在同一台Partition服务器。设计2可能造成Partition服务器压力过载,从而影响WAS响应速度。为了提高性能,用户可以考虑倒置日期字符串来避免Partition集中。
优化Table查询
Table的实体有多个属性,通过筛选属性值,可以返回需要的实体。筛选条件的选择会直接影响查询效率。
数据库用户都知道索引能够避免扫描操作,减少I/O,从而提升效率。Table也支持索引,不过每个Table只有一个索引,即PartitionKey+RowKey。指定了PartitionKey和RowKey的查询叫做Point Query,他的查询效率也最高。
如果没有指定PartitionKey和RowKey,而是单单筛选其它属性,则查询退化为全表的扫描操作,效率会大大降低。不仅如此,之前WAS架构提到过,Table数据保存在多个Partition中,而Partitions分布在多台Partition服务器上。如果遍历的数据散布在多台服务器,则WAS会在遍历完一台Partition服务器后返回客户端一个Token,客户端凭Token来再次请求,WAS会将请求导向到下一个服务器,多次Roundtrip过程会耗费更多时间。
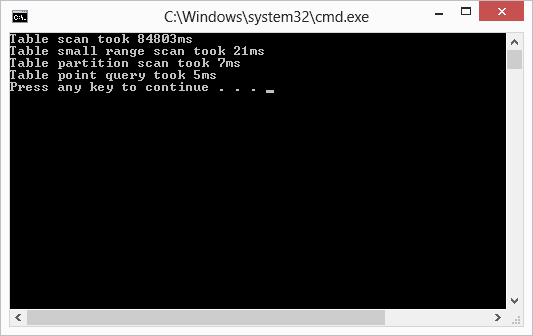
以访问WAD Table为例,我测试了用全表查询,局部范围查询,指定Partition查询和Point查询来搜索同一个实体。

结果表明PartitionKey 范围越小,查询速度就越快。
因此,用户的查询操作要尽量指定PartitionKey或者一个PartitionKey范围,避免大数据范围的扫描。而设计者需要根据业务需求考虑如何组合PartitionKey,使查询语句尽量多的使用到PartitionKey。
Table Storage 设计模式
最近微软公布了一份官方文档,列举了使用Azure Table Storage下的一些设计技巧,感兴趣的读者可以直接访问如下文档
https://azure.microsoft.com/en-us/documentation/articles/storage-table-design-guide/?rnd=1
