Mise en place d’une machine virtuelle dédiée à l’analyse de données – 3ième partie
Une première partie de ce billet nous a permis d'introduire la machine virtuelle « Data Science VM » mise à disposition par Microsoft sur le magasin en ligne Azure Marketplace, une seconde partie une première illustration de mise en œuvre des fonctionnalités ainsi offertes au travers de Power BI.
Cette troisième et dernière partie vous accompagne dans une analyse avancée via Jupyter.
J'en profite pour remercier très sincèrement Morgan Funtowicz actuellement en stage au sein de l'équipe, qui vous propose cette exploration.
Analyse avancée via Jupyter
Maintenant que vous avez eu un aperçu de la visualisation au travers de Power BI, je vous propose d'aller plus loin, en tentant maintenant de prédire la catégorie d'une iris en fonction de ces 4 dimensions ou variables (longueur des sépales, largeur des sépales, longueur des pétales, et largeur des pétales).
Pour ce faire, nous allons utiliser Jupyter via le langage Python afin d'extraire l'information et entrainer un modèle de prédiction capable de classer nos fleurs. Le code source utilisé est téléchargeable ici : iris_decision_tree.
Configuration de Jupyter
Avant de rentrer dans le vif du sujet, quelques prérequis sont nécessaires pour obtenir l'accès à Jupyter.
- Génération d'un mot de passe. Pour accéder à l'interface web de Jupyter, il vous est demandé un mot de passe. Afin de générer le mot de passe, entrez cette commande dans l'invite de commande :
python -c "import IPython;print(IPython.lib.passwd())"
Suivez les différentes étapes, et notez la ligne débutant par « sha1 : » elle vous sera utile à la prochaine étape.
- Configuration du mot de passe dans Jupyter. Dirigez-vous vers le dossier C:\ProgramData\jupyter et éditer le fichier jupyter_notebook_config.py. Dans ce fichier, remplacez la valeur de la clé 'c.NotebookApp.password' en spécifiant le résultat de la commande précédente comme valeur. Par exemple :
c.NotebookApp.password = 'sha1:6e3c137f3658:477944833cfb7bd2a323d3479f851e5c2588c283'
Attention : Dans le fichier jupyter_notebook_config.py, plusieurs clés c.NotebookApp.password peuvent être présentes ! Veillez à bien remplacer la dernière occurrence non commentée (pas de # devant la ligne).
Afin que nos modifications soient prises en compte, il est nécessaire de redémarrer le service, pour cela rendez-vous dans le menu Démarrer, Task Scheduler, et localisez dans la liste Active Tasks la tâche Start_IPython_Notebook. Une fois localisée, il suffit de la redémarrer (End/Start).
Si après cela le mot de passe n'est toujours pas accepté, il faudra redémarrer la machine.
Enfin, une petite mise à jour des packages via un terminal de commandes :
conda upgrade scikit-learn
conda install graphviz
conda install pydot_ng
Création d'un notebook
Une fois connecté, vous devriez voir apparaitre la liste des notebooks d'exemples fournit par Microsoft. N'hésitez pas à y jeter un œil. Nous allons créer un nouveau Notebook en utilisant le moteur d'exécution Python 2.
La première étape consiste à renommer notre notebook, File => Rename => « IRIS ». Pour la suite, Jupyter nous permet de générer dynamiquement des pages web interactives à partir de code python. Nous nous appuierons aussi sur la bibliothèque sklearn, proposant des outils dédiés au Machine Learning.
Maintenant que notre environnement est fin prêt, nous allons nous atteler aux tâches suivantes :
- Charger nos données dans une structure adaptée à l'interrogation dans Python.
- Préparer nos données afin de correspondre au format attendu par sklearn.
- Réduire l'espace de représentation de nos données, afin de les visualiser aisément.
- Mettre en place un modèle de classification se basant sur un arbre de décision.
Analyse avancée de données et Machine Learning via Python
%matplotlib inline
import csv
import requests
from pandas import DataFrame
from sklearn.decomposition import PCA
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import numpy as np
# Permet de passer de nos catégories textuelles, vers des catégories numériques, en conservant le mapping
encoder = LabelEncoder()
# Récupération et lecture du jeu de données
r = requests.get('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data')
data = str(r.text).split('\n')
reader = csv.DictReader(data, fieldnames = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'iris_class'])
# Génération d'un DataFrame (structure optimisée pour l'interrogation de nos données)
iris = DataFrame.from_dict([row for row in reader])
# On génère deux jeux de données:
# Un jeu contenant les variables d'un individu (l'entrée de notre classifieur)
# Un jeu contenant la classe d'un individu (la sortie de notre classifieur)
iris_X = iris[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
iris_Y = encoder.fit_transform(np.ravel(iris[['iris_class']]))
# Nos individus étant représentés par 4 variables, il est compliqué en l'état de pouvoir les visualiser.
# Afin de résoudre ce problème, on utilise une Analyse en Composantes Principales
# Cette méthode nous permets de factoriser les données initiales, en les combinant de manière intelligente
# Ainsi, en sélectionnant uniquement les deux premières composantes nous pourrons représenter nos individus aisément
pca = PCA(n_components=2)
iris_reduced = pca.fit_transform(iris_X)
# On affiche les individus dans la nouvelle base générée par la PCA
# A noter ici que le nombre de variables est maintenant de 2 (les 2 composantes de la PCA)
# IRIS[150 ind, 4 variables] => PCA(IRIS, 2) => [150 ind, 2 variables]
plt.figure(1, figsize=(15, 10))
plt.clf()
# Affichage des individus regroupés par classe
colours = ['g', 'r', 'b']
for (i, cla) in enumerate(set(iris_Y)):
xc = [p for (j,p) in enumerate(iris_reduced[:, 0]) if iris_Y[j]==cla]
yc = [p for (j,p) in enumerate(iris_reduced[:, 1]) if iris_Y[j]==cla]
plt.scatter(xc, yc, c=colours[i], label = encoder.inverse_transform(cla))
plt.xlabel('1th Component')
plt.ylabel('2nd Component')
Figure 6 : Code Python de génération du jeu de données et de l'ACP
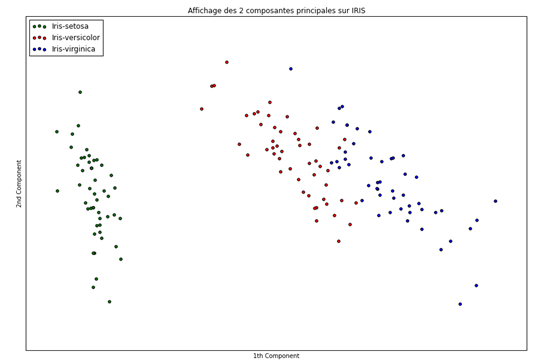
Figure 7 : Vue factorisée de données dans la base générée par les 2 première composantes de la PCA
Nous remarquons ici que l'analyse en composantes principales (ACP) (ou PCA en anglais) nous a permis de représenter nos individus sur 2 dimensions, en utilisant une combinaison de nos 4 variables précédentes (longueur des sépales, largeur des sépales, longueur des pétales, et largeur des pétales). Cette combinaison, n'est rien d'autre qu'une combinaison linéaire des variables initiales :

L'ACP possède d'autres propriétés qui sont très utiles pour réduire le nombre de variables d'un jeu de données (pour plus d'informations : ACP, Fléau de la dimension). Cependant, il est important de noter qu'une ACP génère de nouvelles variables, dont l'interprétation sera bien plus complexe que les variables initiales.
Aussi, cette méthode met en évidence ce que nous avions pu voir précédemment dans Power BI, selon lequel, la classe Setosa était vraiment démarquée des deux autres, par ses dimensions inférieures sur la quasi-totalité des variables à notre disposition.
Enfin, il est possible de conclure que les classes Versicolor et Virginica sont assez proches l'une de l'autre, tout en restant différentiables. Ces éléments sont encore une fois en accords avec les graphiques de Power BI, dans lequel la moyenne et la variance de ces deux classes étaient relativement proches.
Création d'un modèle prédictif via Python
Enfin, la dernière étape de notre parcours dans cette troisième partie du billet va nous permettre de mettre en place un modèle de prédiction capable, à partir de nos 4 variables d'entrées, de prédire la catégorie de notre Iris. Pour cela, nous allons utiliser un modèle simple, qui est l'arbre de décision.
Commençons par de petits rappels généraux sur ce type d'algorithmes :
- Génération d'un modèle sous la forme d'une hiérarchisation de décisions logiques.
- Les nœuds représentent des critères de divisions de l'échantillon.
- Deux branches à chaque nœud, une si le critère est rempli, une autre s'il ne l'est pas.
- Un critère n'apparait qu'une seule fois dans l'arbre :
- Si nous testons petal_width > 5 dans le 2ème nœud, nous ne pouvons pas avoir un 6ème nœud avec petal_width > 5
- En revanche, je peux tout à fait avoir mon 6ème nœud avec petal_width > 6
- Nous pouvons donc définir un critère comme un tuple (variable, opération, seuil)
- Plusieurs méthodes existent pour générer nos critères, se basant sur la dispersion d'une distribution : Coefficient de Gini, Entropie
- La méthode de classification générée par ces arbres est compréhensible par un humain (on parle alors de « boite blanche »).
Dans notre cas, étant donné la simplicité de notre jeu de données, nous utiliserons les paramètres par défauts de sklearn :
- Pas de limite dans la profondeur de l'arbre.
- Utilisation du coefficient de Gini comme critère de sélection.
Dans des conditions plus réalistes, il est rare de ne pas avoir à modifier (on parle alors de « tunning ») ces valeurs.
Puis, nous affichons l'exactitude (accuracy) du modèle afin d'évaluer le nombre de prédictions correctes :

from sklearn.tree import DecisionTreeClassifier
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
# Déclaration de notre arbre de décision
classifier = DecisionTreeClassifier()
# Génération d'un jeu d'entrainement de l'arbre, et d'un jeu de test
# Cette division en deux jeux de données permet d'éviter le phénomène d'overfitting
# Une partie des données n'étant pas utilisée pour générer le modèle, il sera donc plus générique (et moins spécifique)
X_train, X_test, Y_train, Y_test = train_test_split(iris_X, iris_Y, test_size=.4, random_state=0)
# Entrainement du classifieur
classifier.fit(X_train, Y_train)
# Vérification de la pertinence du modèle, via les données non utilisées pour l'apprentissage
Y_pred = classifier.predict(X_test)
print("Accuracy du modèle {0}".format(accuracy_score(Y_test, Y_pred)))
Figure 8 : Code de génération d'un arbre de décision sur sklearn
Avec une exactitude de 0,95, notre modèle a réussi à donner 95% de bonnes réponses. Notre modèle n'étant pas parfait, nous devons nous attacher aux individus qui n'ont pas su être bien classés. Pour cela, nous utilisons une matrice de confusion :

Figure 9 : Matrice de confusion
En X, nous avons la valeur donnée par notre classifieur (classifier), et en Y la valeur réelle. Nous constatons donc que les erreurs se situent dans la classification des iris versicolor et virginica (comme nous pouvions nous y attendre) du fait de leurs similarités.
Dans un processus de développement d'un modèle de classification, il serait alors intéressant d'essayer de déterminer quels sont les individus qui n'ont pas pu être correctement classés et déterminer les éléments pertinents qui pourraient permettre de faire mieux à la prochaine itération.
Affichage de l'arbre de décision généré
from IPython.display import Image, display
from sklearn.externals.six import StringIO
from sklearn import tree
import pydot_ng as pydot
dot_data = StringIO()
# Enfin, les arbres de décision ont la caractéristique d'être très explicite
# Nous allons donc générer un graphique détaillant les étapes permettant au classifieur de prendre sa décision
tree.export_graphviz(classifier, out_file=dot_data,
feature_names=iris_X.columns.values,
class_names=encoder.classes_,
filled=True, rounded=True,
special_characters=True)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
display(Image(graph.create_png()))

Figure 10 : Vue graphique du processus de classification de l'arbre de décision généré
Comme vous pouvez le constater, la classe Iris Setosa est encore une fois la plus simple à classer (nœud orange), elle ne nécessite en effet qu'une seule étape. Les deux autres classes nécessitent une descente plus profonde de l'arbre afin de pouvoir prendre une décision.
En guise de conclusion
Les intentions de cette machine virtuelle « Data Science VM » mise à disposition par Microsoft sur le magasin en ligne Azure Marketplace sont simples et se résument ainsi : permettre à n'importe qui de bénéficier rapidement d'un environnement de développement et d'exécution complet et prêt à l'usage pour l'analyse de données.
Basée sur des technologies et des produits largement répandues, cette VM fournit un cadre idéal pour la formation et l'expérimentation. Permettant à quiconque, qu'elle ou il dispose d'une expérience Windows Server ou Linux, de rapidement retrouver ses marques et d'accéder directement à l'essentiel.
Enfin, la flexibilité apportée par Microsoft Azure permet de s'adapter à chacune des charges de travail que vous pourriez être à même de rencontrer, et ce, de manière totalement transparente au niveau des coûts.
Bonnes analyses de données ! désormais à portée de clic avec Microsoft Azure ;-)