Quick-Start Guide to the Data Science Bowl Lung Cancer Detection Challenge, Using Deep Learning, Microsoft Cognitive Toolkit and Azure GPU VMs
This post is by Miguel Fierro, Data Scientist, Ye Xing, Senior Data Scientist, and Tao Wu, Principal Data Scientist Manager, all at Microsoft.
Since its launch in mid-January, the Data Science Bowl Lung Cancer Detection Competition has attracted more than 1,000 submissions. To be successful in this competition, data scientists need to be able to get started quickly and make rapid iterative changes. In this post, we show how to compute features of the scanned images in the competition with a pre-trained Convolutional Neural Network (CNN), and use these features to classify the scans into cancerous or not cancerous, using a boosted tree, all in one hour. With a score of 0.55979, you would be ranked in the top 10% as of January 19th on the leaderboard, or in the top 20% as of February 7th.
To achieve this, we used the following:
- A pre-trained CNN as the image featurizer. This 152-layer ResNet model is implemented on the Microsoft Cognitive Toolkit deep learning framework (formerly called CNTK) and trained using the ImageNet dataset.
- LightGBM gradient boosting framework as the image classifier.
- Azure Virtual Machines (VMs) with GPU acceleration.
For the impatient, we have shared our code in this Jupyter notebook. The computation of the Cognitive Toolkit process takes 53 minutes (29 minutes, if a simpler, 18-layer ResNet model is used), and the computation of the LightGBM process takes 6 minutes at a learning rate of 0.001. A simple version of the code was also published on Kaggle.
Introduction
According to the American Lung Association, lung cancer is the leading cancer in mortality, in both men and women in the US, with a low rate of early diagnosis. The Data Science Bowl competition on Kaggle aims to help with early lung cancer detection. Participants use machine learning to determine whether CT scans of the lung have cancerous lesions or not. A 3D representation of such a scan is shown in Fig. 1.
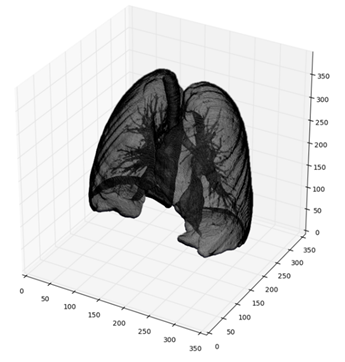
Fig. 1: 3D volume rendering of a sample lung using competition data. It was computed using the script from this blog post.
Training speed is one of the most important factors for success at competitions like these. In this respect, both Cognitive Toolkit and LightGBM are excellent in a range of tasks (Shi et al., 2016; LightGBM performance summary). These two solutions, combined with Azure's high-performance GPU VM, provide a powerful on-demand environment to compete in the Data Science Bowl.
To get started in in the GPU VM you need to install these frameworks:
CUDA: CUDA 8.0 can be downloaded from NVIDIA web (registration is required). If you are using Linux, you also need to download CUDA Patch 1 from the website. The patch adds support for gcc 5.4 as one of the host compilers.
cuDNN: cuDNN 5.1 (registration with NVIDIA required).
MKL: Intel´s Math Kernel Library (MKL) version 11.3 update 3 (registration with Intel required).
Anaconda: Anaconda 4.2.0 provides support for conda environments and jupyter notebooks.
OpenCV: Download and install from the official OpenCV website. This can also be installed via conda with this command:
conda install -c https://conda.binstar.org/conda-forge opencv
Scikit-learn: Scikit-learn 0.18 is easily installed via pip:
pip install scikit-learn
Cognitive Toolkit: Cognitive Toolkit 2.0 beta9 for Python. You can build from source but it's faster to install the precompiled binaries.
LightGBM: LightGBM is easily installed with CMake. You will also need to install the Python bindings.
Data management libraries: You also need to install dicom and glob libraries, using pip:
pip install pydicom glob2
In addition to these libraries and the pre-trained network (downloadable here), it's necessary to download the competition data. The images are in DICOM format and consist of a group of slices of the thorax of each patient (see Fig. 2).
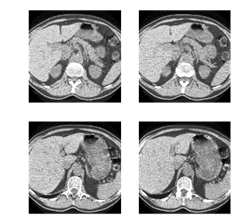
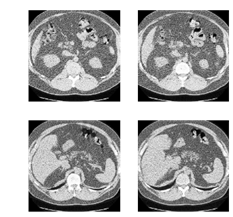
Fig. 2: Axial slices of the thorax of a patient with cancer (left) and a patient without cancer (right).
Cancer Image Detection with Cognitive Toolkit and LightGBM
Many deep learning applications use pre-trained models as a basis and apply trained models to a new domain, in a technique called transfer learning (Yosinski et al., 2014; Donahue et al., 2014; Oquab et al., 2014; Esteva et al., 2017). For image classification, the first few layers of a CNN represent low level features of the inputs, such as color blobs or texture features, and the last layers represent high-level features, specific to the classification task.
We use transfer learning with a pre-trained CNN on ImageNet as a featurizer to generate features from the Data Science Bowl dataset. Once the features are computed, a boosted tree using LightGBM is applied to classify the image.

Fig. 3: Representation of a ResNet CNN with an image from ImageNet. The input is an RGB image of a cat, the output is a probability vector,
whose maximum corresponds to the label "tabby cat".
Fig. 3 represents the typical scheme of a CNN classifying an image. The input image, in this case a cat, has a size of 224x224 and a depth of 3, corresponding to three color channels, red, green and blue (RGB). The image is exposed to convolutions in each internal layer, diminishing in size and growing in depth. The final layer outputs a vector of 1000 probabilities, corresponding to the 1000 classes of ImageNet. The predicted class of the network is the component with the higher probability.
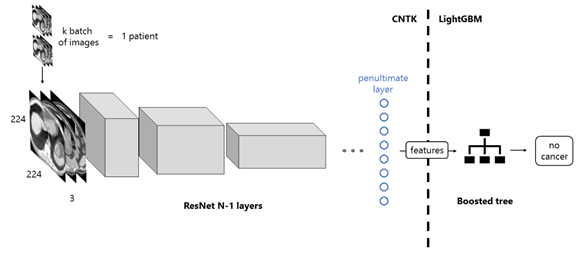
Fig. 4: Workflow of the proposed solution. The images of a patient scan are fed to the network in batches, which, after a forward propagation,
are transformed into features. This process is computed with the Microsoft Cognitive Toolkit. Next, these features are set as the input of a LightGBM
boosted tree, which classifies the images as those of a patient with or without cancer.
To create the featurizer, we remove the last layer of the CNN and use the output of the penultimate layer as features. The process is showed in Fig. 4. Each patient has an arbitrary number of scan images. The images are cropped to 224x244 and packed in groups of 3, to match the format of ImageNet. They are fed to the pre-trained network in k batches and then convoluted in each internal layer, until the penultimate one. This process is performed using Cognitive Toolkit. The output of the network are the features we're going to feed to the boosted tree, programmed with LightGBM.
In Fig. 5, the optimization loss of the boosted tree is shown. In an Azure VM on NC-24 GPU instance, the computation of the features takes 53 minutes with ResNet-152 and 29 minutes with ResNet-18. The training procedure has an early stopping of 300, which means that training stops when the loss has not improved in 300 epochs. For this reason, the training time of the boosted tree can vary between 1 and 10 minutes.
Fig. 5: Boosted tree loss in each epoch, with early stopping.
Once training is finished, we can compute the prediction using the validation set provided by Kaggle. This prediction is a CSV file that can be submitted to get a rank in the leaderboard.
Possible Improvements
In this post, we discussed a baseline example of applying a ResNet CNN architecture pre-trained on ImageNet to the problem of cancer detection based on medical images, something that will get you quickly started in the current Data Science Bowl competition. Cognitive Toolkit provides other pre-trained networks that you can test such as AlexNet, AlexNet with Batch Normalization and ResNet with 18 layers.
The example we provided shows how to transfer learnings from natural ImageNet images to medical images. In the medical imaging domain, we often lack annotated image datasets that are large enough to train deep neural networks, thus the use of the pre-trained ImageNet CNN models on natural images as a base mitigates this problem. While differences of image contrast and texture between medical images and natural images are significant, supervised fine-tuning, i.e., updating the weights of the pre-trained network by backpropagation using domain-specific data, is shown to perform well in a number of tasks (Shin et al., 2016, Esteva et al., 2017, Menegola et al., 2016, Tajbakhsh et al., 2016). Fine-tuning can be done on all layers or only on the later layers which contain more domain-specific features.
Another possible improvement would be to integrate traditional medical image techniques and features with CNN models. For example, nodule candidate locations are identified using a commercial grade computer-aided detection (CAD) system before the processed images are fed into a CNN, which helps improve CT lung nodule identification (Ginneken et al., 2015). As another example, traditional medical image features such as geometric features (tumor volume, relative distance measured from pleural wall, tumor shape) and texture features (gray-level co-occurrence matrix) are combined with deep features from pre-trained ImageNet models in the prediction of short-term and long-term lung cancer survivors (Paul et al., 2016). Generally speaking, having domain knowledge in medical imaging and a background in low-level image processing (such as delineating the boundary of anatomical structures) are helpful when applying these techniques.
Additionally, the dimension difference between 2D natural ImageNet images and 3D lung cancer CT images could also be considered. The example provided in this post uses three adjacent axial images as the three input channels to replace the original three RGB channels from 2D ImageNet images. Promising lung nodule detection results were achieved by using a pre-trained 2D CNN on a 2.5D representation of 3D volumetric images, which uses three orthogonal slices (axial, coronal and sagittal) through the center of nodule candidates marked from CAD as the input patch to the pre-trained 2D CNN model (Roth et al, 2014).
We hope this blog post and the quick start script shared in the notebook make it easier for you to participate in the Data Science Bowl competition. Happy hacking!
Miguel, Ye and Tao