Graph Engine, Private Customized: Key-value store with an attitude
Since our preview release announcement, we have been asked about what Graph Engine actually is. People want to know, what does GE provide to help them to achieve their goals, and what can they do to customize GE to fit their needs. Of all the interesting questions, today I'll cover the following two of them:
- Is GE essentially a hosted version of Titan or neo4j?
- Can I process non-graph data with GE?
For question one: "no" for "hosted". We do offer the ability to deploy your GE application to the cloud. But there is nothing stopping you to deploy and run it locally. By downloading the SDK from the Visual Studio gallery you have already acquired everything you needed to gear up your local environment, be it standalone or distributed. (Please check out https://www.graphengine.io/docs/manual/Utilities/geconfig.html, we have provided tools to configure a local GE cluster) Still not satisfied? Please move on to:
For question two: Yes, because you can use the underlying key-value store and the computation engine without introducing the graph model! No hacks or tweaks to the system! Indeed, the architecture of GE is illustrated as follows:

However, notice the inherent message: the Graph Model layer is defined with TSL(Trinity Specification Language), so that if you define something non-graph with TSL, your system will become like:
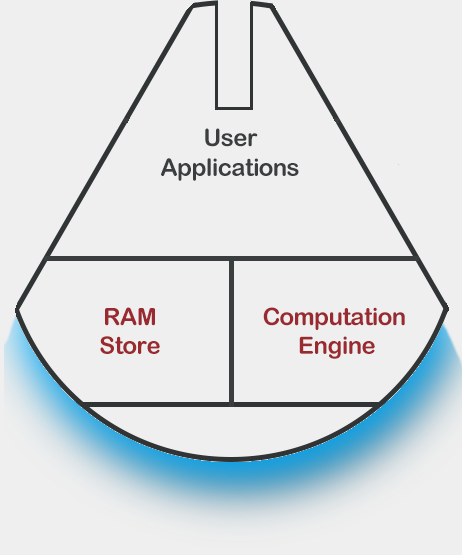
(Oh look, that makes a good millennium falcon.)
The key point here is about the TSL, of which the elements shape what GE really is. It defines both the storage schemata and the communication protocols, without which the GE would fall back to a basic memory cache. In other words, it defines how GE should understand your data. (Of course, if you do not want GE to understand the data, for example, when the data chunks are encrypted, the bare-metal distributed memory cache that GE offers is still a valid option). Let me go further and explain how to turn the ship^H^H^H^H GE into your very-own enhanced key-value store.
Schema matters.
There are quite a few options when we talk about the storage organization. For example, some stores allow you to save JSON document, others let you store primitive data structures, etc. These stores do not enforce a strong schema of the data. However, in many practical cases, the data is intrinsically structural. When you have a stream of many entries, it is likely that they will share some properties, which allows us to make an generalization of them. Also, to process the entries, we have to implement logics. The most obvious case is that, for statically-typed languages, people write data-access-objects(DAOs) to establish a connection between entries and runtime objects. Even if your language of choice is dynamically typed, despite not having to explicitly define the data types, logics do not run away -- your code is still data-driven, or you would end up ignoring the non-generalized part of the data. Hopefully the data does not get so complex that one has to leverage machine learning algorithms only for type inference.
Next, let's look at the physical storage layout when a data stream hits the storage, which is schema-free, and natively stores JSON objects. Suppose we have the following incoming json object(Taken from Twitter Developers https://dev.twitter.com/rest/reference/get/search/tweets):
{
"statuses": [
{
"coordinates": null,
"favorited": false,
"truncated": false,
"created_at": "Mon Sep 24 03:35:21 +0000 2012",
"id_str": "250075927172759552",
/* Lots of other properties that fill up 5 blog pages... */
},
{
"coordinates": null,
/* And it goes on... for another few pages... */
},
{
"coordinates": null,
/* And on... */
},
{
/* Imaging that there are thousands of this... */
}], /* Other stuff... */
}
We can see that, even in a single JSON object, there are a lot of repetitive patterns. In the given example, the most significant member of the JSON object is "statuses", an array list of nested JSON objects, each complying a fixed schema. However, JSON does not enforce a fixed schema so that a JSON store should always store the field names together with their values, and their field types.
Again and again.
This is a typical example of, when one has a data schema, but suffers from it. Overhead (which becomes so significant that it takes up more than a half of the storage space) to store and overhead to retrieve(where one has to enumerate the fields and check by name one after another to get something). We want our users to benefit from the schemata, not to suffer from it. By taking advantage of the schemata defined in the TSL, GE organizes fields in a data entry in a fixed format so that it is not necessary to store the name and data type of each field. Also, during a field retrieval, GE does not have to enumerate all the fields, as it can calculate the offset of the target field according to the predefined data schemata.
Tables? Collections? Types.
In a relational database, we group data records of the same type into a table. When we want to find a relation between different types of objects, we join. What options do we have if we leave the relational world and dive into NOSQL? In the following example, I will introduce two types of objects: kung-fu master and apprentice. Let's assume that each character has a name, and additionally, each apprentice can identify his/her master. The sample data set is presented in the following table:
ID Type MasterID Name
1 Master - Shifu
2 Apprentice 1 Panda
3 Apprentice 1 Tiger
4 Apprentice 1 Snake
5 Apprentice 1 Crane
6 Apprentice 1 Monkey
7 Apprentice 1 Mantis
8 Master - Oogway
9 Apprentice 8 Fenghuang
10 Apprentice 8 Monkey
11 Apprentice 8 Junjie
12 Apprentice 8 Chao
13 Apprentice 8 Taotie
14 Apprentice 8 Wushen
15 Apprentice 8 Thundering Rhino
16 Apprentice 8 Storming Ox
17 Apprentice 8 Golden Takin
With an RDBMS, we can create two tables for master and apprentice respectively, which is a straightforward solution. Each table has its own schema and we can omit the type of the character. Nothing much to worry about.
With a document store, the most intuitive way, if you are coming from a SQL background, is to create two collections and regard each of them as a table in an RDBMS. However, most document stores do not provide cross-collection data access patterns and manual implementation (through map-reduce or client-side logic) of that would have high cost. Instead of thinking about tables, now we have to break the wall and put everything in a single bag. We can store the type of the character as a string to identify them. However, given the absence of "data types", it is unlikely that a document store would provide a facility to focus on a single type of objects, and we have to apply our own filtering logic and use string matching to achieve type discrimination. Not to mention joins, which would probably involve two layers of that.
With a raw key-value store, the situation is worsen, as the ability to handle hierarchical data would be lost, and we have to "flatten" our data (a type of serialization, in some sense) so that each object fits in a single value slot(or we lost atomicity). Be it either a mystical placement logic over a weakly-typed array/dictionary or just plain object-string (de)serialization, the form of the data will drift away from its logical shape. One would end up turning both data and logic into strings with a lot of manual parsing and string concatenations.
What about Graph Engine? As we already know, GE is more than a key-value store with fixed data types. It allows you to define your own data structures, so storing hierarchical data is natively supported, with data access objects(DAOs) automatically generated by the TSL compiler. On the other hand, GE is not a fully-fledged document store so you cannot throw in arbitrary JSON data, which does fit very well in some particular scenarios, and is especially useful when, for example, you have a recursively-defined document and you encode a whole tree into a document(like XML or HTML). So, we can see GE as a storage lying between a primitive key value store and a document store, which is why I call it an "enhanced key-value store" :-) Here is an example of how to model our sample data set:
Cell Master
{
String Name;
}
Cell Apprentice
{
CellId MyMaster;
String Name;
}
Note that we still have to throw all the data into a single storage and there is no concept like the relational table. However, with data types defined in your schema, we provide type selectors on the storage, acting effectively as tables. Enumerating a type selector will return all the records of that type, plus that you can conduct LINQ queries over them.
From the schema we can see that, our masters are so forgetful that they do not remember their apprentices. Let's see how to help them to get a reunion with the help of a join operation:
static void Main(string[] args)
{
TrinityConfig.CurrentRunningMode = RunningMode.Embedded;
/* https://kungfupanda.wikia.com/wiki/Kung_Fu_Panda_Wiki */
Global.LocalStorage.SaveMaster(1, "Shifu");
Global.LocalStorage.SaveApprentice(2, 1, "Panda");
Global.LocalStorage.SaveApprentice(3, 1, "Tiger");
Global.LocalStorage.SaveApprentice(4, 1, "Snake");
Global.LocalStorage.SaveApprentice(5, 1, "Crane");
Global.LocalStorage.SaveApprentice(6, 1, "Monkey");
Global.LocalStorage.SaveApprentice(7, 1, "Mantis");
Global.LocalStorage.SaveMaster(8, "Oogway");
Global.LocalStorage.SaveApprentice(9, 8, "Fenghuang");
Global.LocalStorage.SaveApprentice(10, 8, "Monkey");
Global.LocalStorage.SaveApprentice(11, 8, "Junjie");
Global.LocalStorage.SaveApprentice(12, 8, "Chao");
Global.LocalStorage.SaveApprentice(13, 8, "Taotie");
Global.LocalStorage.SaveApprentice(14, 8, "Wushen");
Global.LocalStorage.SaveApprentice(15, 8, "Thundering Rhino");
Global.LocalStorage.SaveApprentice(16, 8, "Storming Ox");
Global.LocalStorage.SaveApprentice(17, 8, "Golden Takin");
var relations = from master in Global.LocalStorage.Master_Selector()
join apprentice in Global.LocalStorage.Apprentice_Selector()
on master.CellID equals apprentice.MyMaster into apprenticeGroup
select new { MasterName = master.Name, Apprentices = apprenticeGroup };
foreach(var relation in relations)
{
Console.WriteLine(relation.MasterName);
foreach(var apprentice in relation.Apprentices)
{
Console.WriteLine(">> {0}", apprentice.Name);
}
}
}
In the example given above, I first store the sample dataset into the local storage. To get a list of all the apprentices for a kung-fu master, we have to join the two types, which is achieved with a LINQ query over Global.LocalStorage.Master_Selector() and Global.LocalStorage.Apprentice_Selector(): just think of these two selectors as two tables in a relational database.
Atomicity, more than the usual ones.
Graph Engine comes with atomicity guaranteed. Operations applied to a cell are serialized, and observed in the same order by all readers. What makes it more useful than the usual atomic semantics is that, a user is not restricted to pre-defined operators like GET and PUT. Instead, we allow arbitrary operations to be applied to a cell, so that tasks like atomic increment of a counter, or atomic insertion into a list, can be easily achieved with simple user code. Also, you are not restricted to performing one operation at a time during an atomicity-guaranteed period. For example, during a single atomic "session", you can perform an atomic increment to a counter, an atomic write to a string, and an atomic insert into a list, at the same time, which would likely require a transaction in other NOSQL stores.
RESTful APIs extend your call stack to the remote side.
A stock Graph Engine instance does not provide any RESTful APIs. Instead of providing a fixed set of RESTful endpoints, we allow users to roll their own RESTful interfaces declaratively with the help of TSL. For example, you can define protocols to describe GET/PUT interfaces:
cell Entry
{
string data;
}
struct GETRequest
{
long entry_id;
}
protocol GET
{
type:HTTP;
request:GETRequest;
response:Entry;
}
struct PUTResponse
{
string message;
}
protocol PUT
{
type:HTTP;
request:Entry;
response:PUTResponse;
}
server KeyValueStore
{
protocol GET;
protocol PUT;
}
And define their semantics with simple user code:
internal class KeyValueStore : KeyValueStoreBase
{
public override void GETHandler(GETRequest request, out Entry response)
{
response = Global.LocalStorage.LoadEntry(request.entry_id);
}
public override void PUTHandler(Entry request, out PUTResponse response)
{
if (Global.LocalStorage.SaveEntry(request))
response.message = "OK";
else
response.message = "FAIL";
}
}
A more comprehensive example, which mimics many of Redis's interfaces can be found here: https://github.com/jiabaohan/SimpleRedis
At the end of this article I'd like to have some extra fun. Note that you can set the request or response type of a RESTful endpoint to "stream" so that you can directly operate on the HTTP stream. I'm going to stream some media through Graph Engine... Like this:
struct StreamingRequest
{
string filename;
}
protocol Streaming
{
Type:HTTP;
Request:StreamingRequest;
Response:stream;
}
server StreamingServer
{
protocol Streaming;
}
With a simple handler that pumps media data to the web endpoint:
internal class StreamingServer : Trinity.Extension.StreamingServerBase
{
public override void StreamingHandler(StreamingRequest request, HttpListenerResponse response)
{
byte[] content = File.ReadAllBytes(request.filename);
response.OutputStream.Write(content, 0, content.Length);
}
}
Party on!
