Transforming Open XML Word-Processing Documents to Html (Post #3)
Over the last couple of weeks, and over the next week, I've been designing and writing some code to convert Open XML word-processing documents to HTML (or Xhtml). My first post described in broad strokes my goals, my motivations for writing this code, and some details about the approach that I'm considering. My second post provided more detail about how I'll proceed, my first thoughts about my use of CSS, and specific limitations that I'll place on the conversion. I also presented my rational for not converting numbered/bulleted items to li elements. I also presented a skeleton of the conversion code. As I've been reading through the Open XML specification, more specifics about how I should proceed have become clear to me. In this post, I'm going to detail some of my conclusions.
This is one in a series of posts on transforming Open XML WordprocessingML to XHtml. You can find the complete list of posts here.
This blog is inactive.
New blog: EricWhite.com/blog
Blog TOCFirst, here are some additional limitations that I'm going to apply to this conversion:
· I'm not going to attempt to convert documents that contain sub-documents. This almost certainly would not be one of the primary scenarios. The conversion will throw an exception if the document contains the w:subDoc element.
· There are a number of legacy elements that I might be able to ignore: w:dayLong, w:dayShort, w:monthShort, w:monthLong, w:yearLong, w:yearShort, w:pgNum. Conforming applications should not be writing out these elements. At some point in the near future, I'm going to write some code to crawl my collection of sample Open XML documents, and count how many documents contain these elements. This will help me decide whether to do the work to support these elements.
· I'm going to ignore the w:ruby (phonetic guide) element. This could be interesting, but I'll reserve this for a later version if it's important. If this is important to you, I'd be very appreciative if you'd let me know.
· For phase one of this project, I'm going to do only a rudimentary conversion of DrawingML, specifically to convert images in drawings. DrawingML contains very rich constructs. Doing all such transformations and generating appropriate images is in and of itself a complicated project. However, basic images are described in DrawingML, and we need to be able to generate web pages that contain appropriate references to basic images, so it's important to handle this aspect of DrawingML. I'll defer the high-fidelity conversion of all aspects of DrawingML to a later project.
· I'm going to ignore all w:object elements. Rendering w:object elements is certainly not a main-line scenario.
· For phase one, I'm not going to attempt to render MathML markup. This is interesting, but as with DrawingML, non-trivial. In the interest in getting something working in the next couple of weeks, I'm not going to include conversion of MathML in phase one.
· As I mentioned in last week's post, I'm not going to convert text separated by physical tabs in phase one. There is no clean way to approach this, so until the best approach is clear, I'm not going to convert them.
As I mentioned in the first post, I'm going to simplify the word-processing markup before transforming to HTML. Here are some of the ways that I'll simplify:
· I'll remove all rsid elements and attributes before doing the conversion to HTML.
· I'll remove all comments, end notes, and foot notes before doing the conversion.
· I'll coalesce superfluous runs – combine adjacent runs with identical formatting to a single run.
· And as I mentioned in the first post, I'll accept all tracked changes (tracked revisions) before doing the conversion.
Now that I've detailed what I won't convert, here is what I will convert:
· I'll convert all paragraphs and runs, including all text, formatted with the correct font, and with correct paragraph formatting, such as space before and after each paragraph. This includes honoring all style inheritance, as well as honoring all places where styles defer decisions on font and colors to themes.
· I'll convert all tables with a high degree of fidelity, including theme formatting, conditional formatting, and tables within tables. I believe I'll be able to correctly transform both horizontally and vertically merged cells.
· I'll convert all numbered/bulleted items to straight paragraphs, not li elements. I detailed my rational for this decision last week. I'm curious to see how this decision holds up in real-world situations.
· I'll convert all images, which are represented by DrawingML. This includes resizing, rotating, mirroring, and flipping images so that the resulting web page looks as close to the word-processing document as possible. By far, the most important of these is resizing.
· I'll render w:sectPr as a div element.
· I'll appropriately render the cr, noBreakHyphen, tab, and br elements.
There are two varieties of hyperlinks as defined in Open XML: hyperlinks described in field codes, and hyperlinks in the simplified version that uses an external reference. For simplicity, I'll convert all field code hyperlinks to the simplified version before doing the conversion to HTML. Other than hyperlink field codes, I'll remove all other field code markup, leaving the rendering markup. For example, markup for a typical field code looks like this:
<w:p>
<w:r>
<w:fldCharw:fldCharType="begin"/>
</w:r>
<w:r>
<w:instrTextxml:space="preserve"> DATE </w:instrText>
</w:r>
<w:r>
<w:fldCharw:fldCharType="separate"/>
</w:r>
<w:r>
<w:rPr>
<w:noProof/>
</w:rPr>
<w:t>10/15/2009</w:t>
</w:r>
<w:r>
<w:fldCharw:fldCharType="end"/>
</w:r>
</w:p>
In the simplification process, I'll transform this markup to the following, which will be easy to render in HTML:
<w:p>
<w:r>
<w:t>10/15/2009</w:t>
</w:r>
</w:p>
Perhaps the most complicated thing to sort out is applying paragraph, table, numbering, and character styling per all the rules as laid out in the specification. For a single paragraph in a cell, there are properties that must be applied from a) document defaults, b) table formatting, including conditional table formatting, c) paragraph formatting, and d) run formatting. All of these properties must be applied in a very specific order. Further, fonts may be defined in themes, and if so, need to be rendered with those fonts as appropriate.
Section 2.7.2 of the Ecma 376 specification (17.7.2 of IS29500) has the following diagram indicating precedence of application of styles:
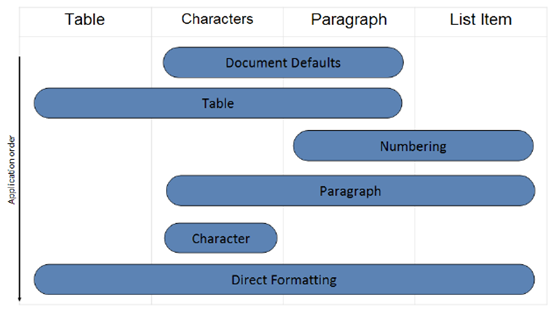
Here is a description of the process:
· First, the document defaults are applied to all runs and paragraphs in the document.
· Next, the table style properties are applied to each table in the document, following the conditional formatting inclusions and exclusions specified per table.
· Next, numbered item and paragraph properties are applied to each paragraph formatted with a numbering style.
· Next, paragraph and run properties are applied to each 1 paragraph as defined by the paragraph style.
· Next, run properties are applied to each run with a specific character style applied.
· Finally, we apply direct formatting (paragraph or run properties not from styles). If this direct formatting includes numbering, that numbering + the associated paragraph properties are applied.
I could write the code so that as I process each run, I go back through all locations where there are elements that might impact styling, and collect that information, coalesce that information, and then render the HTML. This might be the most efficient way to proceed in terms of processing time and memory consumption. However, it means that a specific rule for styling as dictated by the Open XML specification will be rendered in code that is scattered throughout the conversion code, which is not the easiest to debug.
Instead, I've decided on an approach where I process markup per the rules in section Ecma 2.7.2 (IS29500 17.7.2) of the specification, as well as the rules in 2.7.5 (IS29500 17.7.5), and add all styling information to every paragraph and run in the document. As I add this styling information, all add my own custom attributes that tell the order that this styling information must be applied. I'll also add an attribute that describes where that styling information came from. To make this clear, suppose I have a document that has the following document defaults that define the paragraph and run properties that should be applied to all paragraphs and runs in the document:
<w:docDefaults>
<w:rPrDefault>
<w:rPr>
<w:rFontsw:asciiTheme="minorHAnsi"
w:eastAsiaTheme="minorHAnsi"
w:hAnsiTheme="minorHAnsi"
w:cstheme="minorBidi"/>
<w:szw:val="22"/>
<w:szCsw:val="22"/>
<w:langw:val="en-US"
w:eastAsia="en-US"
w:bidi="ar-SA"/>
</w:rPr>
</w:rPrDefault>
<w:pPrDefault>
<w:pPr>
<w:spacingw:after="200"
w:line="276"
w:lineRule="auto"/>
</w:pPr>
</w:pPrDefault>
</w:docDefaults>
And suppose I have a paragraph with paragraph properties, that contains a run that has run properties:
<w:p>
<w:pPr>
<w:spacingw:after="0"/>
</w:pPr>
<w:r>
<w:txml:space="preserve">This </w:t>
</w:r>
<w:r>
<w:rPr>
<w:rFontsw:ascii="Courier New"
w:hAnsi="Courier New"
w:cs="Courier New"/>
<w:b/>
</w:rPr>
<w:t>is</w:t>
</w:r>
<w:r>
<w:txml:space="preserve"> a test.</w:t>
</w:r>
</w:p>
So before doing the final transform to HTML, I'll transform the paragraph and run to contain properties both from the document defaults, and properties that were directly applied:
<w:p>
<w:pPr
ptoxml:Order="0"
ptoxml:Source="document defaults: style part: /w:styles/w:docDefaults/w:pPrDefault/w:pPr">
<w:spacingw:after="200"
w:line="276"
w:lineRule="auto"/>
</w:pPr>
<w:pPr>
<w:spacingw:after="0"/>
</w:pPr>
<w:r>
<w:txml:space="preserve">This </w:t>
</w:r>
<w:r>
<w:rPr
ptoxml:Order="0"
ptoxml:Source="document defaults: style part: /w:styles/w:docDefaults/w:rPrDefault/w:rPr">
<w:rFontsw:asciiTheme="minorHAnsi"
w:eastAsiaTheme="minorHAnsi"
w:hAnsiTheme="minorHAnsi"
w:cstheme="minorBidi"/>
<w:szw:val="22"/>
<w:szCsw:val="22"/>
<w:langw:val="en-US"
w:eastAsia="en-US"
w:bidi="ar-SA"/>
</w:rPr>
<w:rPr>
<w:rFontsw:ascii="Courier New"
w:hAnsi="Courier New"
w:cs="Courier New"/>
<w:b/>
</w:rPr>
<w:t>is</w:t>
</w:r>
<w:r>
<w:txml:space="preserve"> a test.</w:t>
</w:r>
</w:p>
This means that I'll be creating an intermediate XML document that is larger than the original – memory use will be somewhat higher. But there are two important advantages of this approach. First, the code to deal with each area of styling markup will be localized. Second, the code will be significantly easier to debug.
For example, there will be only a few lines of code, located in one place, to deal with document default properties (Ecma 2.7.4, IS29500 17.7.4). This code will duplicate the default paragraph properties on every paragraph in the document, and will duplicate the default run properties on every run in the document. Then, I'll process the table styling properties in a similar fashion: I'll duplicate the paragraph and run properties, placing them on every paragraph and run in the table. Then I'll process paragraph and run properties, per the diagram above. As I add each of these paragraph and run properties to their respective locations, I'll assign an order of application to them. When it comes time to render the paragraphs and runs in HTML, I can simply roll up all paragraph and run properties per their assigned order, coalesce them, and then render the HTML. If I'm not getting the results I want, then debugging becomes a simple matter of looking at the paragraph and run properties before coalescing, and seeing where I went wrong in assembling the pile of formatting properties.
One key advantage of this approach is that the code and its algorithm will have a direct correlation to the text of the specification. The code should be relatively simple to read. One interesting point to note is that with this approach, it will take extra work to generate CSS classes for paragraph and character styles. It would be easiest to generate the CSS as in-line only, forgoing generation of classes. This is the approach that I'm going to take first. Then, I'll take a look at how much work it would be to generate CSS styles, and determine if the payoff is worth the cost. As I mentioned in my last post on this topic, my primary goal is to provide a reasonably accurate conversion for use in certain developer scenarios. It isn't a primary goal to provide perfect separation between content and presentation, which would be the primary advantage of generation of CSS styles.
My next work item is to write the code to propagate formatting properties per this approach. Following that, I'll write the code to roll up (coalesce) the formatting properties. And finally, I can write the code to do the transform to HTML (or XHtml).
Comments
Anonymous
November 03, 2009
The comment has been removedAnonymous
November 04, 2009
Hi David, this has been really fun - a great way to teach myself more detail about Open XML, as well as a way to learn XHtml and CSS. Regarding C# or VB.NET: FWIW, I'll be delivering my source code in C#. I've posted the latest part of this effort - comparison of XHtml/CSS tables to WordprocessingML tables. -EricAnonymous
December 21, 2009
This is fantastic. Documenting the thought processes and rationale behind some of these decisions here is very helpful in threshing out other similar solutions. I'm curious on your thoughts on the OpenXml SDK? Thanks for the great work.Anonymous
December 21, 2009
Hi DL, thanks, I'm glad you like the series. It's been great fun, and its going to be fun to finish. I think that the Open XML SDK is great. It's main forte is document querying and generation solutions. There are issues with it around document-centric transforms, such as WordprocessingML to XHtml, so til now I've been using LINQ to XML for those scenarios. -EricAnonymous
April 21, 2010
Suppose one wanted to chuck all of the rich formatting that Word offers and get s simple <ul> out of a doc...how would you go about doing that? It's simple enough to check the style name for the node for "ListBullet", and then replace it with an LI tag, but that creates orphaned items. Surely there's a more elegant way...Anonymous
April 21, 2010
Hi Chris, I agree - could be good in some scenarios to disregard the rich formatting that Word offers. However, this was one of the biggest criticisms for other Html translators - they didn't handle numbered lists properly. You could look at various lists, and make a determination as to whether they could be translated to the simple LI tag. I made the decision to not go that direction. Certainly, though, it's possible - just some work. -EricAnonymous
July 05, 2010
hi Eric I am creating a word document.The document contains a image. The image is stored in the package -> word/media/myImage.jpeg , the question is how to get the image from word document using the sdk 2.0