Introdução ao Azure Synapse Link para a Base de Dados SQL do Azure
Este artigo é um guia passo a passo para começar a usar o Azure Synapse Link para o Banco de Dados SQL do Azure. Para obter uma visão geral desse recurso, consulte Azure Synapse Link for Azure SQL Database.
Pré-requisitos
Para obter o Azure Synapse Link for SQL, consulte Criar um novo espaço de trabalho do Azure Synapse. O tutorial atual é criar o Azure Synapse Link for SQL em uma rede pública. Este artigo pressupõe que você selecionou Desabilitar rede virtual gerenciada e Permitir conexões de todos os endereços IP quando criou um espaço de trabalho do Azure Synapse. Se você quiser configurar o Azure Synapse Link para o Banco de Dados SQL do Azure com segurança de rede, consulte também Configurar o Azure Synapse Link para o Banco de Dados SQL do Azure com segurança de rede.
Para provisionamento baseado em unidade de transação de banco de dados (DTU), verifique se o serviço do Banco de Dados SQL do Azure é, pelo menos, camada Standard com um mínimo de 100 DTUs. Não há suporte para níveis Gratuito, Básico ou Standard com menos de 100 DTUs provisionadas.
Configurar o banco de dados SQL do Azure de origem
Inicie sessão no portal do Azure.
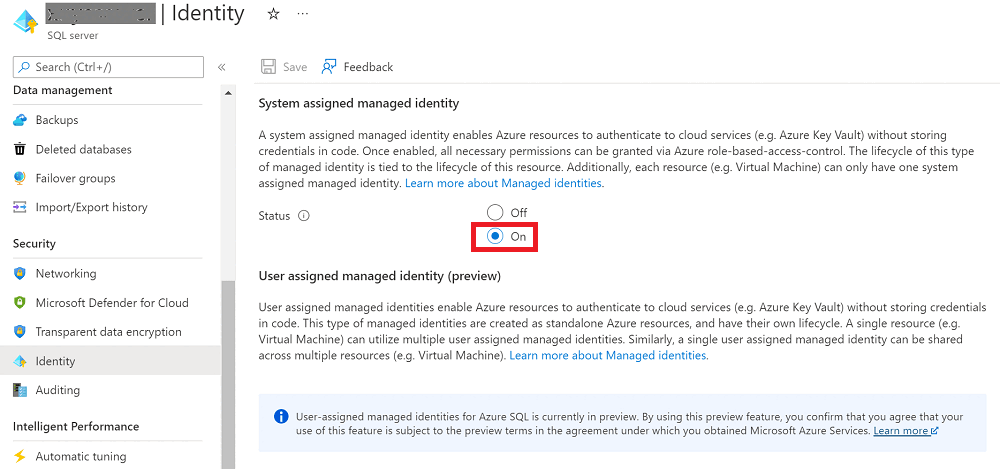
Vá para o servidor lógico SQL do Azure, selecione Identidade e defina Identidade gerenciada atribuída ao sistema como Ativado.
Vá para Rede e marque a caixa de seleção Permitir que os serviços e recursos do Azure acessem este servidor .

Usando o Microsoft SQL Server Management Studio (SSMS) ou o Azure Data Studio, conecte-se ao servidor lógico. Se você quiser que seu espaço de trabalho do Azure Synapse se conecte ao seu banco de dados SQL do Azure usando uma identidade gerenciada, defina as permissões de administrador do Microsoft Entra no servidor lógico. Para aplicar os privilégios na etapa 6, use o mesmo nome de administrador para se conectar ao servidor lógico com privilégios administrativos.
Expanda Bancos de Dados, clique com o botão direito do mouse no banco de dados que você criou e selecione Nova Consulta.
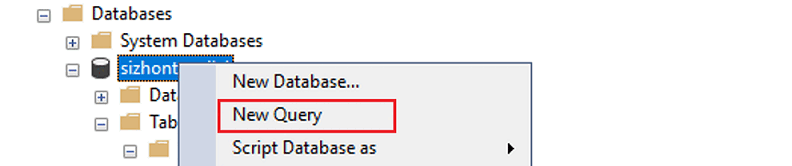
Se você quiser que seu espaço de trabalho do Azure Synapse se conecte ao seu banco de dados SQL do Azure de origem usando uma identidade gerenciada, execute o script a seguir para fornecer a permissão de identidade gerenciada ao banco de dados de origem.
Você pode ignorar esta etapa se, em vez disso, quiser que seu espaço de trabalho do Azure Synapse se conecte ao seu banco de dados SQL do Azure de origem por meio da autenticação SQL.
CREATE USER <workspace name> FROM EXTERNAL PROVIDER; ALTER ROLE [db_owner] ADD MEMBER <workspace name>;Você pode criar uma tabela com seu próprio esquema. O código a seguir é apenas um exemplo de uma
CREATE TABLEconsulta. Você também pode inserir algumas linhas nesta tabela para garantir que haja dados a serem replicados.CREATE TABLE myTestTable1 (c1 int primary key, c2 int, c3 nvarchar(50))


Crie seu pool SQL do Azure Synapse de destino
Abra o Synapse Studio.
Vá para o hub Gerenciar , selecione Pools SQL e, em seguida, selecione Novo.
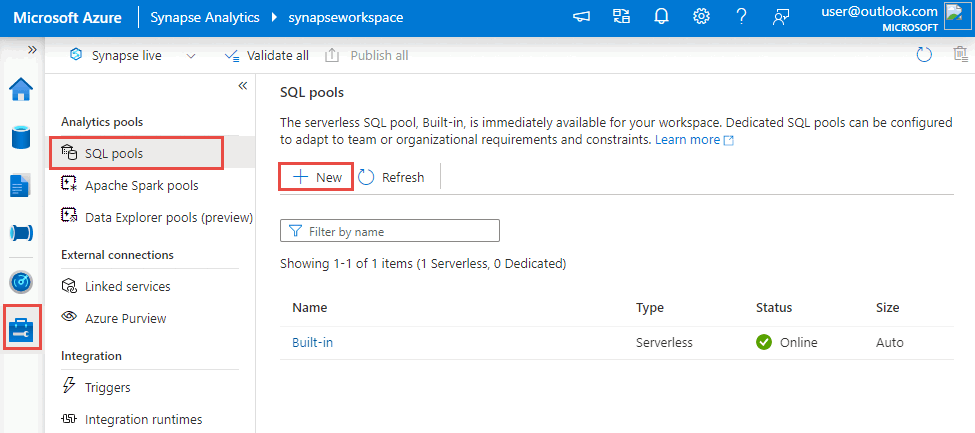
Insira um nome de pool exclusivo, use as configurações padrão e crie o pool dedicado.
Você precisará criar um esquema se o esquema esperado não estiver disponível no banco de dados SQL do Azure Synapse de destino. Se o esquema for proprietário do banco de dados (dbo), você poderá ignorar esta etapa.

Criar a conexão do Azure Synapse Link
No painel esquerdo do portal do Azure, selecione Integrar.
No painel Integrar, selecione o sinal de adição (+) e, em seguida, selecione Ligação à ligação.
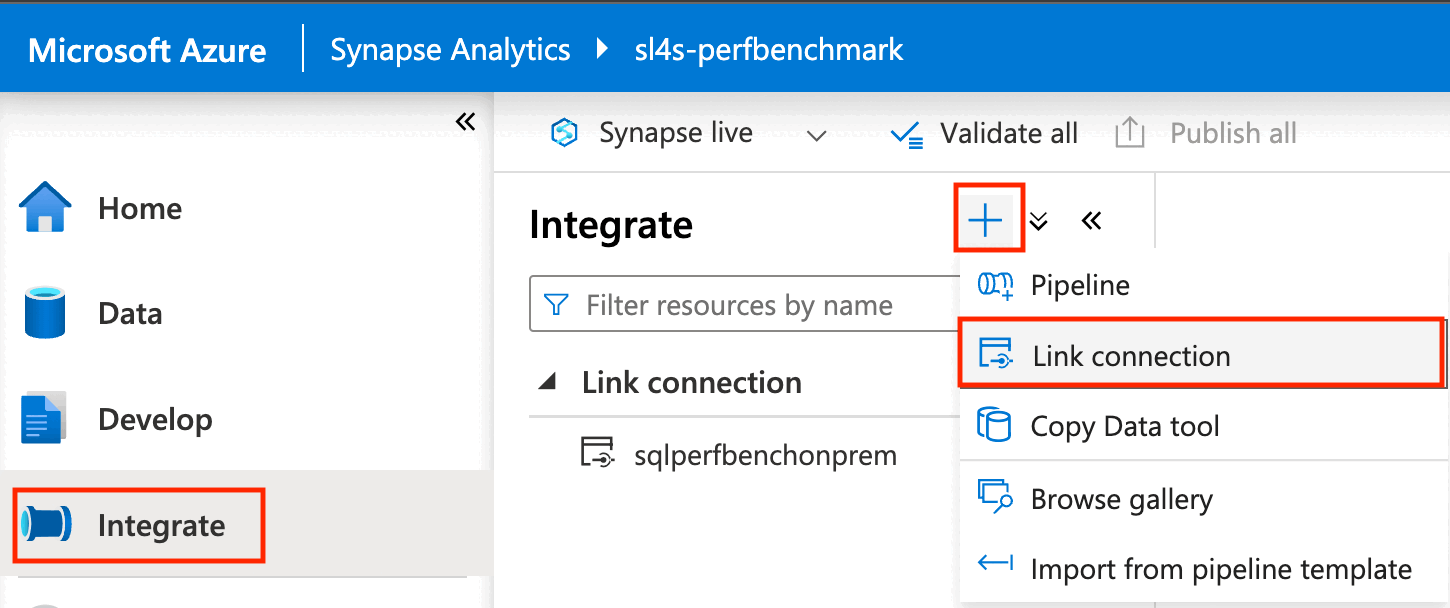
Em Serviço vinculado de origem, selecione Novo.
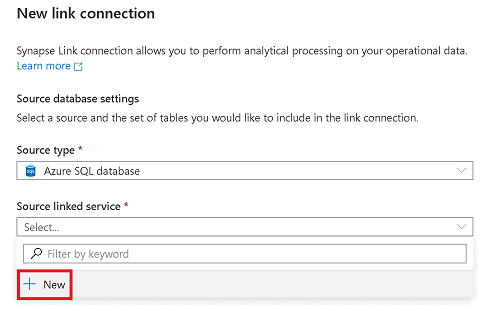
Insira as informações para seu banco de dados SQL do Azure de origem.
- Selecione a assinatura, o servidor e o banco de dados correspondentes ao seu banco de dados SQL do Azure.
- Proceda de uma das seguintes formas:
- Para conectar seu espaço de trabalho do Azure Synapse ao banco de dados de origem usando a identidade gerenciada do espaço de trabalho, defina Tipo de autenticação como Identidade gerenciada.
- Para usar a autenticação SQL em vez disso, se você souber o nome de usuário e a senha a serem usados, selecione Autenticação SQL.
Nota
Somente o Serviço Vinculado na versão herdada é suportado.
Selecione Testar conexão para garantir que as regras de firewall estejam configuradas corretamente e que o espaço de trabalho possa se conectar com êxito ao banco de dados SQL do Azure de origem.
Selecione Criar.
Nota
O serviço vinculado que você cria aqui não é dedicado ao Azure Synapse Link for SQL. Ele pode ser usado por qualquer usuário do espaço de trabalho que tenha as permissões apropriadas. Reserve um tempo para entender o escopo dos usuários que podem ter acesso a esse serviço vinculado e suas credenciais. Para obter mais informações sobre permissões nos espaços de trabalho do Azure Synapse, consulte Visão geral do controle de acesso do espaço de trabalho do Azure Synapse - Azure Synapse Analytics.
Selecione uma ou mais tabelas de origem para replicar para o seu espaço de trabalho do Azure Synapse e, em seguida, selecione Continuar.
Nota
Uma tabela de origem especificada pode ser habilitada em apenas uma conexão de link de cada vez.
Selecione um banco de dados SQL e um pool do Azure Synapse de destino.
Forneça um nome para sua conexão do Azure Synapse Link e selecione o número de núcleos para a computação da conexão de link. Esses núcleos serão usados para a movimentação de dados da origem para o destino.
Nota
- O número de núcleos selecionados aqui é alocado ao serviço de ingestão para processar o carregamento e as alterações de dados. Eles não afetam a configuração do Banco de Dados SQL do Azure de origem ou a configuração do pool SQL dedicado de destino.
- Recomendamos começar baixo e aumentar o número de núcleos conforme necessário.
Selecione OK.
Com a nova conexão do Azure Synapse Link aberta, você pode atualizar o nome da tabela de destino, o tipo de distribuição e o tipo de estrutura.
Nota
- Considere o uso da tabela de heap para o tipo de estrutura quando seus dados contiverem varchar(max), nvarchar(max) e varbinary(max).
- Verifique se o esquema em seu pool dedicado SQL do Azure Synapse já foi criado antes de iniciar a conexão de link. O Azure Synapse Link for SQL criará tabelas automaticamente sob seu esquema no pool dedicado do Azure Synapse SQL.
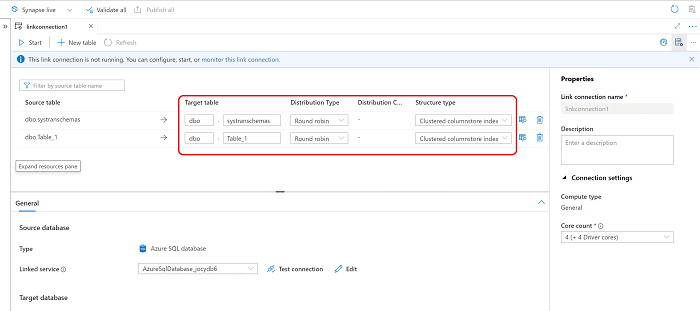
Na lista suspensa Ação na tabela de destino existente, escolha a opção mais apropriada para o seu cenário se a tabela já existir no destino.
- Soltar e recriar tabela: A tabela de destino existente será descartada e recriada.
- Falha na tabela não vazia: Se a tabela de destino contiver dados, a conexão de link para a tabela determinada falhará.
- Mesclar com dados existentes: os dados serão mesclados na tabela existente.
Nota
Se você quiser mesclar várias fontes no mesmo destino escolhendo "Mesclar com dados existentes", verifique se as fontes contêm dados diferentes para evitar conflitos e resultados inesperados.
Especifique se deseja habilitar a consistência da transação entre tabelas.
- Quando essa opção está habilitada, uma transação que abrange várias tabelas no banco de dados de origem é sempre replicada para o banco de dados de destino em uma única transação. Isso, no entanto, criará sobrecarga na taxa de transferência geral da replicação.
- Quando a opção estiver desabilitada, cada tabela replicará as alterações em seu próprio limite de transação para o destino em conexões paralelas, melhorando assim a taxa de transferência geral da replicação.
Nota
Quando você quiser habilitar a consistência da transação entre tabelas, verifique também se os níveis de isolamento de transação no pool SQL dedicado do Synapse é READ COMMITTED SNAPSHOT ISOLATION.
Selecione Publicar tudo para salvar a nova conexão de link com o serviço.

Iniciar a conexão do Azure Synapse Link
Selecione Iniciar e aguarde alguns minutos para que os dados sejam replicados.
Nota
Uma conexão de link será iniciada a partir de uma carga inicial completa do seu banco de dados de origem, seguida por feeds de alteração incrementais por meio do recurso de feed de alterações no Banco de Dados SQL do Azure. Para obter mais informações, consulte Azure Synapse Link for SQL change feed.
Monitorar o status da conexão do Azure Synapse Link
Você pode monitorar o status de sua conexão do Azure Synapse Link, ver quais tabelas estão sendo copiadas inicialmente (instantâneo) e ver quais tabelas estão no modo de replicação contínua (replicação).
Vá para o hub Monitor e selecione Vincular conexões.
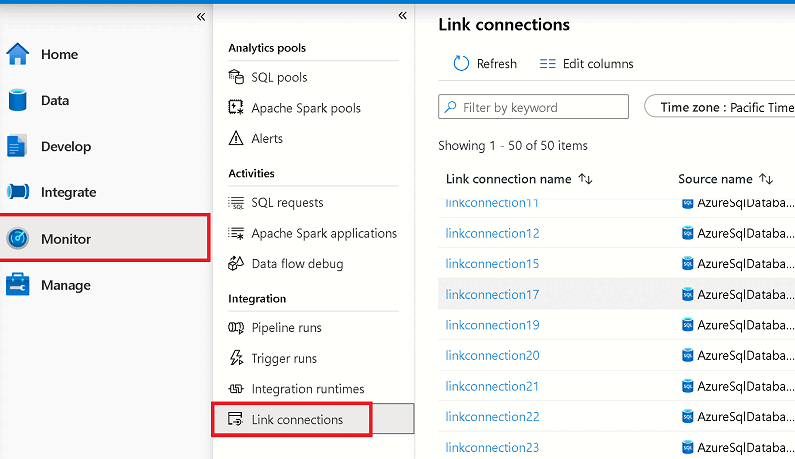
Abra a conexão do Azure Synapse Link que você iniciou e exiba o status de cada tabela.
Selecione Atualizar na vista de monitorização da sua ligação para observar quaisquer atualizações ao estado.
Consultar os dados replicados
Aguarde alguns minutos e, em seguida, verifique se o banco de dados de destino tem a tabela e os dados esperados. Agora você também pode explorar as tabelas replicadas em seu pool dedicado SQL do Azure Synapse de destino.
No hub de dados, em Espaço de trabalho, abra o banco de dados de destino.
Em Tabelas, clique com o botão direito do rato numa das tabelas de destino.
Selecione Novo script SQL e, em seguida, selecione As 100 principais linhas.
Execute esta consulta para exibir os dados replicados em seu pool dedicado SQL do Azure Synapse de destino.
Você também pode consultar o banco de dados de destino usando o SSMS ou outras ferramentas. Use o ponto de extremidade dedicado SQL para seu espaço de trabalho como o nome do servidor. Este nome é geralmente
<workspacename>.sql.azuresynapse.net. AdicioneDatabase=databasename@poolnamecomo um parâmetro de cadeia de conexão extra quando estiver se conectando via SSMS ou outras ferramentas.
Adicionar ou remover uma tabela em uma conexão existente do Azure Synapse Link
Para adicionar ou remover tabelas no Synapse Studio, faça o seguinte:
Abra o hub Integrar .
Selecione a ligação de ligação que pretende editar e, em seguida, abra-a.
Efetue um dos seguintes procedimentos:
- Para adicionar uma tabela, selecione Nova tabela.
- Para remover uma tabela, selecione o ícone da lixeira ao lado dela.

Nota
Você pode adicionar ou remover tabelas diretamente quando uma conexão de link estiver em execução.

Parar a conexão do Azure Synapse Link
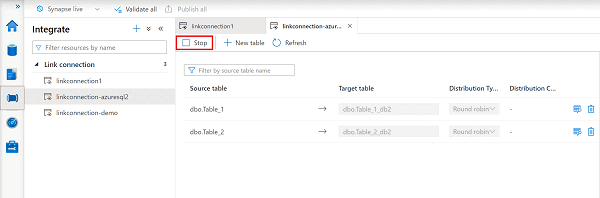
Para interromper a conexão do Azure Synapse Link no Synapse Studio, faça o seguinte:
No espaço de trabalho do Azure Synapse, abra o hub Integrar .
Selecione a ligação de ligação que pretende editar e, em seguida, abra-a.
Selecione Parar para interromper a conexão do link e ele interromperá a replicação de seus dados.
Nota
- Se você reiniciar uma conexão de link depois de interrompê-la, ela será iniciada a partir de uma carga inicial completa do seu banco de dados de origem e feeds de alteração incremental seguirão.
- Se você escolher "Mesclar com dados existentes" como a ação na tabela de destino existente, quando você parar a conexão de link e reiniciá-la, as exclusões de registro na origem durante esse período não serão excluídas no destino. Nesse caso, para garantir a consistência dos dados, considere usar pausa/retomada em vez de parar/iniciar ou limpar as tabelas de destino antes de reiniciar a conexão de link.
Conteúdos relacionados
- Obter ou definir uma identidade gerenciada para um servidor lógico ou instância gerenciada do Banco de Dados SQL do Azure
- Perguntas frequentes sobre o Azure Synapse Link for SQL
- Configurar o Azure Synapse Link para o Azure Cosmos DB
- Configurar o Azure Synapse Link for Dataverse
- Introdução ao Azure Synapse Link para o SQL Server 2022