Analisar dados com o Azure Machine Learning
Este tutorial usa o designer do Azure Machine Learning para criar um modelo de aprendizado de máquina preditivo. O modelo é baseado nos dados armazenados no Azure Synapse. O cenário para o tutorial é prever se um cliente provavelmente comprará uma bicicleta ou não, para que a Adventure Works, a loja de bicicletas, possa construir uma campanha de marketing direcionada.
Pré-requisitos
Para seguir este tutorial, é necessário:
- um pool SQL pré-carregado com dados de exemplo do AdventureWorksDW. Para provisionar esse pool SQL, consulte Criar um pool SQL e escolha carregar os dados de exemplo. Se você já tiver um data warehouse, mas não tiver dados de exemplo, poderá carregar dados de exemplo manualmente.
- um espaço de trabalho do Azure Machine Learning. Siga este tutorial para criar um novo.
Obter os dados
Os dados usados estão na visualização dbo.vTargetMail no AdventureWorksDW. Para usar o Datastore neste tutorial, os dados são exportados primeiro para a conta do Armazenamento do Azure Data Lake, pois o Azure Synapse não oferece suporte a conjuntos de dados no momento. O Azure Data Factory pode ser usado para exportar dados do data warehouse para o Armazenamento do Azure Data Lake usando a atividade de cópia. Use a seguinte consulta para importação:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Quando os dados estiverem disponíveis no Armazenamento do Azure Data Lake, os Armazenamentos de Dados no Azure Machine Learning serão usados para se conectar aos serviços de armazenamento do Azure. Siga as etapas abaixo para criar um Datastore e um Dataset correspondente:
Inicie o estúdio do Azure Machine Learning a partir do portal do Azure ou inicie sessão no estúdio do Azure Machine Learning.
Clique em Datastores no painel esquerdo na seção Gerenciar e, em seguida, clique em New Datastore.
Forneça um nome para o armazenamento de dados, selecione o tipo como 'Armazenamento de Blob do Azure', forneça local e credenciais. Em seguida, clique em Criar.
Em seguida, clique em Conjuntos de dados no painel esquerdo na seção Ativos . Selecione Criar conjunto de dados com a opção Do armazenamento de dados.
Especifique o nome do conjunto de dados e selecione o tipo a ser tabular. Em seguida, clique em Avançar para avançar.
Em Selecionar ou criar uma seção de armazenamento de dados, selecione a opção Armazenamento de dados criado anteriormente. Selecione o armazenamento de dados que foi criado anteriormente. Clique em Avançar e especifique o caminho e as configurações do arquivo. Certifique-se de especificar o cabeçalho da coluna se os arquivos contiverem um.
Por fim, clique em Criar para criar o conjunto de dados.
Configurar experimento de designer
Em seguida, siga as etapas abaixo para a configuração do designer:
Clique na guia Designer no painel esquerdo na seção Autor .
Selecione Componentes pré-construídos fáceis de usar para criar um novo pipeline.
No painel de configurações à direita, especifique o nome do pipeline.
Além disso, selecione um cluster de computação de destino para todo o experimento no botão de configurações para um cluster provisionado anteriormente. Feche o painel Configurações.
Importar os dados
Selecione a subguia Conjuntos de dados no painel esquerdo abaixo da caixa de pesquisa.
Arraste o conjunto de dados criado anteriormente para a tela.
Limpar os dados
Para limpar os dados, solte as colunas que não são relevantes para o modelo. Siga os passos abaixo:
Selecione a subguia Componentes no painel esquerdo.
Arraste o componente Selecionar Colunas no Conjunto de Dados em Manipulação de Transformação < de Dados para a tela. Conecte este componente ao componente Conjunto de dados.
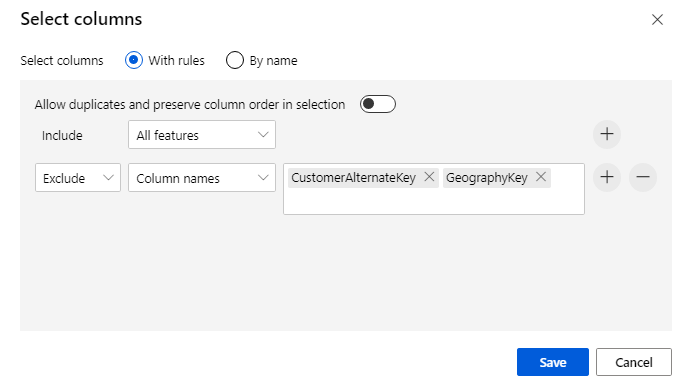
Clique no componente para abrir o painel de propriedades. Clique em Editar coluna para especificar quais colunas você deseja soltar.
Exclua duas colunas: CustomerAlternateKey e GeographyKey. Clique em Guardar

Construir o modelo
Os dados são divididos 80-20: 80% para treinar um modelo de aprendizado de máquina e 20% para testar o modelo. Algoritmos de "duas classes" são usados neste problema de classificação binária.
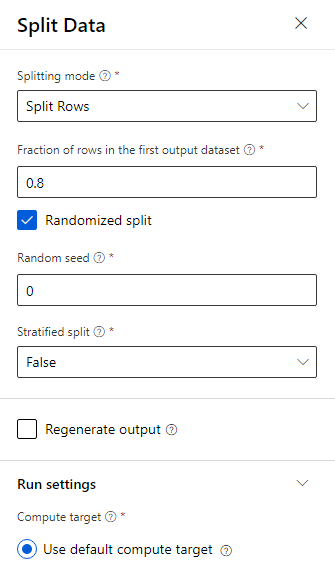
Arraste o componente Dividir dados para a tela.
No painel de propriedades, digite 0.8 para Fração de linhas no primeiro conjunto de dados de saída.
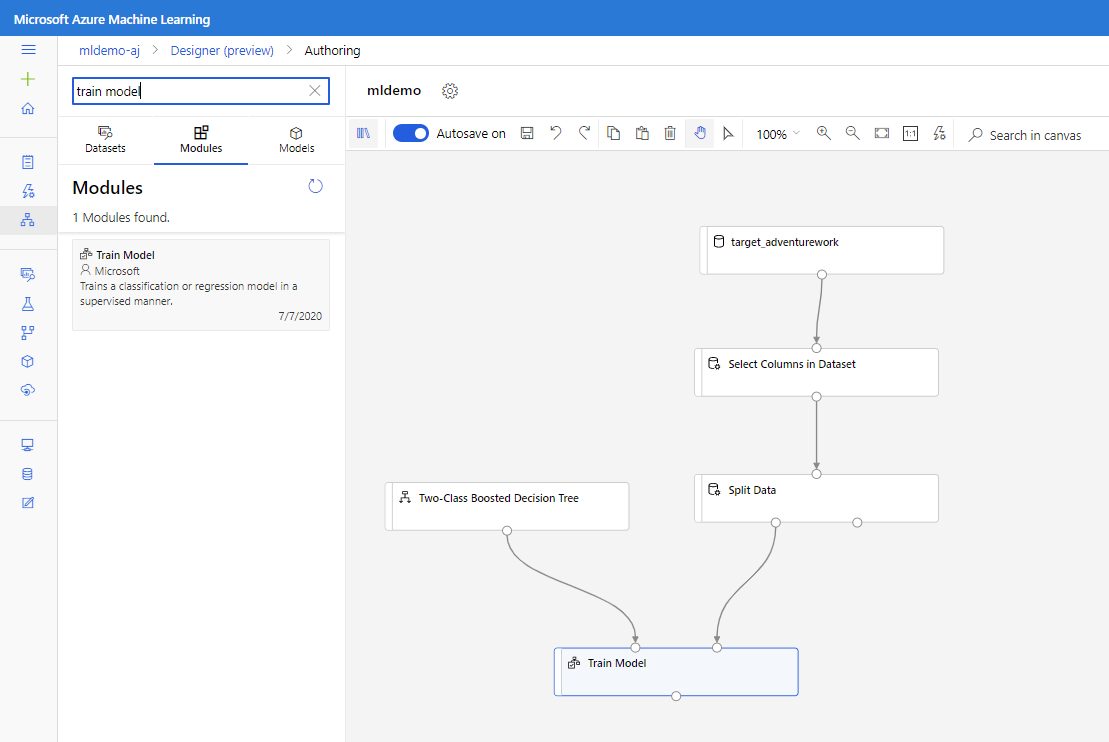
Arraste o componente Árvore decisória impulsionada de duas classes para a tela.
Arraste o componente Train Model para a tela. Especifique as entradas conectando-as aos componentes Árvore de Decisão Impulsionada de Duas Classes (algoritmo ML) e Dados Divididos (dados para treinar o algoritmo).
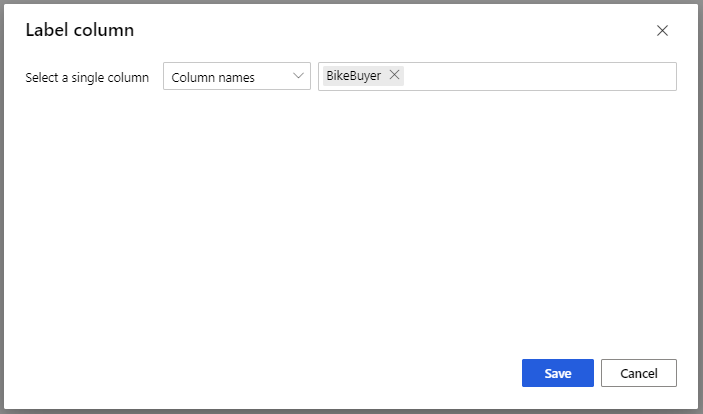
Para Modelo de Trem, na opção Coluna Rótulo no painel Propriedades, selecione Editar coluna. Selecione a coluna BikeBuyer como a coluna para prever e selecione Guardar.
Classificar o modelo
Agora, teste o desempenho do modelo nos dados de teste. Dois algoritmos diferentes serão comparados para ver qual deles tem melhor desempenho. Siga os passos abaixo:
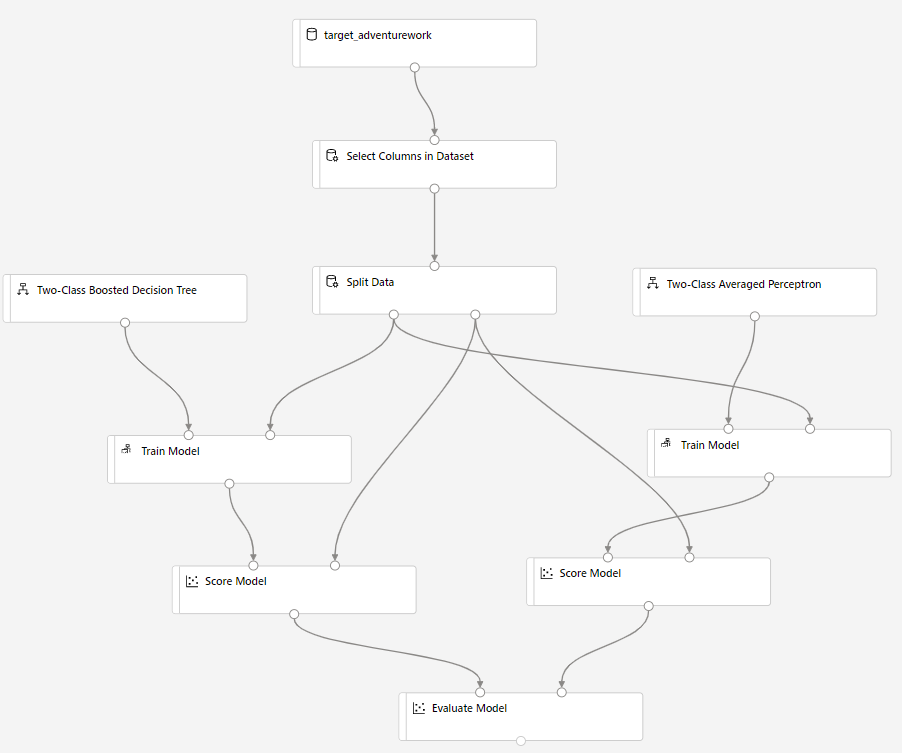
Arraste o componente Modelo de pontuação para a tela e conecte-o aos componentes Train Model e Split Data .
Arraste o Perceptron Bayes Averaged de duas classes para a tela do experimento. Você comparará o desempenho desse algoritmo em comparação com a Árvore de Decisão Impulsionada de Duas Classes.
Copie e cole os componentes Train Model e Score Model na tela.
Arraste o componente Avaliar modelo para a tela para comparar os dois algoritmos.
Clique em enviar para configurar a execução do pipeline.
Quando a execução terminar, clique com o botão direito do mouse no componente Avaliar modelo e clique em Visualizar resultados da avaliação.
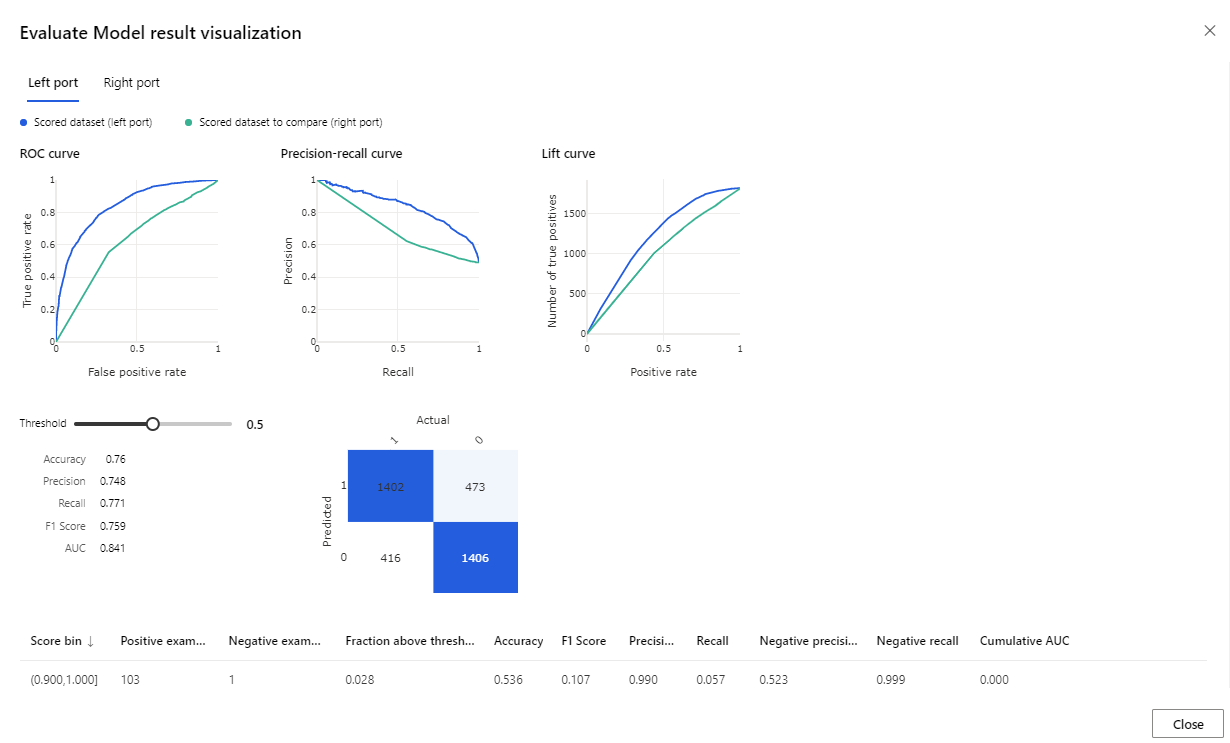

As métricas fornecidas são a curva ROC, diagrama de recordação de precisão e curva de elevação. Olhe para essas métricas para ver que o primeiro modelo teve um desempenho melhor do que o segundo. Para ver o que o primeiro modelo previu, clique com o botão direito do mouse no componente Modelo de pontuação e clique em Visualizar conjunto de dados de pontuação para ver os resultados previstos.
Você verá mais duas colunas adicionadas ao seu conjunto de dados de teste.
- Probabilidades Classificadas: a probabilidade de um cliente ser comprador de uma bicicleta.
- Etiquetas Classificadas: a classificação efetuada pelo modelo – comprador de bicicleta (1) ou não (0). Este limiar de probabilidade para etiquetas está definido como 50% e pode ser ajustado.
Compare a coluna BikeBuyer (real) com as Etiquetas pontuadas (previsão), para ver o desempenho do modelo. Em seguida, você pode usar esse modelo para fazer previsões para novos clientes. Você pode publicar esse modelo como um serviço Web ou gravar os resultados no Azure Synapse.
Próximos passos
Para saber mais sobre o Azure Machine Learning, consulte Introdução ao Machine Learning no Azure.
Saiba mais sobre a pontuação integrada no armazém de dados, aqui.