O que é o Apache Spark no Azure Synapse Analytics?
O Apache Spark é um framework de processamento paralelo que suporta o processamento dentro da memória para melhorar o desempenho de aplicações de análise de macrodados. O Apache Spark no Azure Synapse Analytics é uma das implementações da Microsoft do Apache Spark na cloud. O Azure Synapse facilita a criação e configuração de um conjunto do Apache Spark sem servidor no Azure. Os conjuntos do Spark no Azure Synapse são compatíveis com o Armazenamento do Azure e o Armazenamento do Azure Data Lake Generation 2. Por isso, pode utilizá-los para processar os dados armazenados no Azure.
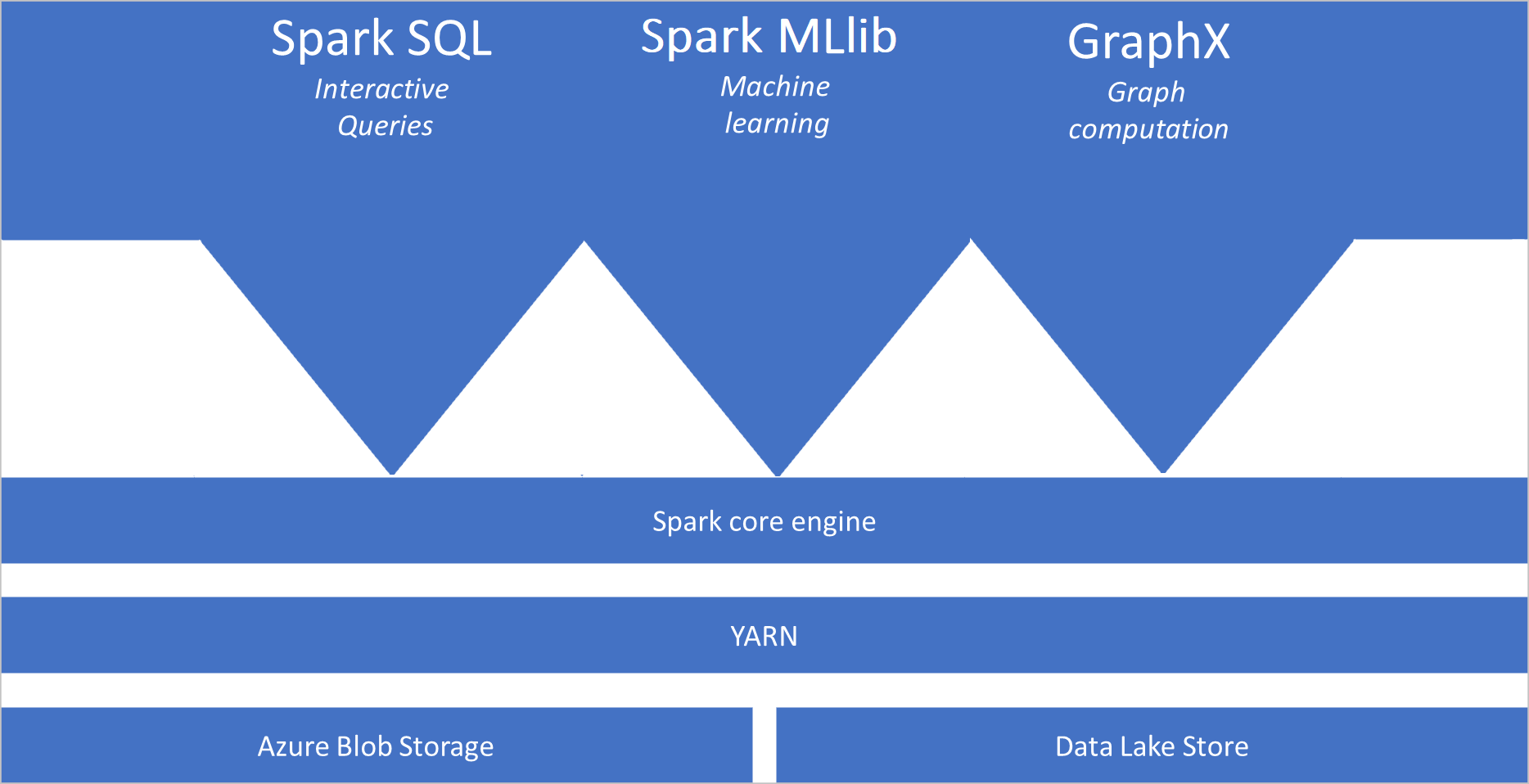
O que é o Apache Spark
O Apache Spark disponibiliza primitivos para a computação de cluster na memória. Um trabalho do Spark pode carregar e colocar em cache dados na memória e consultá-los repetidamente. A computação em memória é mais rápida do que as aplicações baseadas em disco. Também pode integrar o Apache Spark com várias linguagens de programação, o que lhe permite manipular conjuntos de dados distribuídos, como coleções locais. Não é necessário estruturar tudo como operações de mapa e redução. Você pode aprender mais com o vídeo Apache Spark for Synapse.
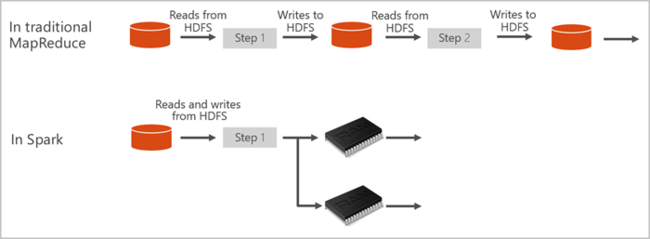
Os pools de faíscas no Azure Synapse oferecem um serviço Spark totalmente gerenciado. Os benefícios da criação de um pool do Spark no Azure Synapse Analytics estão listados aqui.
| Funcionalidade | Description |
|---|---|
| Rapidez e eficiência | As instâncias do Spark começam em aproximadamente 2 minutos para menos de 60 nós e aproximadamente 5 minutos para mais de 60 nós. A instância é desligada, por padrão, 5 minutos após a execução do último trabalho, a menos que seja mantida ativa por uma conexão de bloco de anotações. |
| Facilidade de criação | Você pode criar um novo pool do Spark no Azure Synapse em minutos usando o portal do Azure, o Azure PowerShell ou o SDK do Synapse Analytics .NET. Consulte Introdução aos pools do Spark no Azure Synapse Analytics. |
| Facilidade de utilização | O Synapse Analytics inclui um bloco de anotações personalizado derivado do nteract. Pode utilizar estes blocos de notas para o processamento e a visualização de dados interativos. |
| APIs REST | O Spark no Azure Synapse Analytics inclui o Apache Livy, um servidor de trabalho Spark baseado em API REST para enviar e monitorar trabalhos remotamente. |
| Suporte para o Azure Data Lake Storage Generation 2 | Os pools de faíscas no Azure Synapse podem usar o Azure Data Lake Storage Generation 2 e o armazenamento BLOB. Para obter mais informações sobre o Armazenamento Data Lake, consulte Visão geral do Armazenamento do Azure Data Lake |
| Integração com IDEs de terceiros | O Azure Synapse fornece um plug-in IDE para o IntelliJ IDEA da JetBrains que é útil para criar e enviar aplicativos para um pool do Spark. |
| Bibliotecas Anaconda pré-carregadas | Os pools de faíscas no Azure Synapse vêm com bibliotecas Anaconda pré-instaladas. A Anaconda fornece cerca de 200 bibliotecas para aprendizado de máquina, análise de dados, visualização e outras tecnologias. |
| Escalabilidade | O Apache Spark nos pools do Azure Synapse pode ter o Auto-Scale habilitado, para que os pools sejam dimensionados adicionando ou removendo nós conforme necessário. Além disso, os conjuntos do Spark podem ser encerrados sem perda de dados, uma vez que todos os dados estão armazenados no Armazenamento do Azure ou no Data Lake Storage. |
Os pools de faíscas no Azure Synapse incluem os seguintes componentes que estão disponíveis nos pools por padrão:
- Spark Core. Inclui o Apache Spark Core, o Spark SQL, o GraphX e o MLlib.
- Anaconda
- Apache Lívio
- Caderno Nteract
Arquitetura da piscina de faíscas
Os aplicativos Spark são executados como conjuntos independentes de processos em um pool, coordenados SparkContext pelo objeto em seu programa principal, chamado de programa de driver.
O SparkContext pode se conectar ao gerenciador de cluster, que aloca recursos entre aplicativos. O gerenciador de cluster é o Apache Hadoop YARN. Uma vez conectado, o Spark adquire executores em nós no pool, que são processos que executam cálculos e armazenam dados para seu aplicativo. Em seguida, ele envia o código do seu aplicativo, definido por arquivos JAR ou Python passados para SparkContext, para os executores. Finalmente, SparkContext envia tarefas para os executores executarem.
O SparkContext executa a função principal do usuário e executa as várias operações paralelas nos nós. Em seguida, o SparkContext recolhe os resultados das operações. Os nós leem e gravam dados de e para o sistema de arquivos. Os nós também armazenam em cache dados transformados na memória como RDDs (Resilient Distributed Datasets).
O SparkContext se conecta ao pool Spark e é responsável por converter um aplicativo em um gráfico acíclico direcionado (DAG). O gráfico consiste em tarefas individuais que são executadas dentro de um processo executor nos nós. Cada aplicativo recebe seus próprios processos executores, que permanecem ativos durante todo o aplicativo e executam tarefas em vários threads.
Casos de uso do Apache Spark no Azure Synapse Analytics
Os pools de faíscas no Azure Synapse Analytics habilitam os seguintes cenários principais:
- Engenharia de Dados/Preparação de Dados
O Apache Spark inclui muitos recursos de linguagem para dar suporte à preparação e ao processamento de grandes volumes de dados para que eles possam ser mais valiosos e, em seguida, consumidos por outros serviços dentro do Azure Synapse Analytics. Isso é habilitado por meio de várias linguagens (C#, Scala, PySpark, Spark SQL) e bibliotecas fornecidas para processamento e conectividade.
- Machine Learning
O Apache Spark vem com MLlib, uma biblioteca de aprendizado de máquina construída sobre o Spark que você pode usar a partir de um pool do Spark no Azure Synapse Analytics. Os pools de faíscas no Azure Synapse Analytics também incluem o Anaconda, uma distribuição Python com vários pacotes para ciência de dados, incluindo aprendizado de máquina. Quando combinado com o suporte incorporado para blocos de notas, tem um ambiente para criar aplicações de machine learning.
- Streaming de dados
O Synapse Spark dá suporte ao streaming estruturado do Spark, desde que você esteja executando a versão com suporte da versão de tempo de execução do Azure Synapse Spark. Todos os postos de trabalho são suportados para viver durante sete dias. Isso se aplica a trabalhos em lote e streaming e, geralmente, os clientes automatizam o processo de reinicialização usando o Azure Functions.
Conteúdos relacionados
Use os seguintes artigos para saber mais sobre o Apache Spark no Azure Synapse Analytics:
- Guia de início rápido: criar um pool de faíscas no Azure Synapse
- Guia de início rápido: criar um bloco de anotações do Apache Spark
- Tutorial: Aprendizado de máquina usando o Apache Spark
Nota
Parte da documentação oficial do Apache Spark depende do uso do console do Spark, que não está disponível no Azure Synapse Spark. Em alternativa, utilize o bloco de notas ou as experiências do IntelliJ.