Tutorial: Criar definição de trabalho do Apache Spark no Synapse Studio
Este tutorial demonstra como usar o Synapse Studio para criar definições de trabalho do Apache Spark e, em seguida, enviá-las para um pool do Apache Spark sem servidor.
Este tutorial abrange as seguintes tarefas:
- Criar uma definição de trabalho do Apache Spark para o PySpark (Python)
- Criar uma definição de trabalho do Apache Spark para o Spark (Scala)
- Criar uma definição de trabalho do Apache Spark para o .NET Spark (C#/F#)
- Criar definição de trabalho importando um arquivo JSON
- Exportando um arquivo de definição de trabalho do Apache Spark para local
- Enviar uma definição de trabalho do Apache Spark como um trabalho em lote
- Adicionar uma definição de trabalho do Apache Spark ao pipeline
Pré-requisitos
Antes de começar este tutorial, certifique-se de que cumpre os seguintes requisitos:
- Um espaço de trabalho do Azure Synapse Analytics. Para obter instruções, consulte Criar um espaço de trabalho do Azure Synapse Analytics.
- Um pool Apache Spark sem servidor.
- Uma conta de armazenamento ADLS Gen2. Você precisa ser o Contribuidor de Dados de Blob de Armazenamento do sistema de arquivos ADLS Gen2 com o qual deseja trabalhar. Se não estiver, você precisa adicionar a permissão manualmente.
- Se você não quiser usar o armazenamento padrão do espaço de trabalho, vincule a conta de armazenamento ADLS Gen2 necessária no Synapse Studio.
Criar uma definição de trabalho do Apache Spark para o PySpark (Python)
Nesta seção, você cria uma definição de trabalho do Apache Spark para o PySpark (Python).
Abra o Synapse Studio.
Você pode ir para Arquivos de exemplo para criar definições de trabalho do Apache Spark para baixar arquivos de exemplo para python.zip, descompactar o pacote compactado e extrair os arquivos wordcount.py e shakespeare.txt .
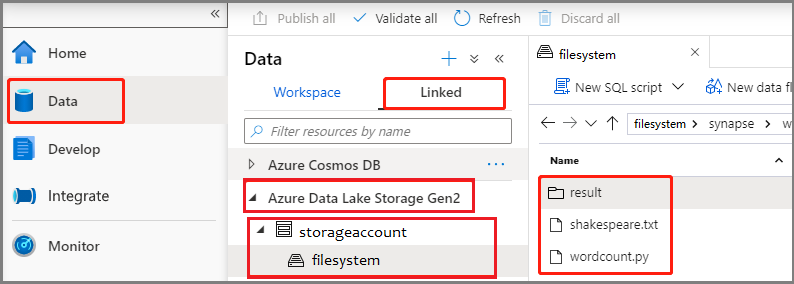
Selecione Data ->Linked ->Azure Data Lake Storage Gen2 e carregue wordcount.py e shakespeare.txt em seu sistema de arquivos ADLS Gen2.
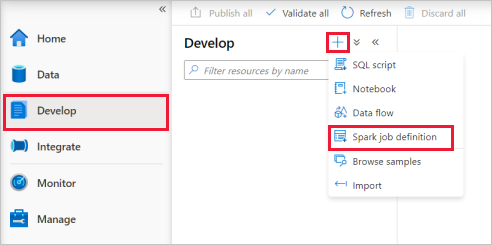
Selecione Desenvolver hub, selecione o ícone '+' e selecione Definição de trabalho do Spark para criar uma nova definição de trabalho do Spark.
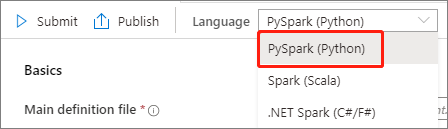
Selecione PySpark (Python) na lista suspensa Idioma na janela principal de definição de trabalho do Apache Spark.
Preencha as informações para a definição do trabalho do Apache Spark.
Property Description Nome da definição de trabalho Insira um nome para sua definição de trabalho do Apache Spark. Este nome pode ser atualizado a qualquer momento até ser publicado.
Exemplo:job definition sampleFicheiro de definição principal O arquivo principal usado para o trabalho. Selecione um arquivo PY do seu armazenamento. Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento.
Exemplo:abfss://…/path/to/wordcount.pyArgumentos de linha de comando Argumentos opcionais para o trabalho.
Amostra:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: Dois argumentos para a definição de trabalho de exemplo são separados por um espaço.Ficheiros de referência Arquivos adicionais usados para referência no arquivo de definição principal. Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento. Piscina de faísca O trabalho será enviado para o pool Apache Spark selecionado. Versão do Spark Versão do Apache Spark que o pool do Apache Spark está executando. Executors Número de executores a serem fornecidos no pool especificado do Apache Spark para o trabalho. Tamanho do executor Número de núcleos e memória a serem usados para executores fornecidos no pool especificado do Apache Spark para o trabalho. Tamanho do driver Número de núcleos e memória a serem usados para o driver fornecido no pool Apache Spark especificado para o trabalho. Configuração do Apache Spark Personalize as configurações adicionando as propriedades abaixo. Se você não adicionar uma propriedade, o Azure Synapse usará o valor padrão quando aplicável. 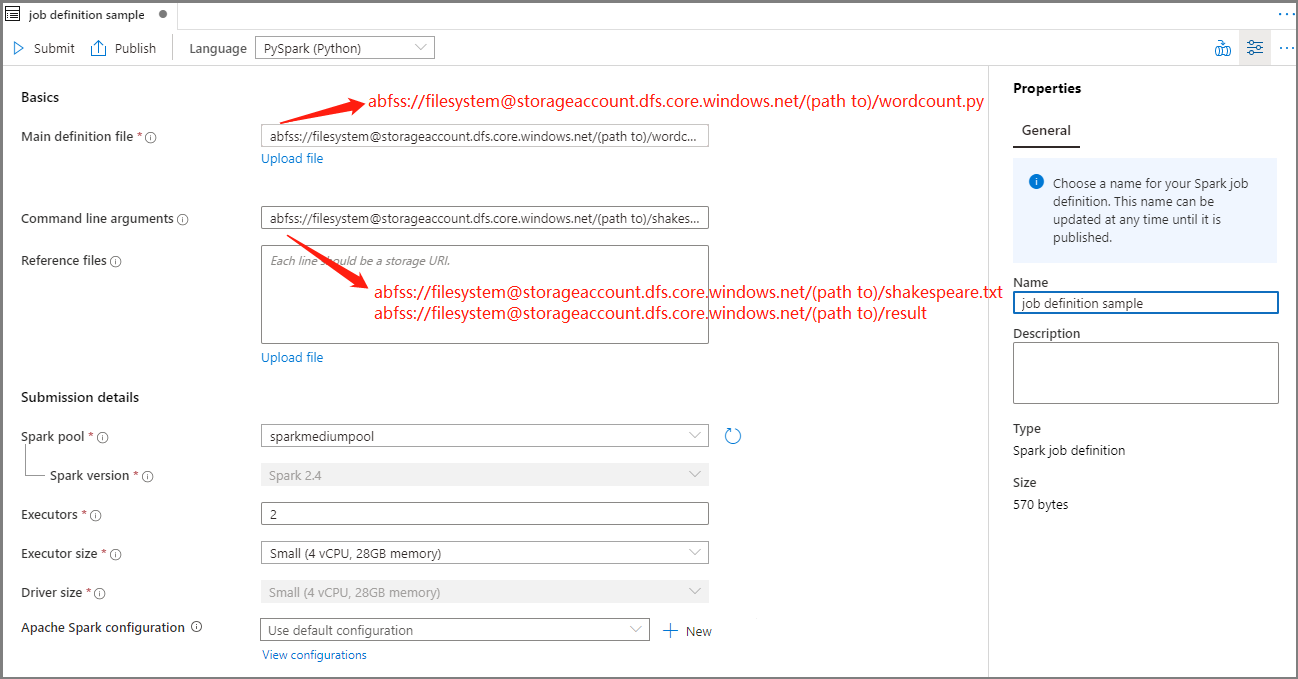
Selecione Publicar para salvar a definição de trabalho do Apache Spark.

Criar uma definição de trabalho do Apache Spark para o Apache Spark(Scala)
Nesta seção, você cria uma definição de trabalho do Apache Spark para o Apache Spark(Scala).
Abra o Azure Synapse Studio.
Você pode ir para Arquivos de exemplo para criar definições de trabalho do Apache Spark para baixar arquivos de exemplo para scala.zip, descompactar o pacote compactado e extrair os arquivos wordcount.jar e shakespeare.txt .
Selecione Data ->Linked ->Azure Data Lake Storage Gen2 e carregue wordcount.jar e shakespeare.txt em seu sistema de arquivos ADLS Gen2.
Selecione Desenvolver hub, selecione o ícone '+' e selecione Definição de trabalho do Spark para criar uma nova definição de trabalho do Spark. (A imagem de exemplo é a mesma que a etapa 4 de Crie uma definição de trabalho do Apache Spark (Python) para o PySpark.)
Selecione Spark(Scala) na lista suspensa Idioma na janela principal de definição de trabalho do Apache Spark.
Preencha as informações para a definição do trabalho do Apache Spark. Você pode copiar as informações de exemplo.
Property Description Nome da definição de trabalho Insira um nome para sua definição de trabalho do Apache Spark. Este nome pode ser atualizado a qualquer momento até ser publicado.
Exemplo:scalaFicheiro de definição principal O arquivo principal usado para o trabalho. Selecione um arquivo JAR do seu armazenamento. Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento.
Exemplo:abfss://…/path/to/wordcount.jarNome da classe principal O identificador totalmente qualificado ou a classe principal que está no arquivo de definição principal.
Exemplo:WordCountArgumentos de linha de comando Argumentos opcionais para o trabalho.
Amostra:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: Dois argumentos para a definição de trabalho de exemplo são separados por um espaço.Ficheiros de referência Arquivos adicionais usados para referência no arquivo de definição principal. Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento. Piscina de faísca O trabalho será enviado para o pool Apache Spark selecionado. Versão do Spark Versão do Apache Spark que o pool do Apache Spark está executando. Executors Número de executores a serem fornecidos no pool especificado do Apache Spark para o trabalho. Tamanho do executor Número de núcleos e memória a serem usados para executores fornecidos no pool especificado do Apache Spark para o trabalho. Tamanho do driver Número de núcleos e memória a serem usados para o driver fornecido no pool Apache Spark especificado para o trabalho. Configuração do Apache Spark Personalize as configurações adicionando as propriedades abaixo. Se você não adicionar uma propriedade, o Azure Synapse usará o valor padrão quando aplicável. 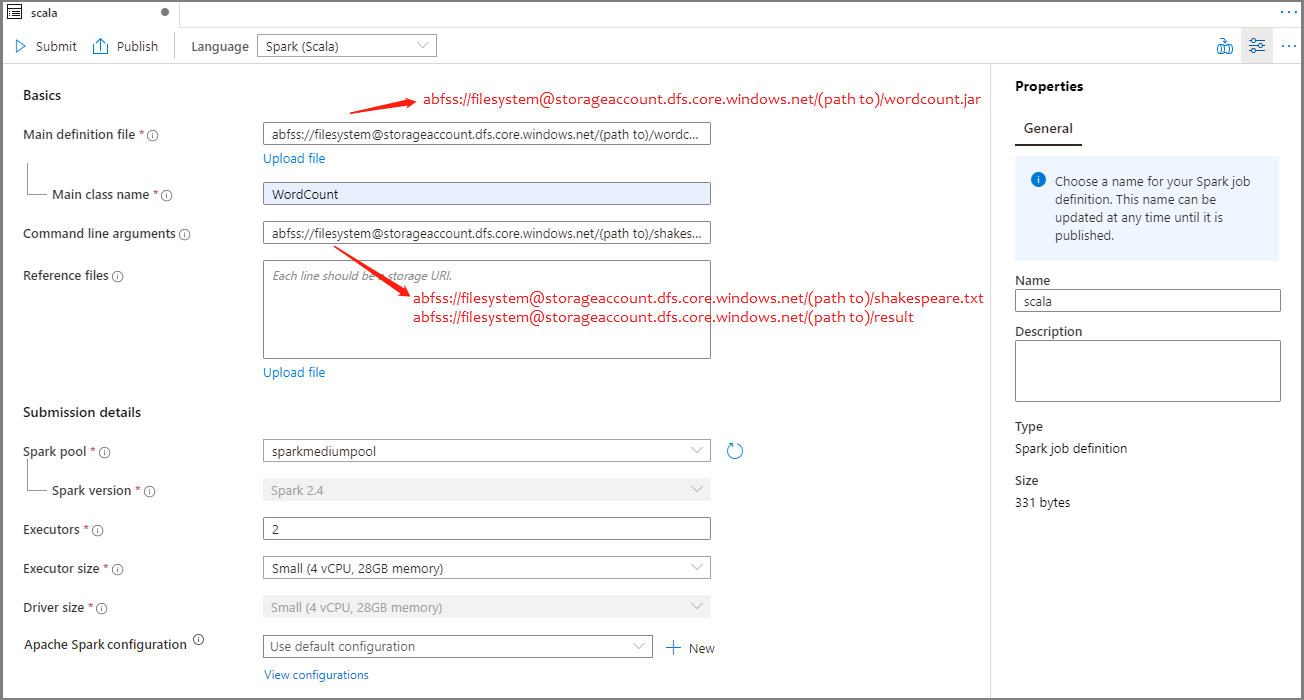
Selecione Publicar para salvar a definição de trabalho do Apache Spark.

Criar uma definição de trabalho do Apache Spark para .NET Spark(C#/F#)
Nesta seção, você cria uma definição de trabalho do Apache Spark para .NET Spark(C#/F#).
Abra o Azure Synapse Studio.
Você pode ir para Arquivos de exemplo para criar definições de trabalho do Apache Spark para baixar arquivos de exemplo para dotnet.zip, descompactar o pacote compactado e extrair os arquivos wordcount.zip e shakespeare.txt .
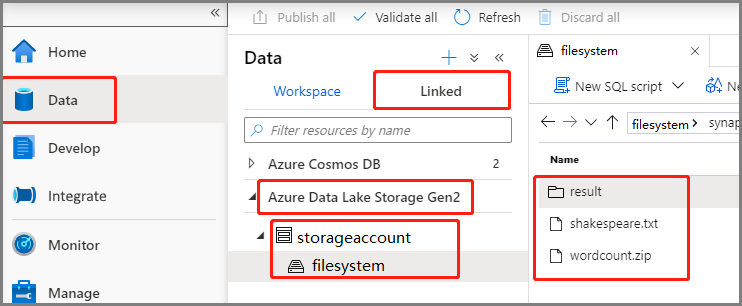
Selecione Data ->Linked ->Azure Data Lake Storage Gen2 e carregue wordcount.zip e shakespeare.txt em seu sistema de arquivos ADLS Gen2.
Selecione Desenvolver hub, selecione o ícone '+' e selecione Definição de trabalho do Spark para criar uma nova definição de trabalho do Spark. (A imagem de exemplo é a mesma que a etapa 4 de Crie uma definição de trabalho do Apache Spark (Python) para o PySpark.)
Selecione .NET Spark(C#/F#) na lista suspensa Idioma na janela principal Apache Spark Job Definition.
Preencha as informações para Apache Spark Job Definition. Você pode copiar as informações de exemplo.
Property Description Nome da definição de trabalho Insira um nome para sua definição de trabalho do Apache Spark. Este nome pode ser atualizado a qualquer momento até ser publicado.
Exemplo:dotnetFicheiro de definição principal O arquivo principal usado para o trabalho. Selecione um arquivo ZIP que contenha seu .NET para o aplicativo Apache Spark (ou seja, o arquivo executável principal, DLLs contendo funções definidas pelo usuário e outros arquivos necessários) do seu armazenamento. Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento.
Exemplo:abfss://…/path/to/wordcount.zipArquivo executável principal O arquivo executável principal no arquivo ZIP de definição principal.
Exemplo:WordCountArgumentos de linha de comando Argumentos opcionais para o trabalho.
Amostra:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: Dois argumentos para a definição de trabalho de exemplo são separados por um espaço.Ficheiros de referência Arquivos adicionais necessários para os nós de trabalho para executar o aplicativo .NET for Apache Spark que não está incluído no arquivo ZIP de definição principal (ou seja, jars dependentes, DLLs de função adicionais definidas pelo usuário e outros arquivos de configuração). Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento. Piscina de faísca O trabalho será enviado para o pool Apache Spark selecionado. Versão do Spark Versão do Apache Spark que o pool do Apache Spark está executando. Executors Número de executores a serem fornecidos no pool especificado do Apache Spark para o trabalho. Tamanho do executor Número de núcleos e memória a serem usados para executores fornecidos no pool especificado do Apache Spark para o trabalho. Tamanho do driver Número de núcleos e memória a serem usados para o driver fornecido no pool Apache Spark especificado para o trabalho. Configuração do Apache Spark Personalize as configurações adicionando as propriedades abaixo. Se você não adicionar uma propriedade, o Azure Synapse usará o valor padrão quando aplicável. 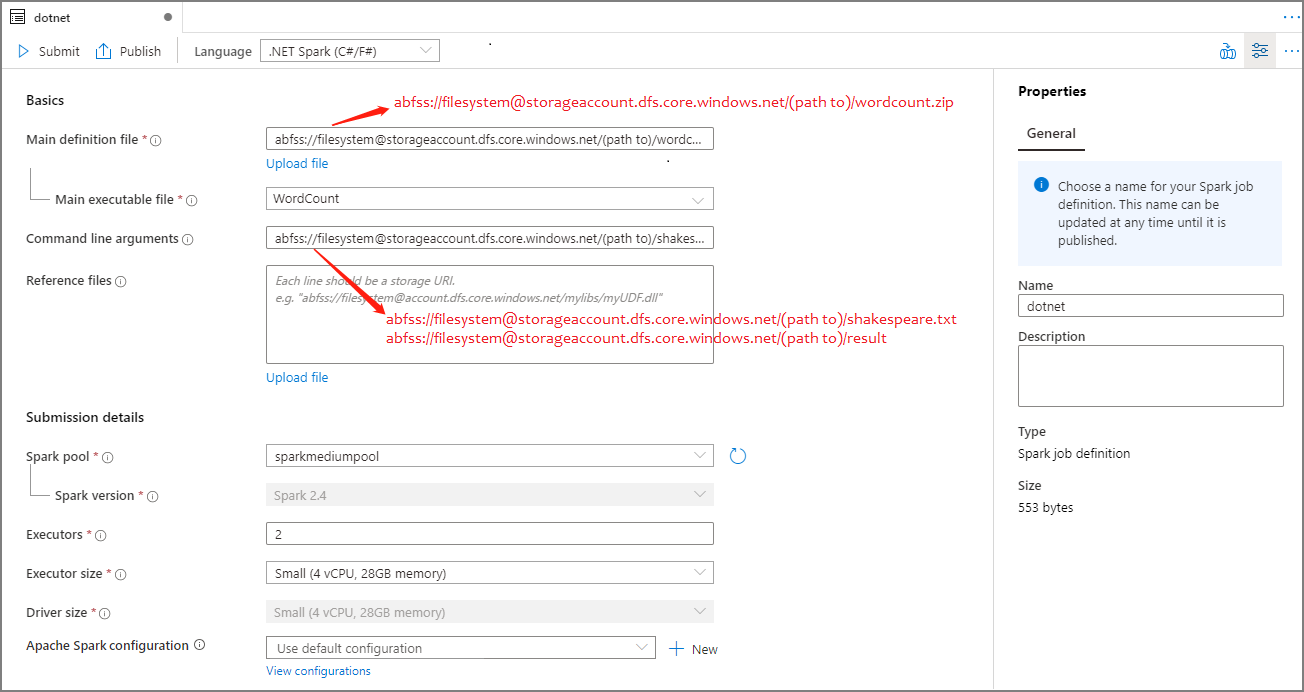
Selecione Publicar para salvar a definição de trabalho do Apache Spark.

Nota
Para a configuração do Apache Spark, se a definição de trabalho do Apache Spark não fizer nada de especial, a configuração padrão será usada ao executar o trabalho.
Criar definição de trabalho do Apache Spark importando um arquivo JSON
Você pode importar um arquivo JSON local existente para o espaço de trabalho do Azure Synapse no menu Ações (...) do Apache Spark job definition Explorer para criar uma nova definição de trabalho do Apache Spark.
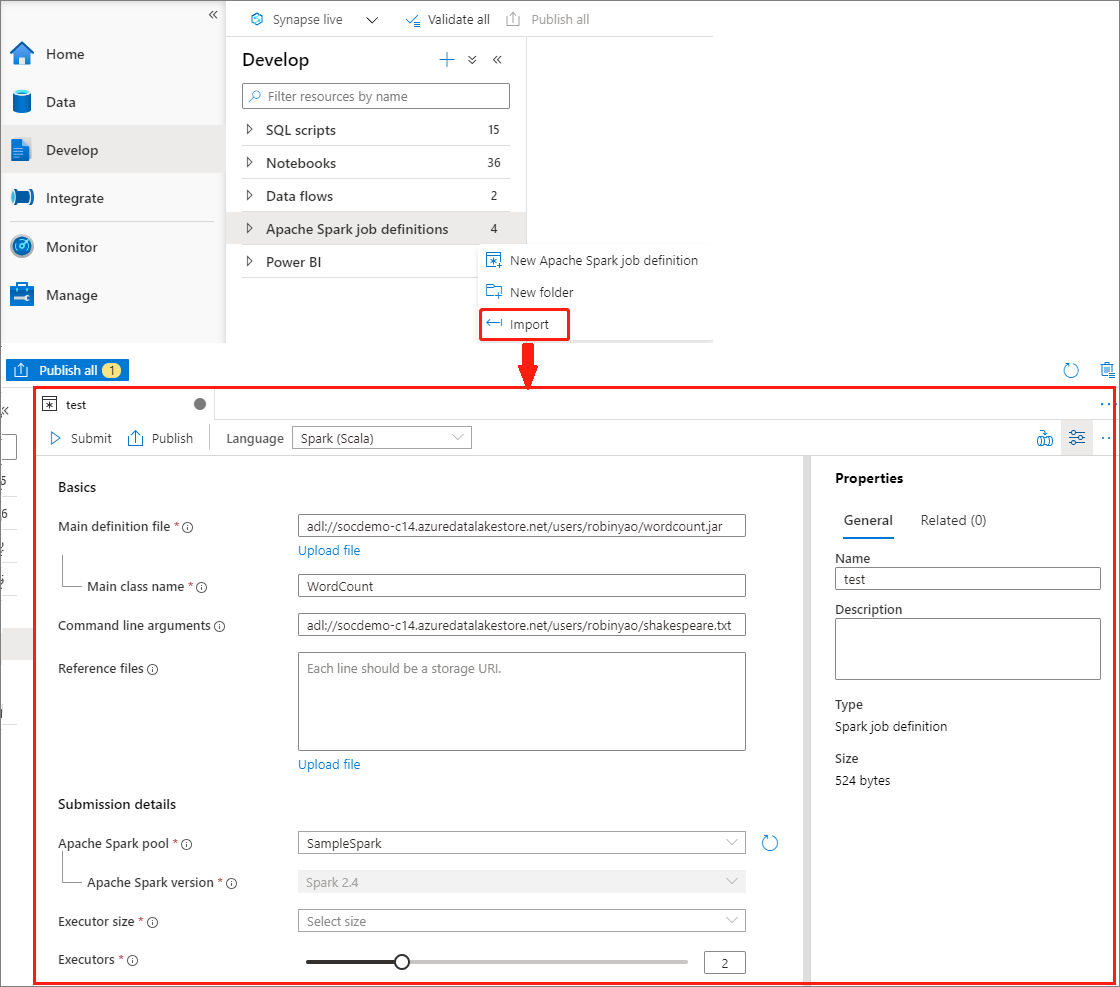
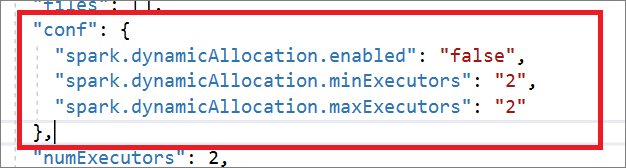
A definição de trabalho do Spark é totalmente compatível com a API Livy. Você pode adicionar parâmetros adicionais para outras propriedades Livy (Livy Docs - API REST (apache.org) no arquivo JSON local. Você também pode especificar os parâmetros relacionados à configuração do Spark na propriedade config, conforme mostrado abaixo. Em seguida, você pode importar o arquivo JSON de volta para criar uma nova definição de trabalho do Apache Spark para seu trabalho em lotes. Exemplo de JSON para importação de definição de faísca:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
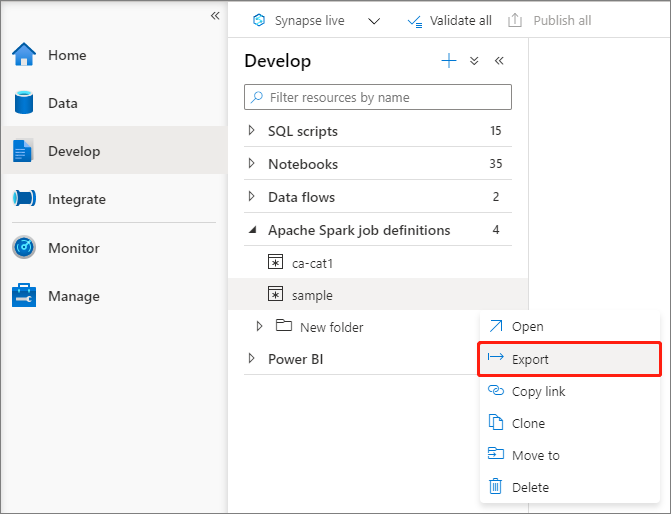
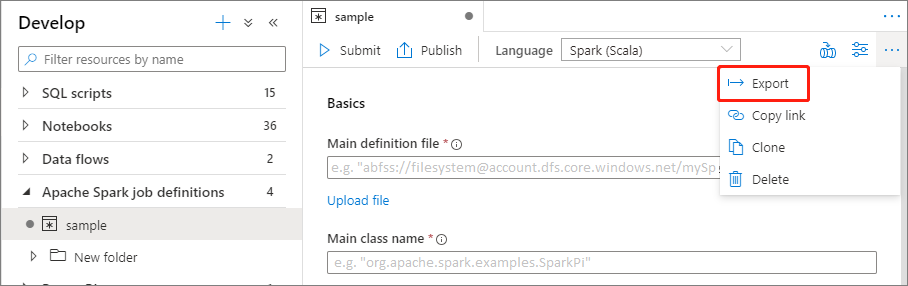
Exportar um arquivo de definição de trabalho existente do Apache Spark
Você pode exportar arquivos de definição de trabalho existentes do Apache Spark para local no menu Ações (...) do Explorador de Arquivos. Você pode atualizar ainda mais o arquivo JSON para propriedades adicionais do Livy e importá-lo de volta para criar uma nova definição de trabalho, se necessário.
Enviar uma definição de trabalho do Apache Spark como um trabalho em lote
Depois de criar uma definição de trabalho do Apache Spark, você pode enviá-la para um pool do Apache Spark. Certifique-se de que é o Contribuidor de Dados de Blob de Armazenamento do sistema de ficheiros ADLS Gen2 com o qual pretende trabalhar. Se não estiver, você precisa adicionar a permissão manualmente.
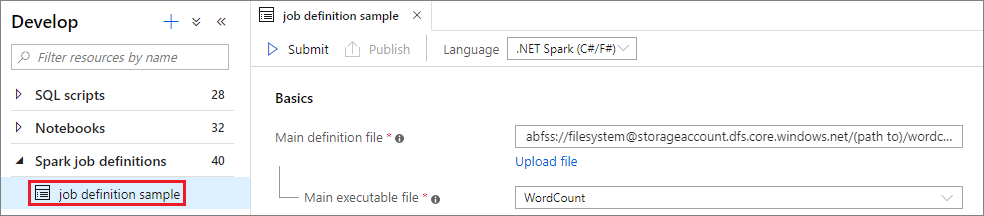
Cenário 1: Enviar definição de trabalho do Apache Spark
Abra uma janela de definição de trabalho do Apache spark selecionando-a.
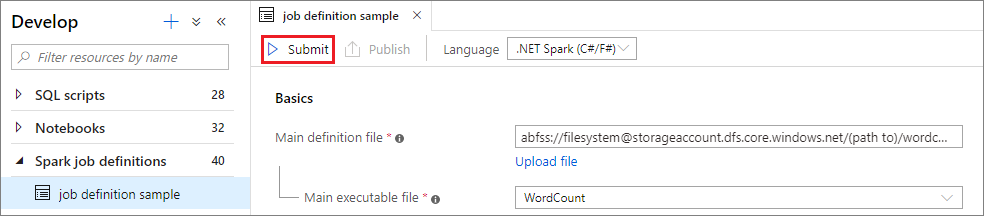
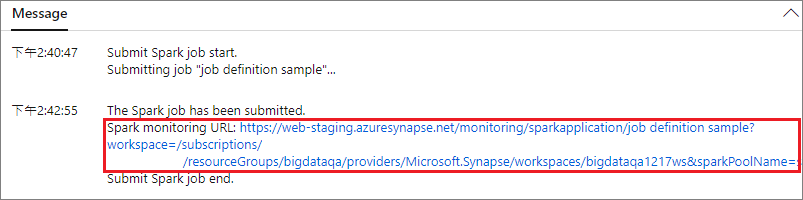
Selecione o botão Enviar para enviar seu projeto para o Apache Spark Pool selecionado. Você pode selecionar a guia URL de monitoramento do Spark para ver o LogQuery do aplicativo Apache Spark.
Cenário 2: Exibir o progresso da execução do trabalho do Apache Spark
Selecione Monitor e, em seguida, selecione a opção de aplicativos Apache Spark. Você pode encontrar o aplicativo Apache Spark enviado.
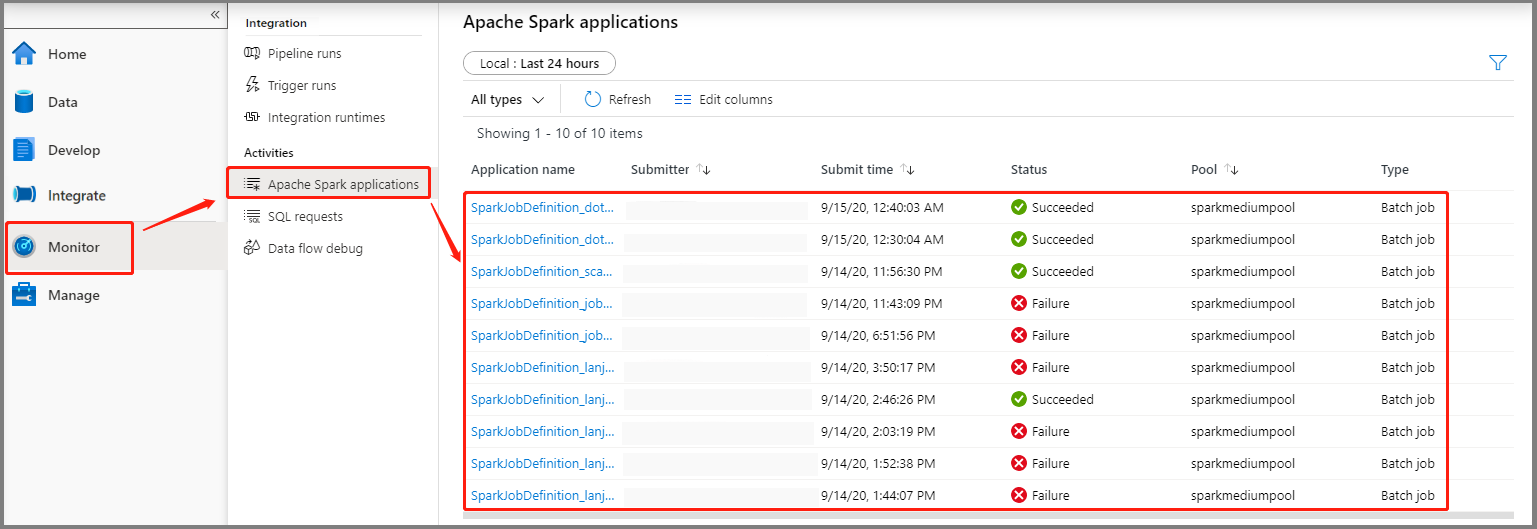
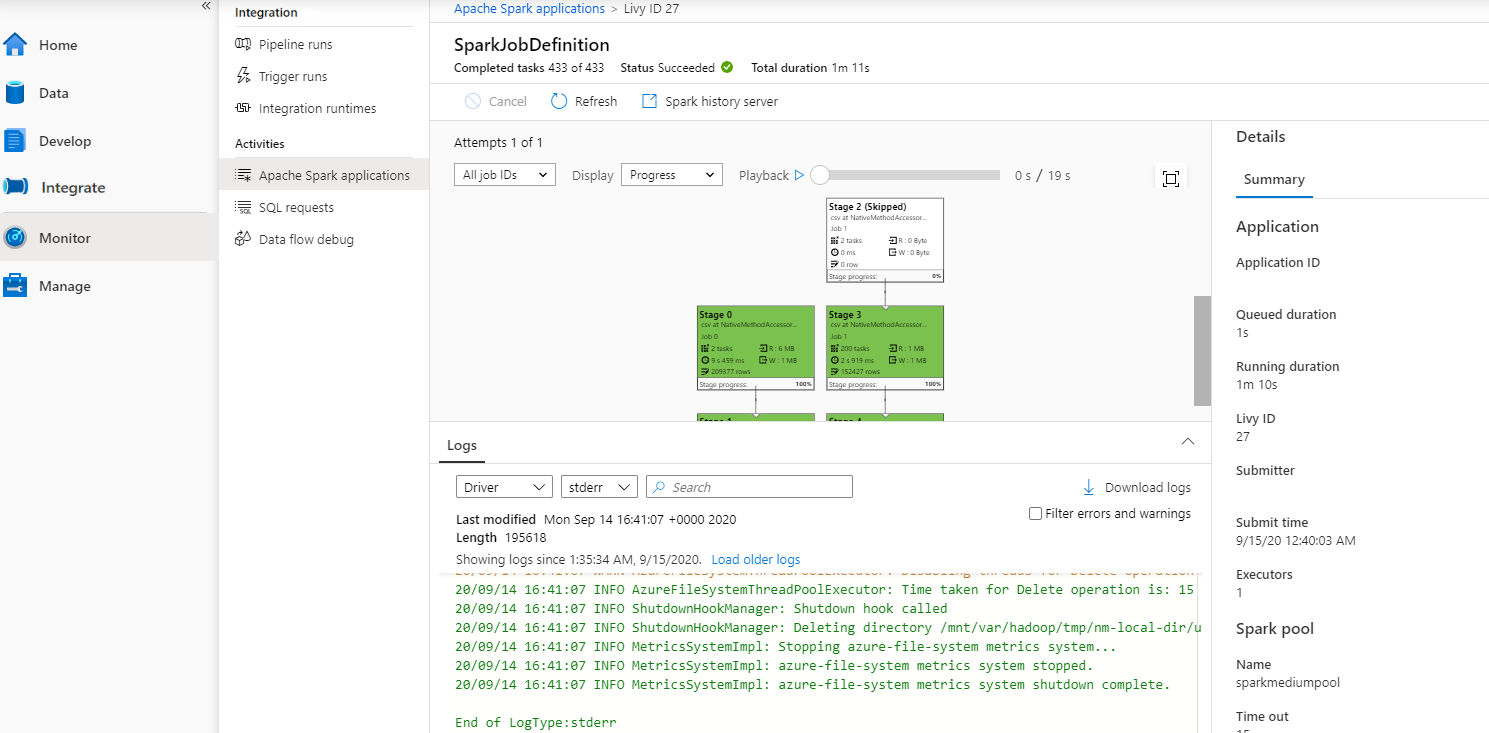
Em seguida, selecione um aplicativo Apache Spark, a janela de trabalho SparkJobDefinition é exibida. Você pode visualizar o progresso da execução do trabalho aqui.
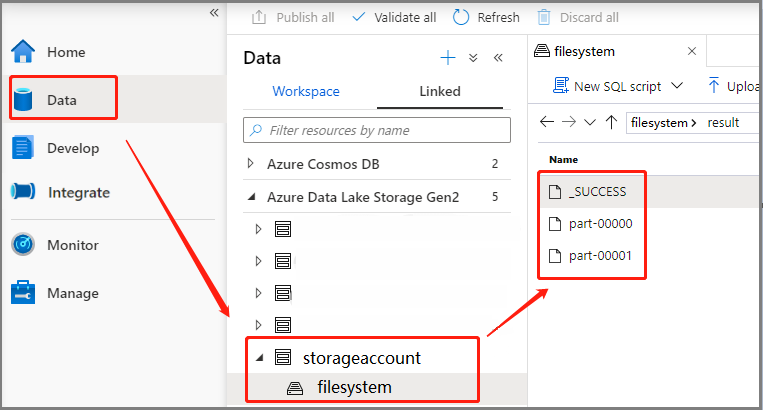
Cenário 3: Verificar arquivo de saída
Selecione Data ->Linked ->Azure Data Lake Storage Gen2 (hozhaobdbj), abra a pasta de resultados criada anteriormente, você pode ir para a pasta de resultados e verificar se a saída foi gerada.
Adicionar uma definição de trabalho do Apache Spark ao pipeline
Nesta seção, você adiciona uma definição de trabalho do Apache Spark ao pipeline.
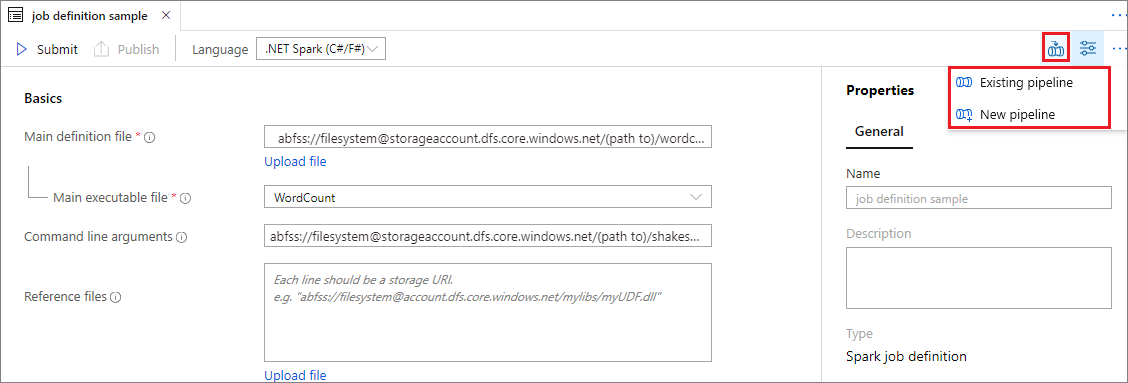
Abra uma definição de trabalho existente do Apache Spark.
Selecione o ícone no canto superior direito da definição de trabalho do Apache Spark, escolha Pipeline existente ou Novo pipeline. Você pode consultar a página Pipeline para obter mais informações.
Próximos passos
Em seguida, você pode usar o Azure Synapse Studio para criar conjuntos de dados do Power BI e gerenciar dados do Power BI. Avance para o artigo Vinculando um espaço de trabalho do Power BI a um espaço de trabalho do Synapse para saber mais.