Tutorial: Treinar um modelo de aprendizado de máquina sem código (preterido)
Você pode enriquecer seus dados em tabelas do Spark com novos modelos de aprendizado de máquina que você treina usando aprendizado de máquina automatizado. No Azure Synapse Analytics, você pode selecionar uma tabela do Spark no espaço de trabalho para usar como um conjunto de dados de treinamento para criar modelos de aprendizado de máquina, e pode fazer isso em uma experiência sem código.
Neste tutorial, você aprenderá a treinar modelos de aprendizado de máquina usando uma experiência livre de código no Synapse Studio. O Synapse Studio é um recurso do Azure Synapse Analytics.
Você usará o aprendizado de máquina automatizado no Aprendizado de Máquina do Azure, em vez de codificar a experiência manualmente. O tipo de modelo que você treina depende do problema que você está tentando resolver. Para este tutorial, você usará um modelo de regressão para prever as tarifas de táxi do conjunto de dados de táxi da cidade de Nova York.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Aviso
- A partir de 29 de setembro de 2023, o Azure Synapse descontinuará o suporte oficial para o Spark 2.4 Runtimes. Após 29 de setembro de 2023, não abordaremos nenhum tíquete de suporte relacionado ao Spark 2.4. Não haverá pipeline de lançamento para bugs ou correções de segurança para o Spark 2.4. A utilização do Spark 2.4 após a data de corte do suporte é realizada por sua conta e risco. Desencorajamos fortemente o seu uso continuado devido a potenciais preocupações de segurança e funcionalidade.
- Como parte do processo de substituição do Apache Spark 2.4, gostaríamos de notificá-lo de que o AutoML no Azure Synapse Analytics também será preterido. Isso inclui a interface low code e as APIs usadas para criar avaliações do AutoML por meio do código.
- Observe que a funcionalidade AutoML estava disponível exclusivamente através do tempo de execução do Spark 2.4.
- Para os clientes que desejam continuar aproveitando os recursos do AutoML, recomendamos salvar seus dados em sua conta do Azure Data Lake Storage Gen2 (ADLSg2). A partir daí, você pode acessar diretamente a experiência do AutoML por meio do Azure Machine Learning (AzureML). Mais informações sobre essa solução alternativa estão disponíveis aqui.
Pré-requisitos
- Um espaço de trabalho do Azure Synapse Analytics. Verifique se ele tem uma conta de armazenamento do Azure Data Lake Storage Gen2 configurada como o armazenamento padrão. Para o sistema de arquivos Data Lake Storage Gen2 com o qual você trabalha, certifique-se de ser o Colaborador de Dados de Blob de Armazenamento.
- Um pool do Apache Spark (versão 2.4) em seu espaço de trabalho do Azure Synapse Analytics. Para obter detalhes, consulte Guia de início rápido: criar um pool Apache Spark sem servidor usando o Synapse Studio.
- Um serviço vinculado do Azure Machine Learning em seu espaço de trabalho do Azure Synapse Analytics. Para obter detalhes, consulte Guia de início rápido: criar um novo serviço vinculado do Azure Machine Learning no Azure Synapse Analytics.
Inicie sessão no portal do Azure
Inicie sessão no portal do Azure.
Criar uma tabela do Spark para o conjunto de dados de treinamento
Para este tutorial, você precisa de uma tabela Spark. O bloco de anotações a seguir cria um:
Baixe o bloco de anotações Create-Spark-Table-NYCTaxi- Data.ipynb.
Importe o bloco de anotações para o Synapse Studio.
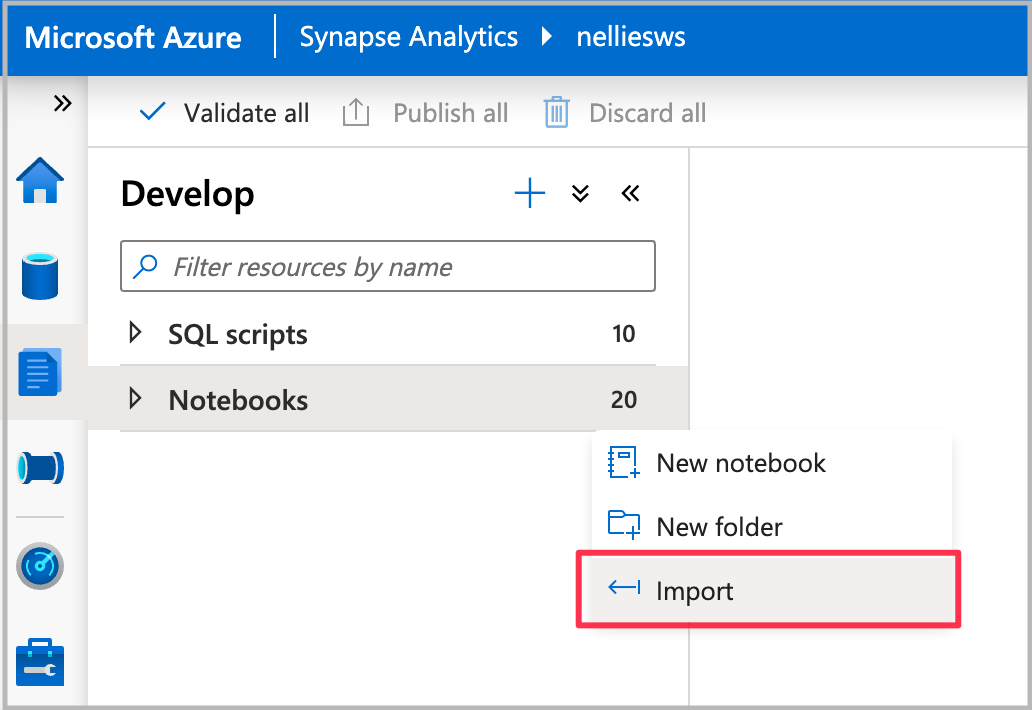
Selecione o pool de faíscas que você deseja usar e, em seguida, selecione Executar tudo. Esta etapa obtém dados de táxi de Nova York do conjunto de dados aberto e salva os dados em seu banco de dados padrão do Spark.

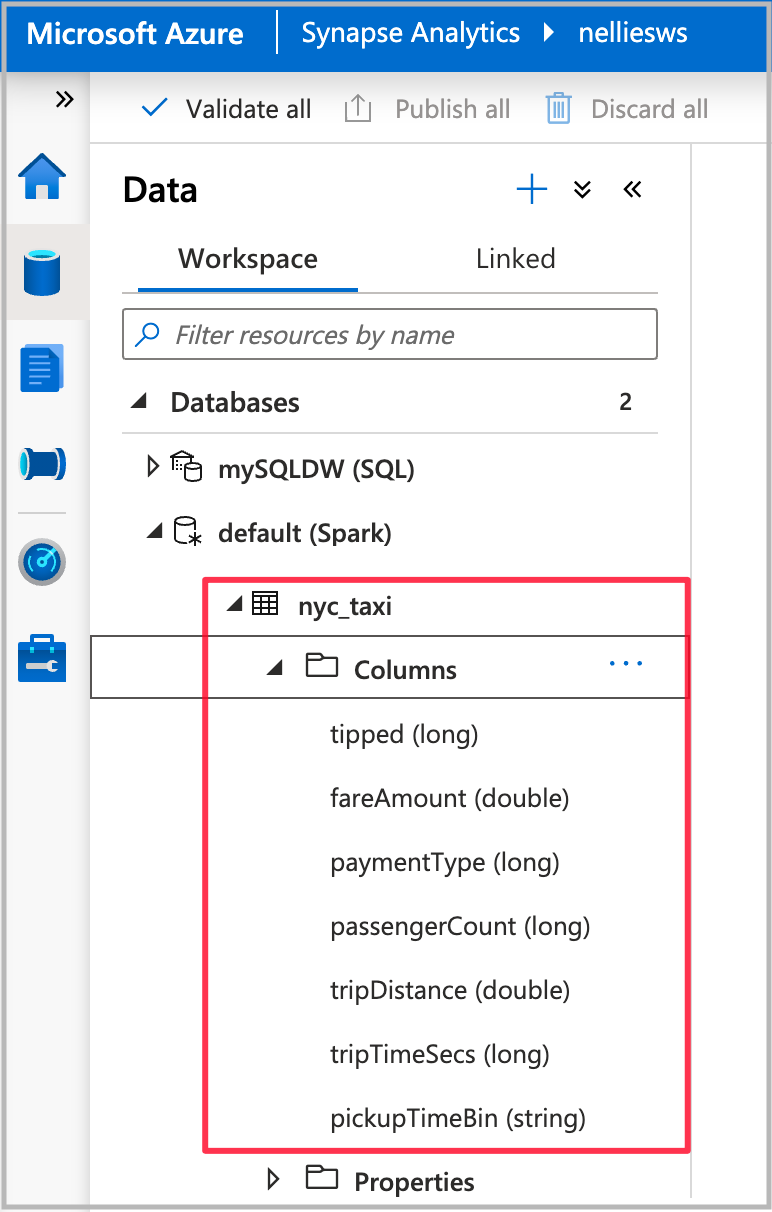
Após a conclusão da execução do bloco de anotações, você verá uma nova tabela do Spark no banco de dados padrão do Spark. Em Dados, localize a tabela chamada nyc_taxi.
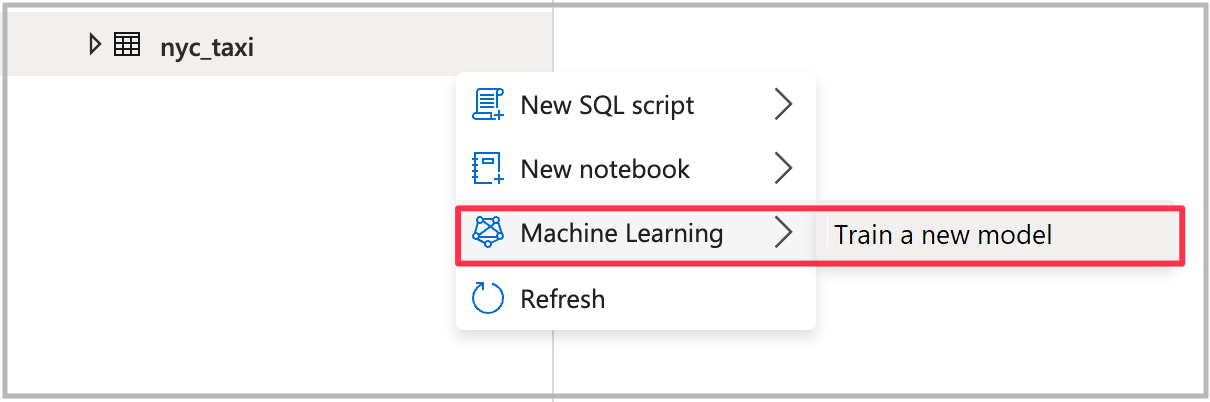
Abra o assistente de aprendizado de máquina automatizado
Para abrir o assistente, clique com o botão direito do mouse na tabela Spark que você criou na etapa anterior. Em seguida, selecione Machine Learning>Train um novo modelo.
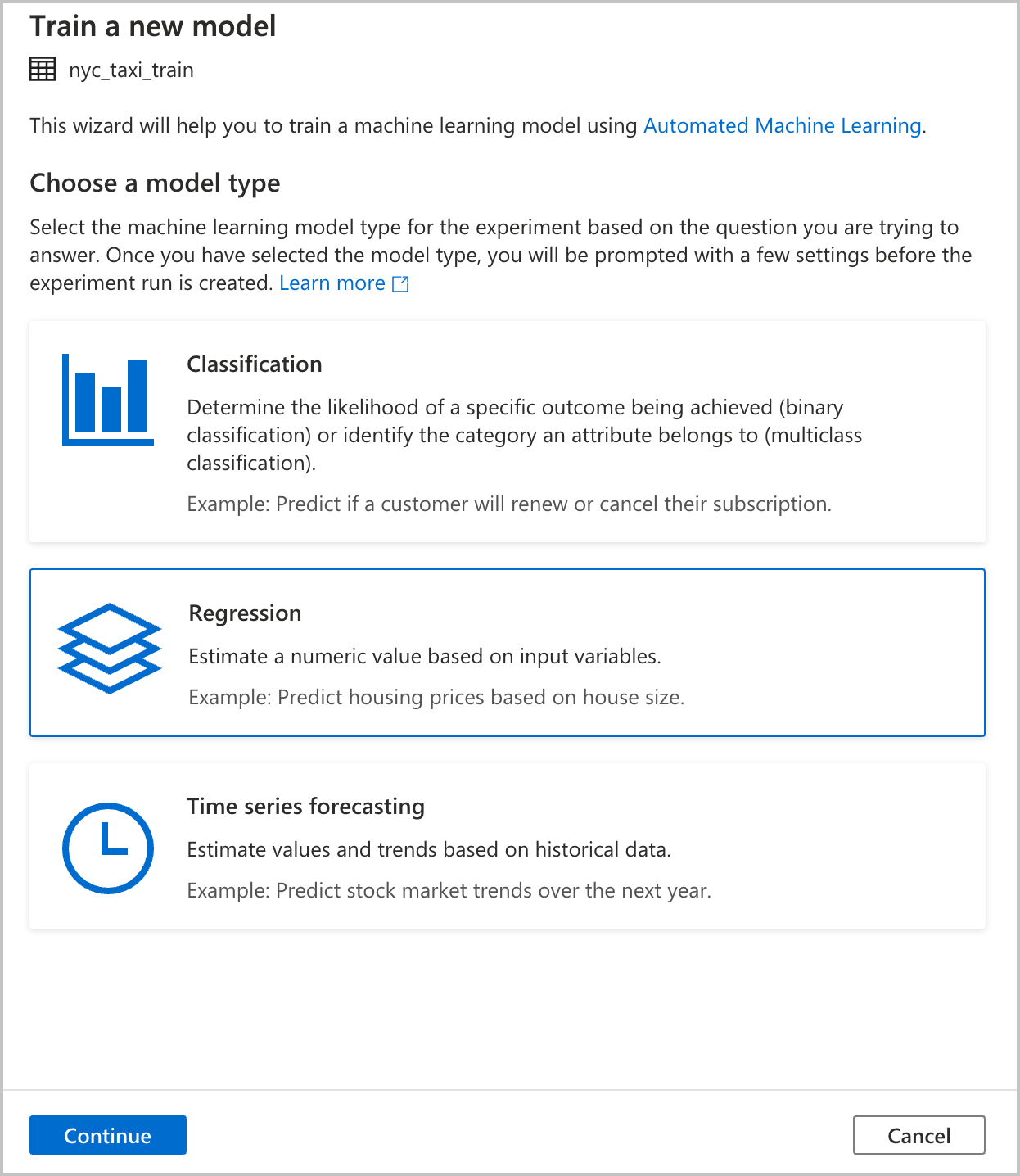
Escolher um tipo de modelo
Selecione o tipo de modelo de aprendizado de máquina para o experimento, com base na pergunta que você está tentando responder. Como o valor que você está tentando prever é numérico (tarifas de táxi), selecione Regressão aqui. Em seguida, selecione Continuar.
Configurar a experiência
Forneça detalhes de configuração para criar um experimento de aprendizado de máquina automatizado executado no Azure Machine Learning. Esta corrida treina vários modelos. O melhor modelo de uma execução bem-sucedida é registrado no registro do modelo do Azure Machine Learning.
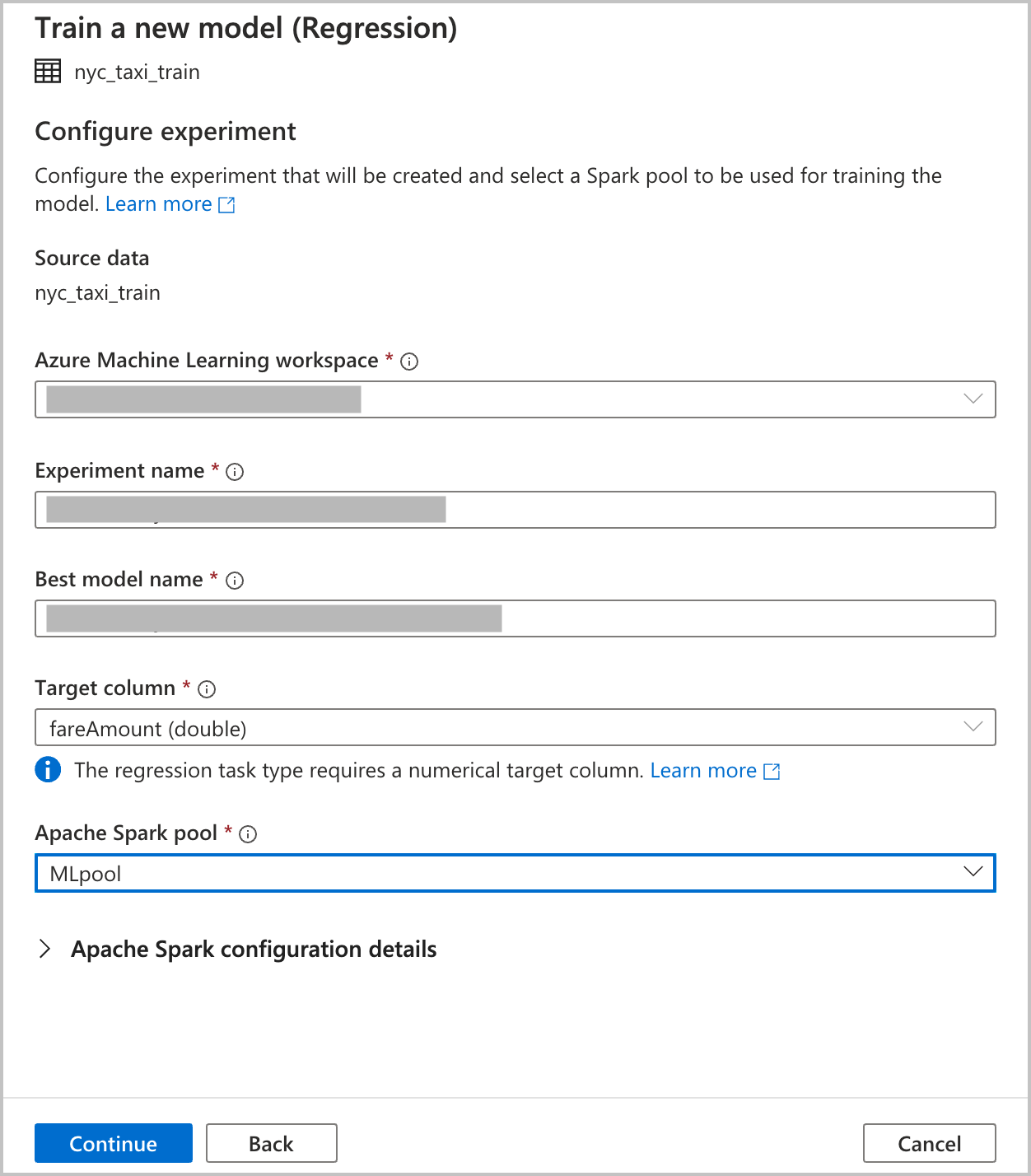
Espaço de trabalho do Azure Machine Learning: um espaço de trabalho do Azure Machine Learning é necessário para criar uma execução de experimento de aprendizado de máquina automatizado. Você também precisa vincular seu espaço de trabalho do Azure Synapse Analytics ao espaço de trabalho do Azure Machine Learning usando um serviço vinculado. Depois de cumprir todos os pré-requisitos, você pode especificar o espaço de trabalho do Azure Machine Learning que deseja usar para essa execução automatizada.
Nome do experimento: especifique o nome do experimento. Ao enviar uma execução automatizada de aprendizado de máquina, você fornece um nome de experimento. As informações para a execução são armazenadas sob esse experimento no espaço de trabalho do Azure Machine Learning. Essa experiência cria um novo experimento por padrão e gera um nome proposto, mas você também pode fornecer o nome de um experimento existente.
Melhor nome do modelo: especifique o nome do melhor modelo da execução automatizada. O melhor modelo recebe esse nome e é salvo no registro do modelo do Azure Machine Learning automaticamente após essa execução. Uma execução automatizada de aprendizado de máquina cria muitos modelos de aprendizado de máquina. Com base na métrica principal selecionada em uma etapa posterior, esses modelos podem ser comparados e o melhor modelo pode ser selecionado.
Coluna de destino: é para isso que o modelo será treinado para prever. Escolha a coluna no conjunto de dados que contém os dados que você deseja prever. Para este tutorial, selecione a coluna
fareAmountnumérica como a coluna de destino.Pool de faíscas: especifique o pool de faíscas que você deseja usar para a execução automatizada do experimento. Os cálculos são executados no pool que você especificar.
Detalhes de configuração do Spark: além do pool do Spark, você tem a opção de fornecer detalhes de configuração da sessão.
Selecione Continuar.
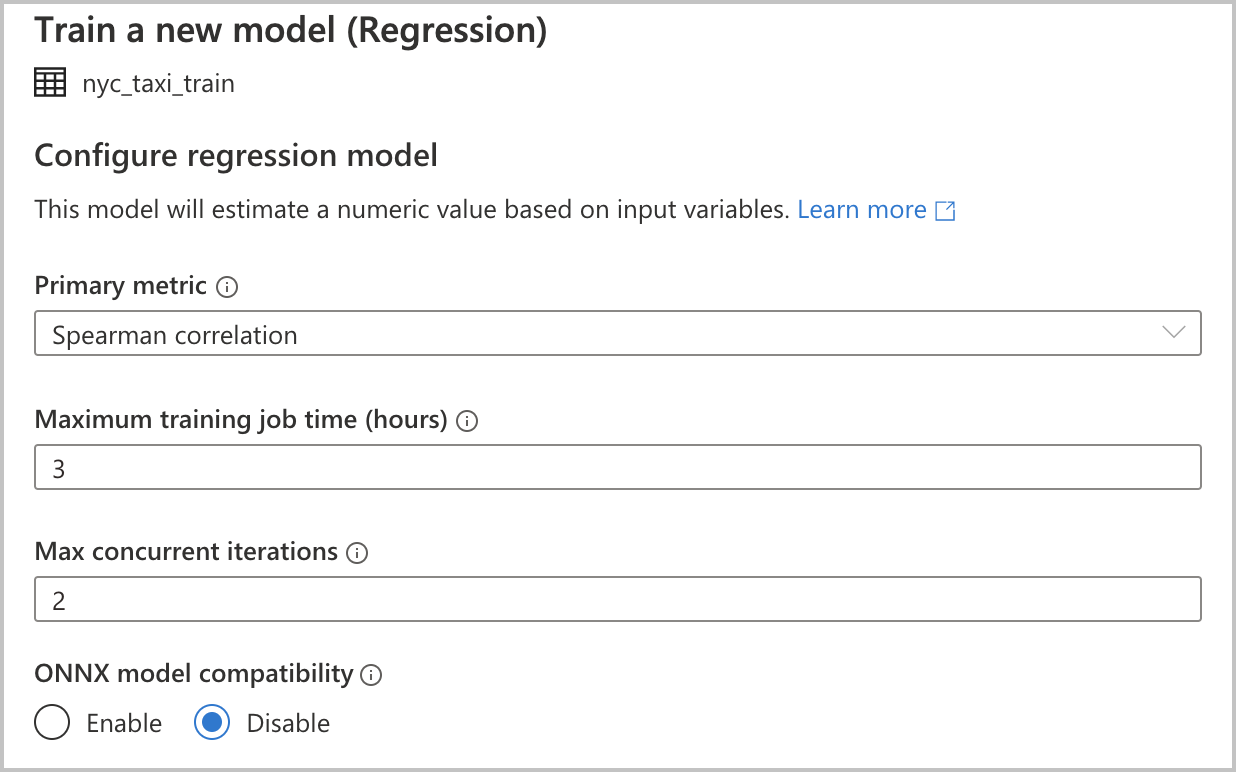
Configurar o modelo
Como você selecionou Regressão como seu tipo de modelo na seção anterior, as seguintes configurações estão disponíveis (elas também estão disponíveis para o tipo de modelo Classificação):
Métrica primária: insira a métrica que mede o desempenho do modelo. Você usa essa métrica para comparar diferentes modelos criados na execução automatizada e determinar qual modelo teve o melhor desempenho.
Tempo de trabalho de treinamento (horas): especifique a quantidade máxima de tempo, em horas, para um experimento executar e treinar modelos. Observe que você também pode fornecer valores menores que 1 (por exemplo, 0,5).
Máximo de iterações simultâneas: escolha o número máximo de iterações que são executadas em paralelo.
Compatibilidade do modelo ONNX: Se você habilitar essa opção, os modelos treinados pelo aprendizado de máquina automatizado serão convertidos para o formato ONNX. Isso é particularmente relevante se você quiser usar o modelo para pontuação nos pools SQL do Azure Synapse Analytics.
Todas essas configurações têm um valor padrão que você pode personalizar.
Iniciar uma corrida
Depois que todas as configurações necessárias forem feitas, você poderá iniciar sua execução automatizada. Você pode optar por criar uma execução diretamente, selecionando Criar execução - isso inicia a execução sem código. Como alternativa, se preferir código, você pode selecionar Abrir no bloco de anotações - isso abre um bloco de anotações contendo o código que cria a execução para que você possa visualizar o código e iniciar a execução por conta própria.

Nota
Se você selecionou Previsão de séries temporais como seu tipo de modelo na seção anterior, deverá fazer configurações adicionais. A previsão também não suporta compatibilidade com modelos ONNX.
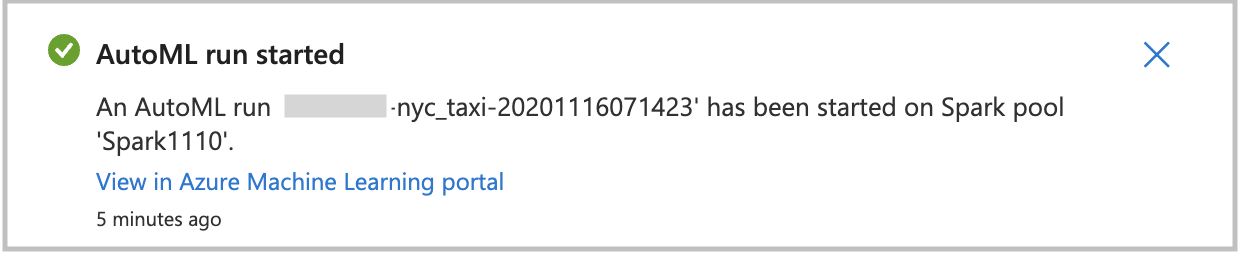
Criar uma execução diretamente
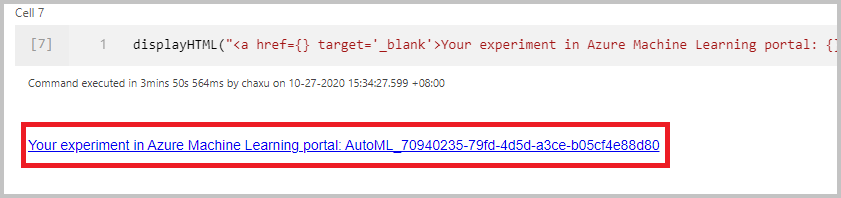
Para iniciar a execução do aprendizado de máquina automatizado diretamente, selecione Criar execução. Você verá uma notificação que indica que a execução está começando. Em seguida, você verá outra notificação que indica sucesso. Você também pode verificar o status no Aprendizado de Máquina do Azure selecionando o link na notificação.
Criar uma corrida com um bloco de notas
Para gerar um bloco de anotações, selecione Abrir no bloco de anotações. Isso lhe dá a oportunidade de adicionar configurações ou modificar o código para sua execução automatizada de aprendizado de máquina. Quando estiver pronto para executar o código, selecione Executar tudo.

Monitore a execução
Depois de enviar a execução com êxito, você verá um link para a execução do experimento no espaço de trabalho do Aprendizado de Máquina do Azure na saída do bloco de anotações. Selecione o link para monitorar sua execução automatizada no Azure Machine Learning.