Tutorial: Capture dados de Hubs de Eventos em formato parquet e analise com o Azure Synapse Analytics
Este tutorial mostra como usar o editor sem código do Stream Analytics para criar um trabalho que captura dados de Hubs de Eventos no Azure Data Lake Storage Gen2 no formato parquet.
Neste tutorial, irá aprender a:
- Implantar um gerador de eventos que envia eventos de exemplo para um hub de eventos
- Criar um trabalho do Stream Analytics usando o editor sem código
- Revisar dados de entrada e esquema
- Configurar o Azure Data Lake Storage Gen2 para o qual os dados do hub de eventos serão capturados
- Executar a tarefa do Stream Analytics
- Usar o Azure Synapse Analytics para consultar os arquivos de parquet
Pré-requisitos
Antes de começar, certifique-se de que concluiu os seguintes passos:
- Se não tiver uma subscrição do Azure, crie uma conta gratuita.
- Implante o aplicativo gerador de eventos TollApp no Azure. Defina o parâmetro 'interval' como 1 e use um novo grupo de recursos para esta etapa.
- Crie um espaço de trabalho do Azure Synapse Analytics com uma conta do Data Lake Storage Gen2.
Não use nenhum editor de código para criar um trabalho do Stream Analytics
Localize o Grupo de Recursos no qual o gerador de eventos TollApp foi implantado.
Selecione o namespace Hubs de Eventos do Azure. Talvez você queira abri-lo em uma guia separada ou em uma janela.
Na página de namespace Hubs de Eventos, selecione Hubs de Eventos em Entidades no menu à esquerda.
Selecione a
entrystreaminstância.
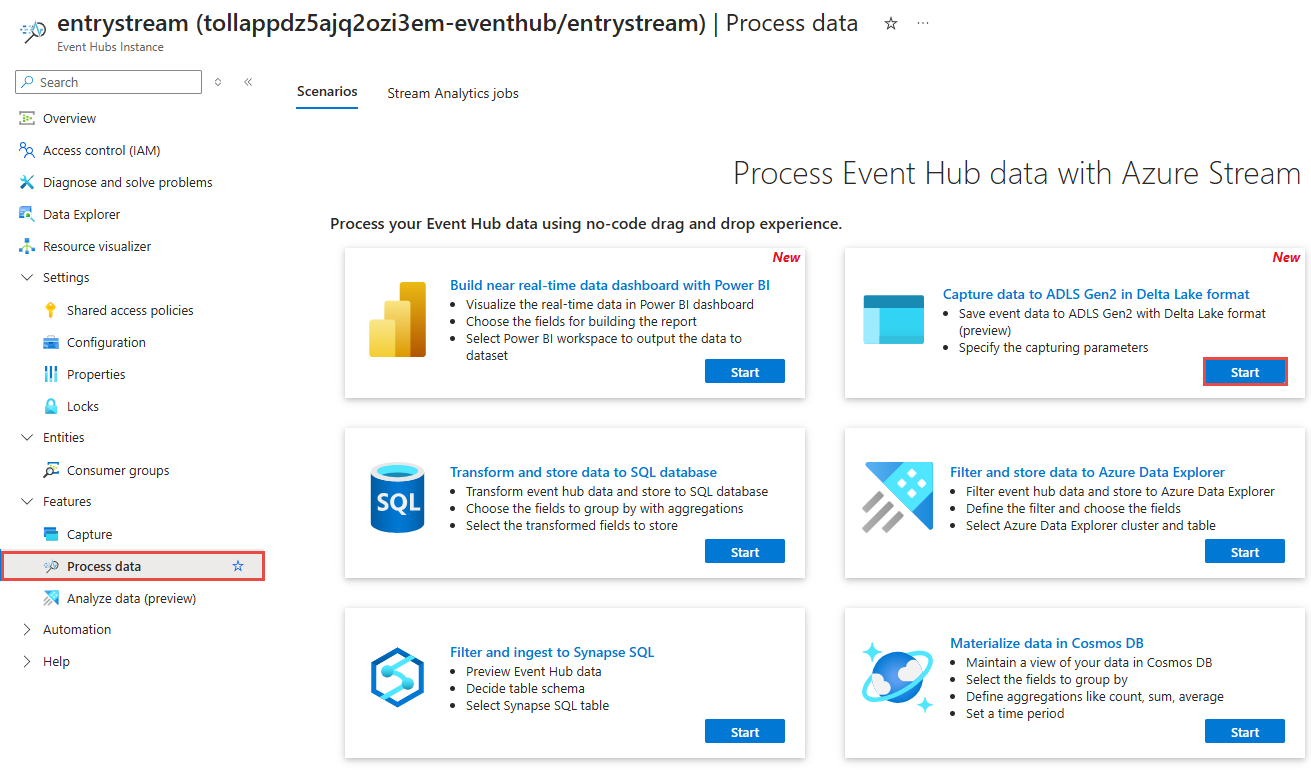
Na página de instância de Hubs de Eventos, selecione Processar dados na seção Recursos no menu à esquerda.
Selecione Iniciar no bloco Capturar dados para ADLS Gen2 no formato Parquet.
Nomeie seu trabalho
parquetcapturee selecione Criar.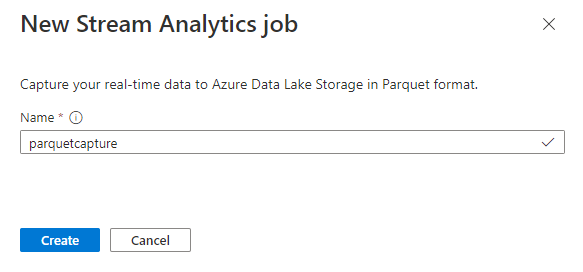
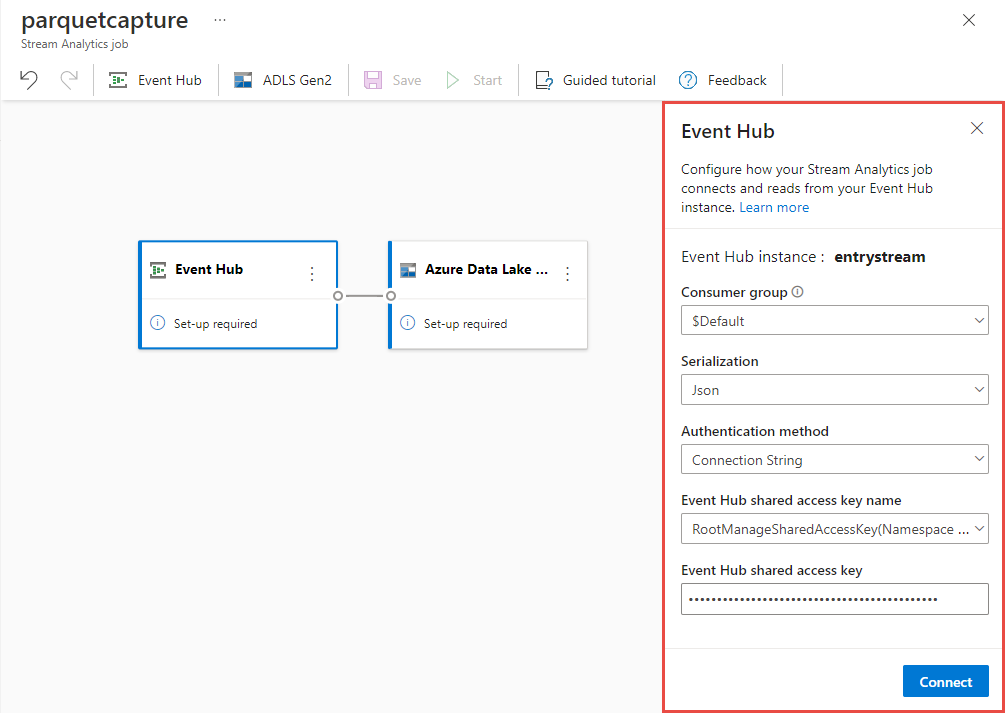
Na página de configuração do hub de eventos, siga estas etapas:
Em Grupo de consumidores, selecione Usar existente.
Confirme se
$Defaulto grupo de consumidores está selecionado.Confirme se Serialização está definido como JSON.
Confirme se o método de autenticação está definido como Cadeia de conexão.
Confirme se o nome da chave de acesso compartilhado do hub de eventos está definido como RootManageSharedAccessKey.
Selecione Conectar na parte inferior da janela.
Dentro de alguns segundos, você verá dados de entrada de exemplo e o esquema. Você pode optar por soltar campos, renomear campos ou alterar o tipo de dados.
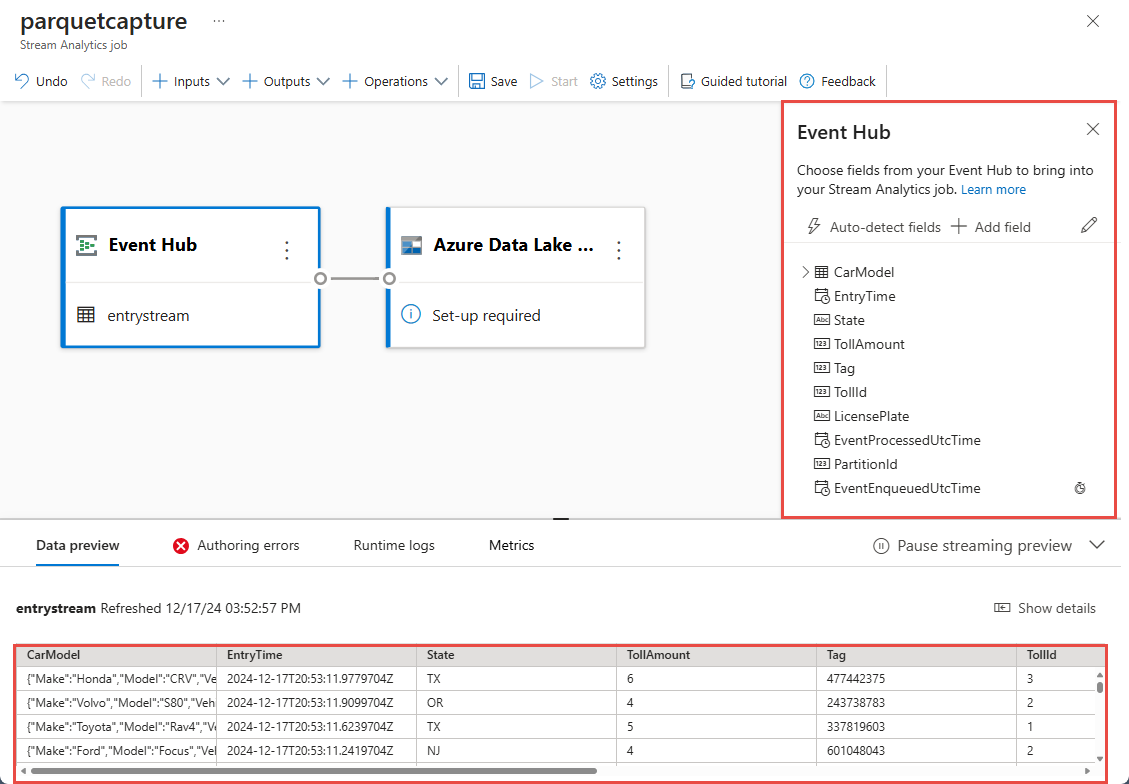
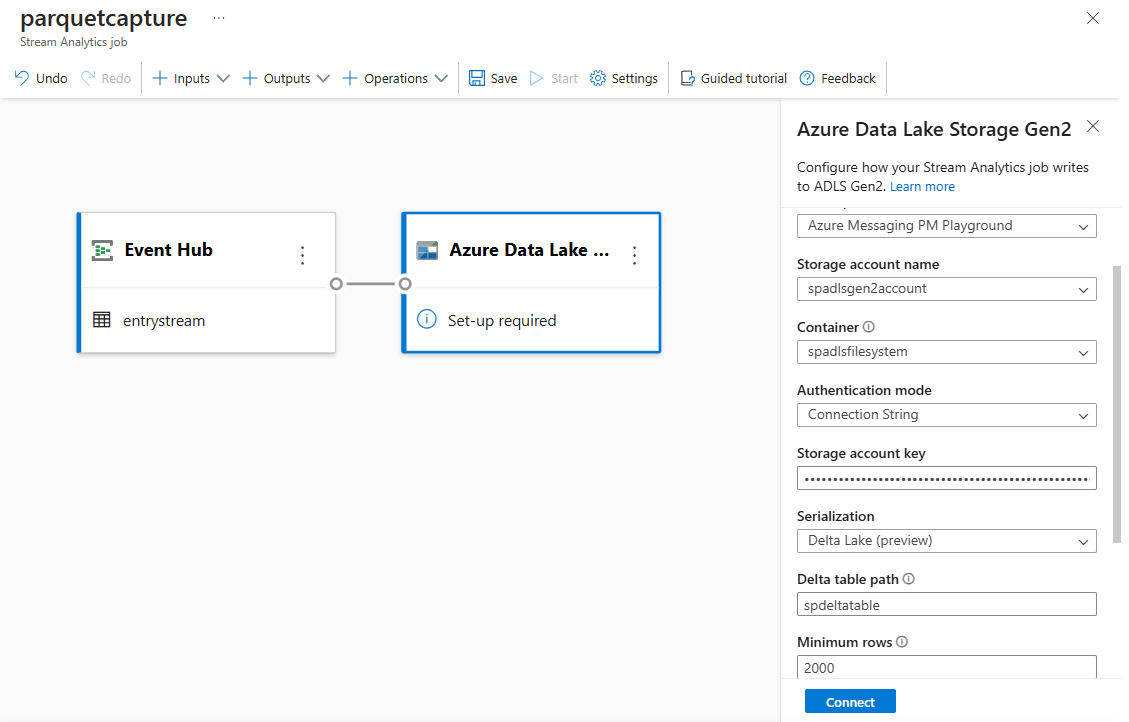
Selecione o bloco Azure Data Lake Storage Gen2 em sua tela e configure-o especificando
Subscrição em que a sua conta do Azure Data Lake Gen2 está localizada
Nome da conta de armazenamento, que deve ser a mesma conta do ADLS Gen2 usada com seu espaço de trabalho do Azure Synapse Analytics feito na seção Pré-requisitos.
Contêiner dentro do qual os arquivos do Parquet serão criados.
Para Caminho da tabela Delta, especifique um nome para a tabela.
Padrão de data e hora como o padrão aaaa-mm-dd e HH.
Selecione Ligar
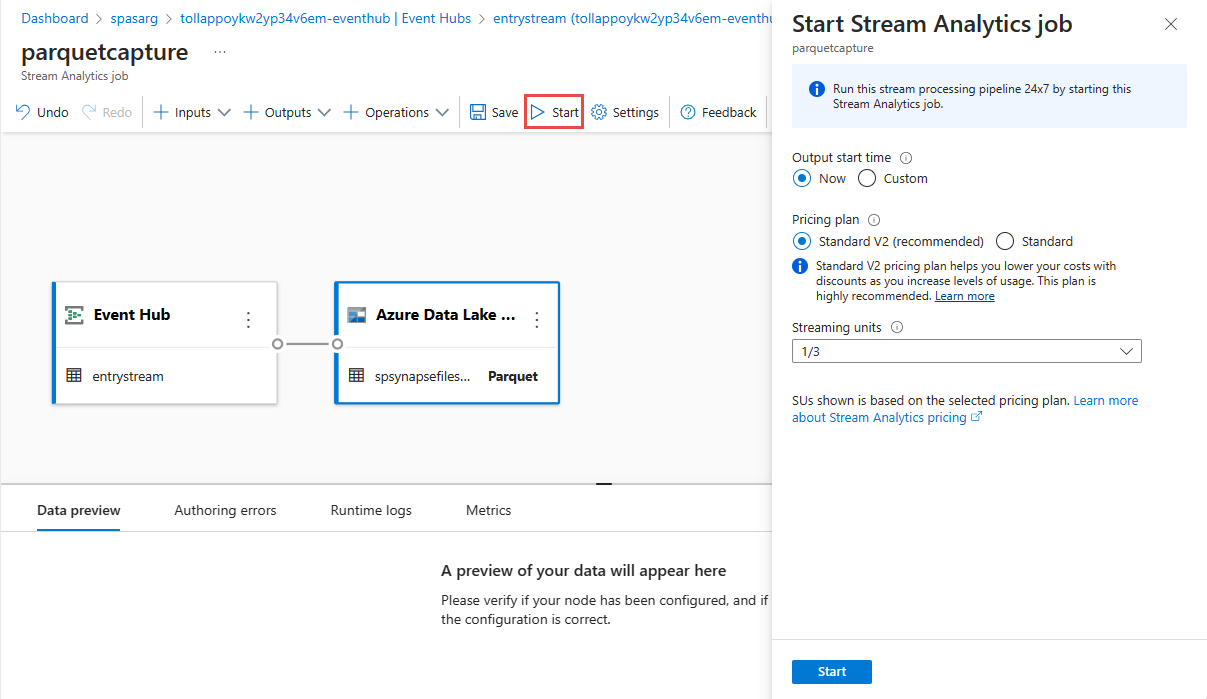
Selecione Guardar no friso superior para guardar o seu trabalho e, em seguida, selecione Iniciar para executar o seu trabalho. Quando o trabalho for iniciado, selecione X no canto direito para fechar a página de trabalho do Stream Analytics.
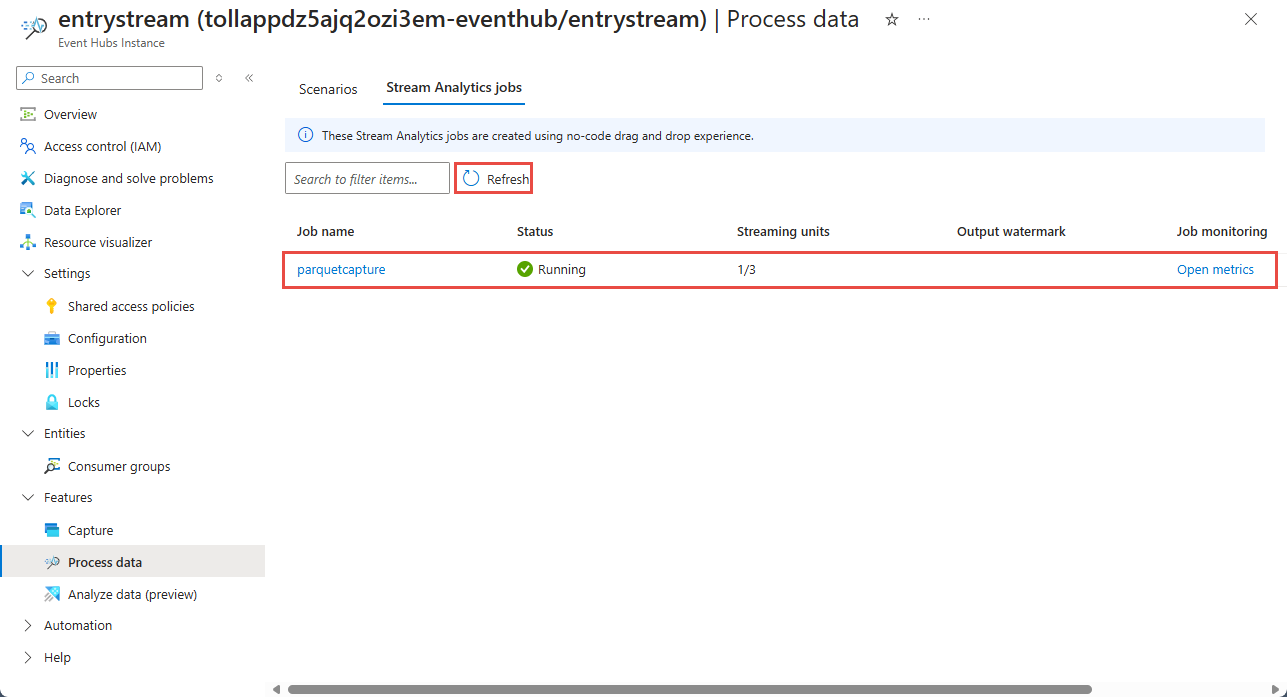
Em seguida, você verá uma lista de todos os trabalhos do Stream Analytics criados usando o editor sem código. E dentro de dois minutos, seu trabalho irá para um estado de execução . Selecione o botão Atualizar na página para ver o status mudando de Criado -> Iniciando -> Em execução.








Ver a saída na sua conta do Azure Data Lake Storage Gen 2
Localize a conta do Azure Data Lake Storage Gen2 que você usou na etapa anterior.
Selecione o contêiner que você usou na etapa anterior. Você verá os arquivos parquet criados na pasta especificada anteriormente.
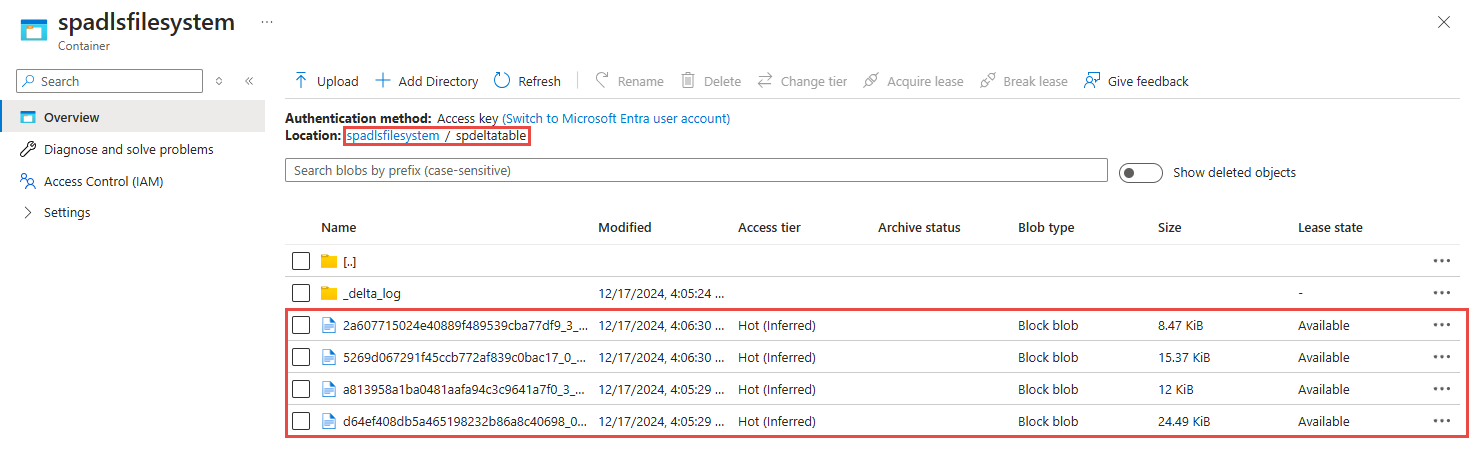

Consultar dados capturados no formato Parquet com o Azure Synapse Analytics
Consulta usando o Azure Synapse Spark
Localize seu espaço de trabalho do Azure Synapse Analytics e abra o Synapse Studio.
Crie um pool do Apache Spark sem servidor em seu espaço de trabalho, se ainda não existir.
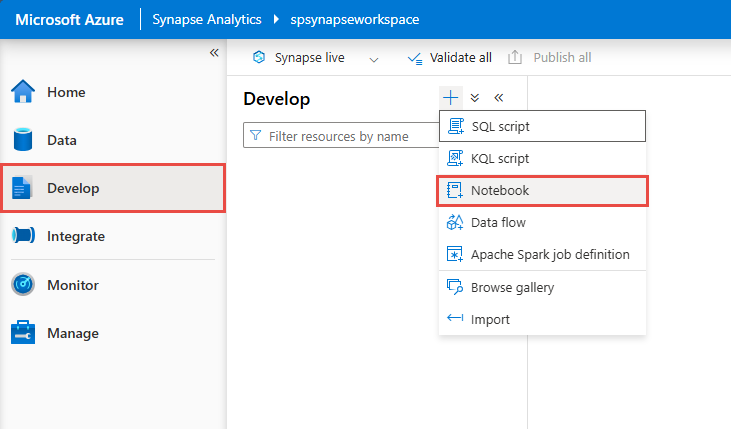
No Synapse Studio, vá para o hub Develop e crie um novo Notebook.
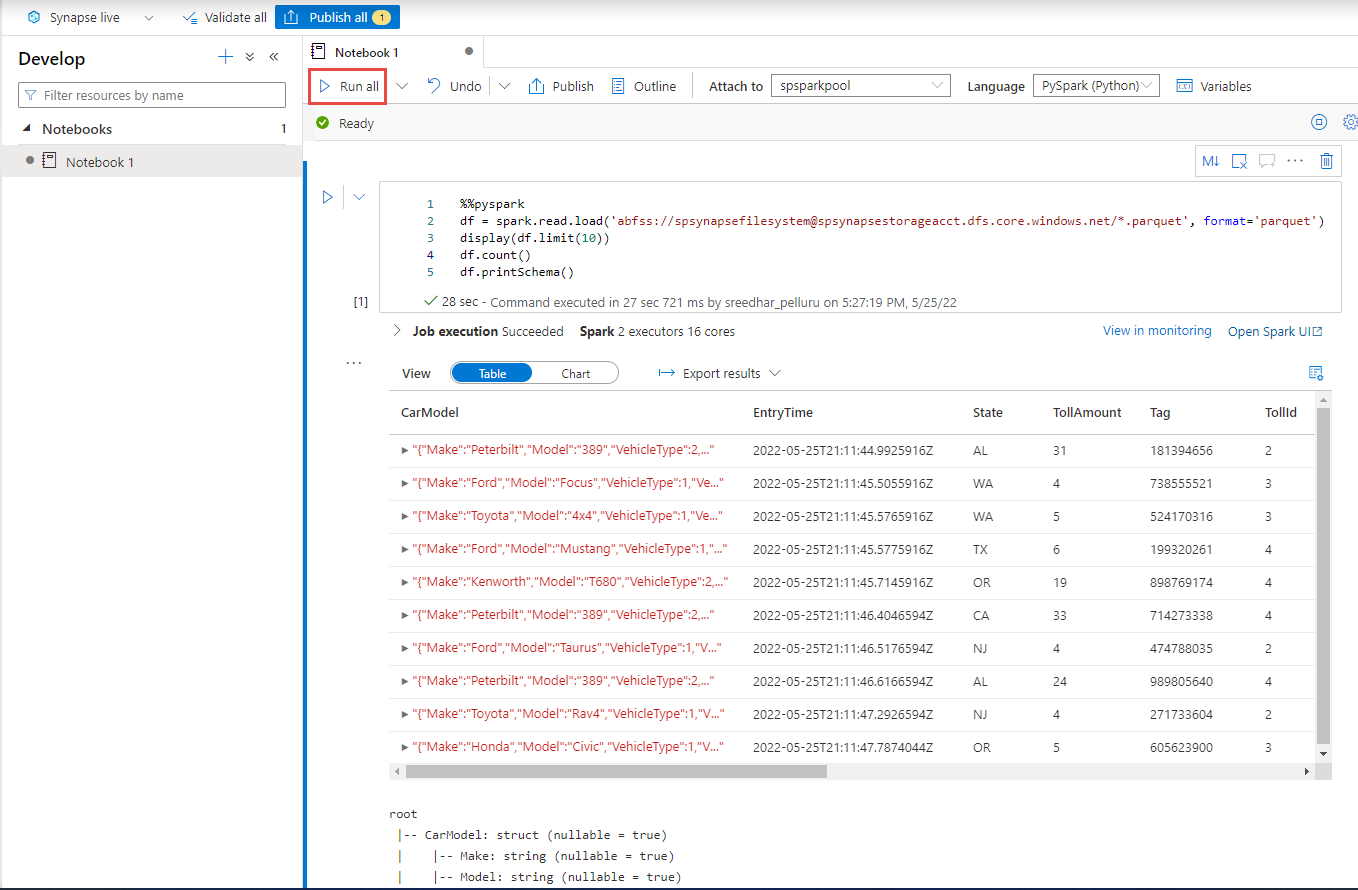
Crie uma nova célula de código e cole o seguinte código nessa célula. Substitua container e adlsname pelo nome do contêiner e da conta ADLS Gen2 usados na etapa anterior.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Em Anexar a na barra de ferramentas, selecione seu pool do Spark na lista suspensa.
Selecione Executar tudo para ver os resultados

Consulta usando o Azure Synapse Serverless SQL
No hub Desenvolver, crie um novo script SQL.
Cole o script a seguir e execute-o usando o ponto de extremidade SQL sem servidor interno. Substitua container e adlsname pelo nome do contêiner e da conta ADLS Gen2 usados na etapa anterior.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]

Clean up resources (Limpar recursos)
- Localize sua instância de Hubs de Eventos e veja a lista de trabalhos do Stream Analytics na seção Dados de processo . Pare todos os trabalhos que estão em execução.
- Vá para o grupo de recursos que você usou ao implantar o gerador de eventos TollApp.
- Selecione Eliminar grupo de recursos. Digite o nome do grupo de recursos para confirmar a exclusão.
Próximos passos
Neste tutorial, você aprendeu como criar um trabalho do Stream Analytics usando o editor sem código para capturar fluxos de dados dos Hubs de Eventos no formato Parquet. Em seguida, você usou o Azure Synapse Analytics para consultar os arquivos de parquet usando o Synapse Spark e o Synapse SQL.