Gestor de Tráfego do Azure com o Azure Site Recovery
O Azure Traffic Manager permite controlar a distribuição do tráfego entre os pontos de extremidade do aplicativo. Os pontos finais são serviços com acesso à Internet alojados dentro ou fora do Azure.
O Gerenciador de Tráfego usa o DNS (Sistema de Nomes de Domínio) para direcionar as solicitações do cliente para o ponto de extremidade mais apropriado, com base em um método de roteamento de tráfego e na integridade dos pontos de extremidade. O Gestor de Tráfego proporciona vários métodos de encaminhamento de tráfego e opções de monitorização de pontos finais para satisfazer diferentes necessidades das aplicações e modelos de ativação pós-falha automática. Os clientes ligam diretamente ao ponto final selecionado. O Gerenciador de Tráfego não é um proxy ou um gateway e não vê o tráfego que passa entre o cliente e o serviço.
Este artigo descreve como você pode combinar o roteamento inteligente do Azure Traffic Monitor com os poderosos recursos de migração e recuperação de desastres do Azure Site Recovery.
Failover local para o Azure
Para o primeiro cenário, considere a empresa A que tem toda a sua infraestrutura de aplicativos em execução em seu ambiente local. Por motivos de continuidade de negócios e conformidade, a Empresa A decide usar o Azure Site Recovery para proteger seus aplicativos.
A empresa A está executando aplicativos com pontos de extremidade públicos e quer a capacidade de redirecionar perfeitamente o tráfego para o Azure em um evento de desastre. O método de roteamento de tráfego prioritário no Gerenciador de Tráfego do Azure permite que a empresa A implemente facilmente esse padrão de failover.
A configuração é a seguinte:
- A empresa A cria um perfil de Gestor de Tráfego.
- Utilizando o método de roteamento Priority, a Empresa A cria dois pontos de extremidade – Principal para local e Failover para Azure. Primário é atribuído Prioridade 1 e Failover é atribuído Prioridade 2.
- Como o ponto de extremidade primário é hospedado fora do Azure, o ponto de extremidade é criado como um ponto de extremidade externo .
- Com o Azure Site Recovery, o site do Azure não tem máquinas virtuais ou aplicativos em execução antes do failover. Portanto, o ponto de extremidade de failover também é criado como um ponto de extremidade externo .
- Por padrão, o tráfego de usuários é direcionado para o aplicativo local porque esse ponto de extremidade tem a prioridade mais alta associada a ele. Nenhum tráfego é direcionado para o Azure se o ponto de extremidade primário estiver íntegro.
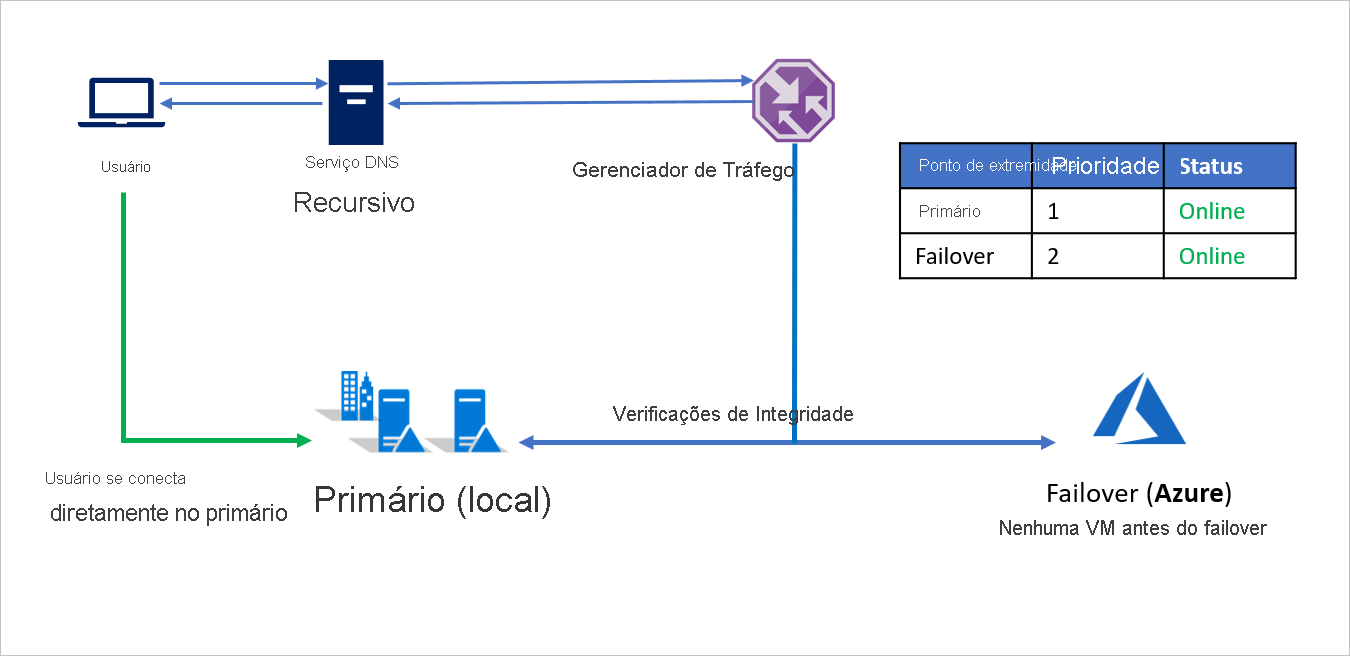
Em um evento de desastre, a empresa A pode disparar um failover para o Azure e recuperar seus aplicativos no Azure. Quando o Gerenciador de Tráfego do Azure deteta que o ponto de extremidade Primário não está mais íntegro, ele usa automaticamente o ponto de extremidade de Failover na resposta DNS e os usuários se conectam ao aplicativo recuperado no Azure.
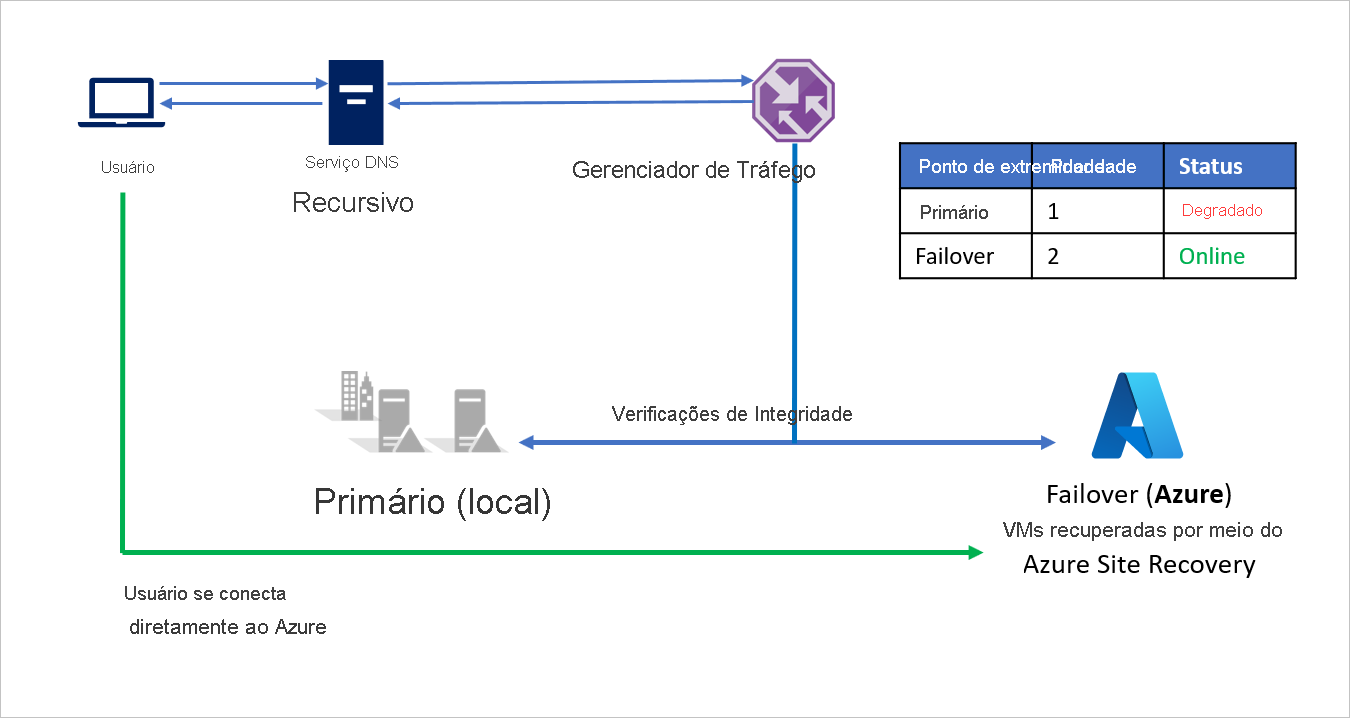
Dependendo dos requisitos de negócios, a Empresa A pode escolher uma frequência de sondagem maior ou menor para alternar entre o local para o Azure em um evento de desastre e garantir um tempo de inatividade mínimo para os usuários.
Quando o desastre é contido, a empresa A pode fazer failback do Azure para seu ambiente local (VMware ou Hyper-V) usando o Azure Site Recovery. Agora, quando o Gerenciador de Tráfego deteta que o ponto de extremidade primário está íntegro novamente, ele utiliza automaticamente o ponto de extremidade primário em suas respostas DNS.
Migração local para o Azure
Além da recuperação de desastres, o Azure Site Recovery também permite migrações para o Azure. Usando os poderosos recursos de failover de teste do Azure Site Recovery, os clientes podem avaliar o desempenho do aplicativo no Azure sem afetar seu ambiente local. E quando os clientes estiverem prontos para migrar, eles podem optar por migrar cargas de trabalho inteiras juntas ou optar por migrar e escalar gradualmente.
O método de roteamento ponderado do Gerenciador de Tráfego do Azure pode ser usado para direcionar parte do tráfego de entrada para o Azure enquanto direciona a maioria para o ambiente local. Esta abordagem pode ajudar a avaliar o desempenho da escala, uma vez que pode continuar a aumentar o peso atribuído ao Azure à medida que migra cada vez mais cargas de trabalho para o Azure.
Por exemplo, a empresa B opta por migrar em fases, movendo parte de seu ambiente de aplicativo enquanto mantém o restante no local. Durante os estágios iniciais, quando a maior parte do ambiente é local, um peso maior é atribuído ao ambiente local. O gestor de tráfego devolve um ponto de extremidade com base nos pesos atribuídos aos pontos de extremidade disponíveis.
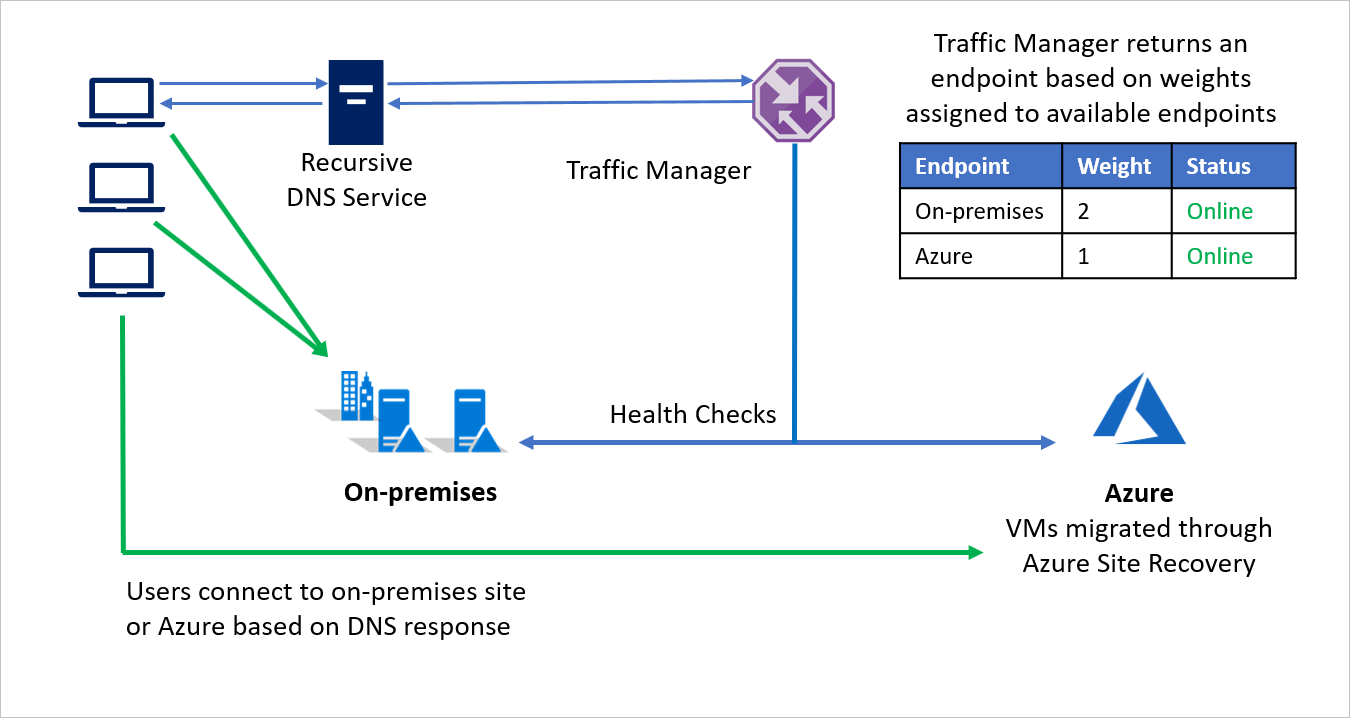
Durante a migração, ambos os pontos de extremidade ficam ativos e a maior parte do tráfego é direcionada para o ambiente local. À medida que a migração prossegue, um peso maior pode ser atribuído ao ponto de extremidade no Azure e, finalmente, o ponto de extremidade local pode ser desativado após a migração.
Failover do Azure para o Azure
Para este exemplo, considere a Empresa C que tem toda a sua infraestrutura de aplicativos executando o Azure. Por motivos de continuidade de negócios e conformidade, a Empresa C decide usar o Azure Site Recovery para proteger seus aplicativos.
A empresa C está executando aplicativos com pontos de extremidade públicos e quer a capacidade de redirecionar perfeitamente o tráfego para uma região diferente do Azure em um evento de desastre. O método de roteamento de tráfego prioritário permite que a empresa C implemente facilmente esse padrão de failover.
A configuração é a seguinte:
- A empresa C cria um perfil de Gestor de Tráfego.
- Utilizando o método de roteamento Priority, a Empresa C cria dois pontos de extremidade – Primário para a região de origem (Azure East Asia) e Failover para a região de recuperação (Azure Sudeste Asiático). Primário é atribuído Prioridade 1 e Failover é atribuído Prioridade 2.
- Como o ponto de extremidade primário está hospedado no Azure, o ponto de extremidade pode ser como um ponto de extremidade do Azure .
- Com o Azure Site Recovery, o site do Azure de recuperação não tem máquinas virtuais ou aplicativos em execução antes do failover. Assim, o ponto de extremidade de failover pode ser criado como um ponto de extremidade externo .
- Por padrão, o tráfego do usuário é direcionado para o aplicativo da região de origem (Leste Asiático), pois esse ponto de extremidade tem a prioridade mais alta associada a ele. Nenhum tráfego é direcionado para a região de recuperação se o ponto de extremidade primário estiver íntegro.
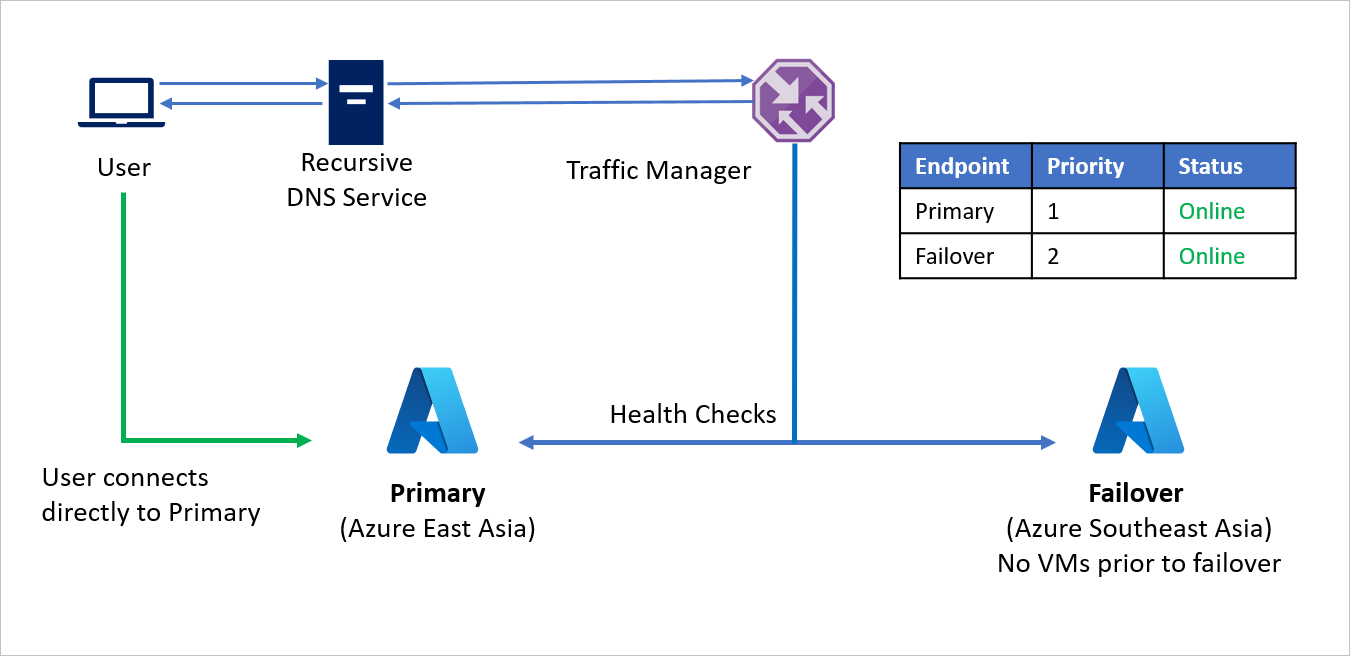
Em um evento de desastre, a Empresa C pode disparar um failover e recuperar seus aplicativos na região do Azure de recuperação. Quando o Gerenciador de Tráfego do Azure deteta que o ponto de extremidade primário não está mais íntegro, ele usa automaticamente o ponto de extremidade de failover na resposta DNS e os usuários se conectam ao aplicativo recuperado na região de recuperação do Azure (Sudeste Asiático).
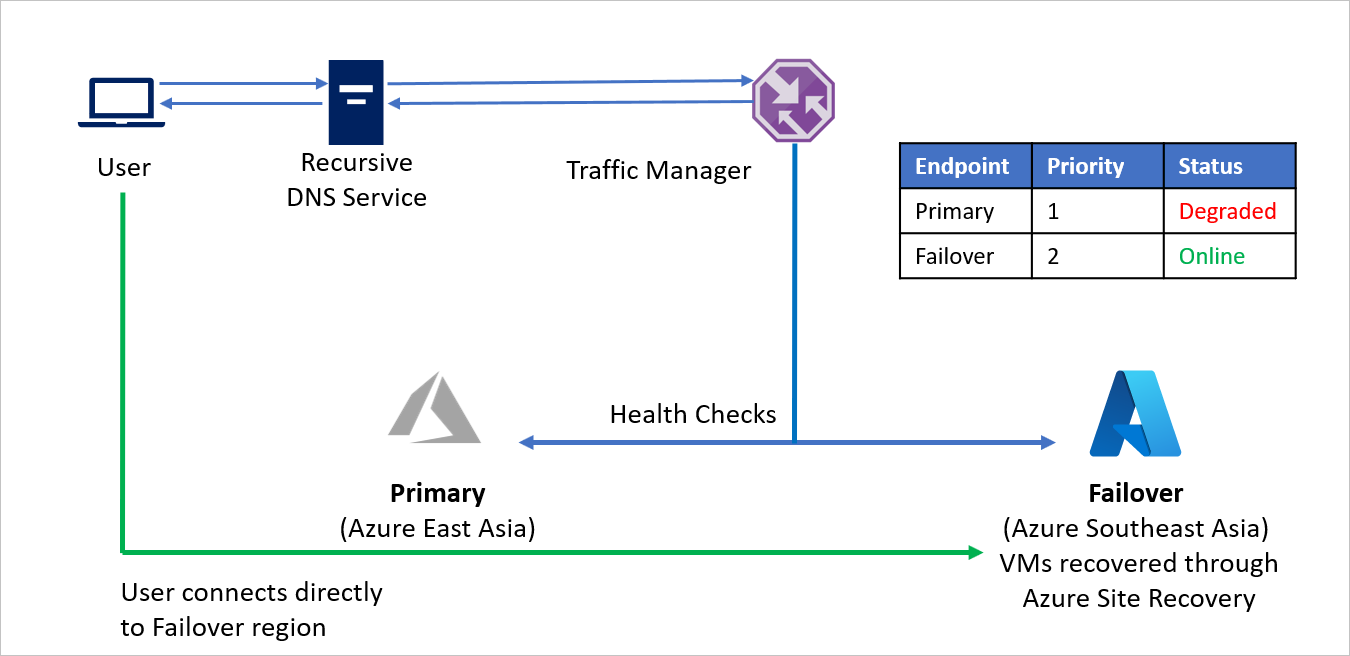
Dependendo dos requisitos de negócios, a empresa C pode escolher uma frequência de sondagem maior ou menor para alternar entre as regiões de origem e de recuperação e garantir um tempo de inatividade mínimo para os usuários.
Quando o desastre é contido, a empresa C pode fazer failback da região do Azure de recuperação para a região do Azure de origem usando o Azure Site Recovery. Agora, quando o Gerenciador de Tráfego deteta que o ponto de extremidade primário está íntegro novamente, ele utiliza automaticamente o ponto de extremidade primário em suas respostas DNS.
Proteção de aplicativos corporativos de várias regiões
As empresas globais geralmente melhoram a experiência do cliente adaptando seus aplicativos para atender às necessidades regionais. A localização e a redução da latência podem levar à divisão da infraestrutura de aplicativos entre as regiões. As empresas também estão vinculadas às leis regionais de dados em determinadas áreas e optam por isolar uma parte de sua infraestrutura de aplicativos dentro dos limites regionais.
Vamos considerar um exemplo em que a empresa D dividiu seus pontos finais de aplicação para servir separadamente a Alemanha e o resto do mundo. A empresa D utiliza o método de roteamento geográfico do Gerenciador de Tráfego do Azure para configurar isso. Qualquer tráfego originário da Alemanha é direcionado para o Endpoint 1 e qualquer tráfego originado fora da Alemanha é direcionado para o Endpoint 2.
O problema com essa configuração é que, se o Endpoint 1 parar de funcionar por qualquer motivo, não haverá redirecionamento do tráfego para o Endpoint 2. O tráfego originário da Alemanha continua a ser direcionado para o Endpoint 1 , independentemente da integridade do endpoint, deixando os usuários alemães sem acesso ao aplicativo da Empresa D. Da mesma forma, se o Endpoint 2 ficar offline, não haverá redirecionamento do tráfego para o Endpoint 1.
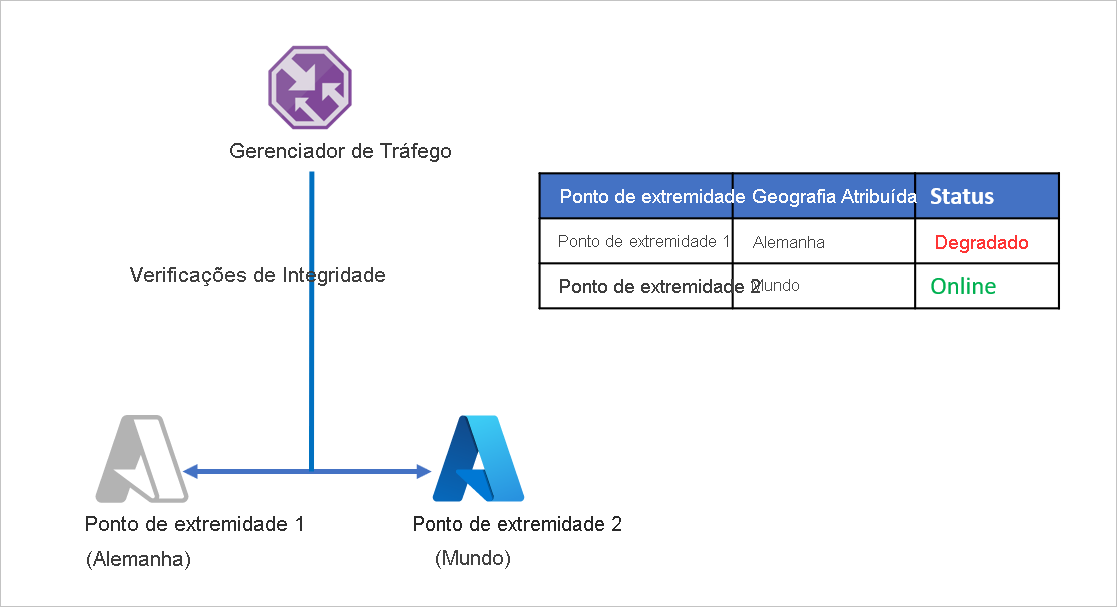
Para evitar esse problema e garantir a resiliência do aplicativo, a empresa D usa perfis aninhados do Gerenciador de Tráfego com o Azure Site Recovery. Em uma configuração de perfil aninhado, o tráfego não é direcionado para pontos de extremidade individuais, mas sim para outros perfis do Gerenciador de Tráfego. Veja como essa configuração funciona:
- Em vez de utilizar o roteamento geográfico com pontos de extremidade individuais, a empresa D usa o roteamento geográfico com perfis do Gerenciador de Tráfego.
- Cada perfil filho do Gerenciador de Tráfego utiliza o roteamento Priority com um ponto de extremidade primário e um ponto de extremidade de recuperação, aninhando assim o roteamento Priority no roteamento geográfico .
- Para habilitar a resiliência do aplicativo, cada distribuição de carga de trabalho utiliza o Azure Site Recovery para fazer failover para uma região de recuperação com base em caso de um evento de desastre.
- Quando o Gerenciador de Tráfego pai recebe uma consulta DNS, ela é direcionada para o Gerenciador de Tráfego filho relevante que responde à consulta com um ponto de extremidade disponível.
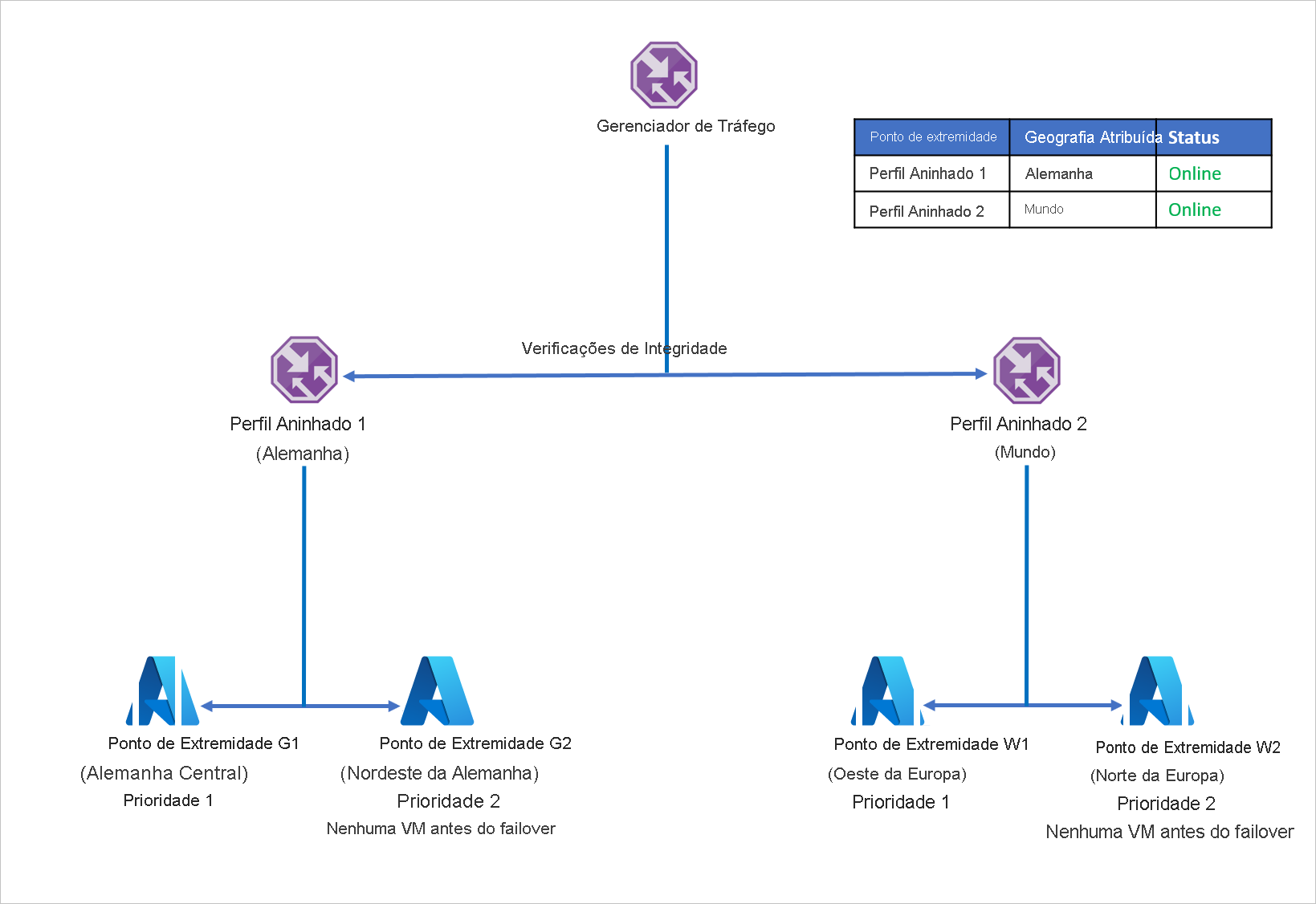
Por exemplo, se o ponto de extremidade na Alemanha Central falhar, o aplicativo poderá ser recuperado rapidamente para o Nordeste da Alemanha. O novo endpoint lida com o tráfego originário da Alemanha com o mínimo de tempo de inatividade para os usuários. Da mesma forma, uma interrupção de ponto de extremidade na Europa Ocidental pode ser tratada recuperando a carga de trabalho do aplicativo para o Norte da Europa, com o Gerenciador de Tráfego do Azure lidando com redirecionamentos de DNS para o ponto de extremidade disponível.
A configuração acima pode ser expandida para incluir quantas combinações de regiões e pontos finais forem necessárias. O Gerenciador de Tráfego permite até 10 níveis de perfis aninhados e não permite loops dentro da configuração aninhada.
Considerações sobre o RTO (Recovery Time Objetive, objetivo de tempo de recuperação)
Na maioria das organizações, adicionar ou modificar registros DNS é tratado por uma equipe separada ou por alguém de fora da organização. Isso torna a tarefa de alterar registros DNS muito desafiadora. O tempo necessário para atualizar os registros DNS por outras equipes ou organizações que gerenciam a infraestrutura DNS varia de organização para organização e afeta o RTO do aplicativo.
Ao utilizar o Gerenciador de Tráfego, você pode fazer o pré-carregamento do trabalho necessário para atualizações de DNS. Nenhuma ação manual ou com script é necessária no momento do failover real. Essa abordagem ajuda na troca rápida (e, portanto, na redução do RTO), além de evitar erros dispendiosos e demorados de alteração de DNS em um evento de desastre. Com o Traffic Manager, até mesmo a etapa de failback é automatizada, que de outra forma teria que ser gerenciada separadamente.
Definir o intervalo de sondagem correto por meio de verificações de integridade de intervalo básicas ou rápidas pode reduzir consideravelmente o RTO durante o failover e reduzir o tempo de inatividade para os usuários.
Além disso, você pode otimizar o valor TTL (Time to Live) do DNS para o perfil do Gerenciador de Tráfego. TTL é o valor para o qual uma entrada DNS seria armazenada em cache por um cliente. Para um registro, o DNS não seria consultado duas vezes dentro do período de TTL. Cada registro DNS tem um TTL associado a ele. A redução desse valor resulta em mais consultas DNS ao Gerenciador de Tráfego, mas pode reduzir o RTO descobrindo interrupções mais rapidamente.
O TTL experimentado pelo cliente também não aumenta se o número de resolvedores de DNS entre o cliente e o servidor DNS autoritativo aumentar. Os resolvedores de DNS 'contam' o TTL e apenas transmitem um valor TTL que reflete o tempo decorrido desde que o registo foi armazenado em cache. Isso garante que o registro DNS seja atualizado no cliente após o TTL, independentemente do número de resolvedores de DNS na cadeia.
Próximos passos
- Saiba mais sobre os métodos de roteamento do Gerenciador de Tráfego.
- Saiba mais sobre perfis aninhados do Gerenciador de Tráfego.
- Saiba mais sobre o monitoramento de endpoints.
- Saiba mais sobre planos de recuperação para automatizar o failover de aplicativos.