Exceções OutOfMemoryError para Apache Spark no Azure HDInsight
Este artigo descreve as etapas de solução de problemas e possíveis resoluções de problemas ao usar componentes do Apache Spark em clusters do Azure HDInsight.
Cenário: Exceção OutOfMemoryError para Apache Spark
Problema
Seu aplicativo Apache Spark falhou com uma exceção não tratada OutOfMemoryError. Poderá receber uma mensagem de erro semelhante a:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Motivo
A causa mais provável dessa exceção é que não há memória de heap suficiente alocada para as máquinas virtuais Java (JVMs). Essas JVMs são iniciadas como executores ou drivers como parte do aplicativo Apache Spark.
Resolução
Determine o tamanho máximo dos dados que o aplicativo Spark manipula. Faça uma estimativa do tamanho com base no tamanho máximo dos dados de entrada, dos dados intermédios produzidos pela transformação dos dados de entrada e dos dados de saída produzidos por transformações adicionais dos dados intermédios. Se a estimativa inicial não for suficiente, aumente ligeiramente o tamanho e itera até que os erros de memória diminuam.
Confirme que o cluster do HDInsight a ser utilizado tem recursos suficientes em termos de memória, assim como núcleos, para alojar a aplicação Spark. Isso pode ser determinado exibindo a seção Métricas de Cluster da interface do usuário do YARN do cluster para os valores de Memória Usada vs. Total de Memória e VCores Usados vs. VCores Total.

Defina as seguintes configurações do Spark para valores apropriados. Equilibre os requisitos do aplicativo com os recursos disponíveis no cluster. Esses valores não devem exceder 90% da memória e dos núcleos disponíveis, conforme visualizados pelo YARN, e também devem atender ao requisito mínimo de memória do aplicativo Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Memória total usada por todos os executores =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Total de memória usada pelo driver =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Cenário: Erro de espaço de heap Java ao tentar abrir o servidor de histórico do Apache Spark
Problema
Você recebe o seguinte erro ao abrir eventos no servidor Spark History:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Motivo
Esse problema geralmente é causado pela falta de recursos ao abrir grandes arquivos de eventos de faísca. O tamanho da pilha do Spark é definido como 1 GB por padrão, mas arquivos de eventos grandes do Spark podem exigir mais do que isso.
Se você gostaria de verificar o tamanho dos arquivos que você está tentando carregar, você pode executar os seguintes comandos:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Resolução
Você pode aumentar a memória do Spark History Server editando a SPARK_DAEMON_MEMORY propriedade na configuração do Spark e reiniciando todos os serviços.
Você pode fazer isso a partir da interface do usuário do navegador Ambari selecionando a seção Spark2/Config/Advanced spark2-env.
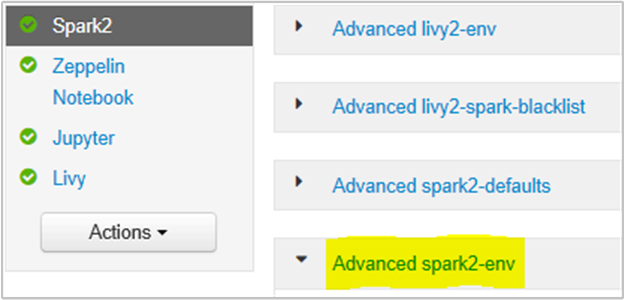
Adicione a seguinte propriedade para alterar a memória do Spark History Server de 1g para 4g: SPARK_DAEMON_MEMORY=4g.
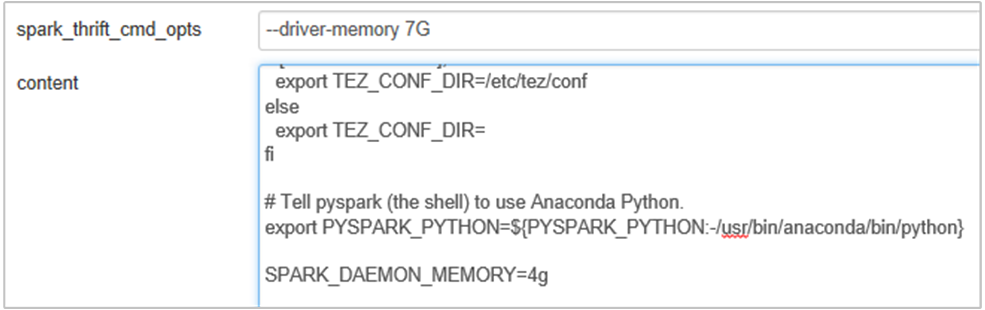
Certifique-se de reiniciar todos os serviços afetados do Ambari.
Cenário: Livy Server falha ao iniciar no cluster Apache Spark
Problema
O Livy Server não pode ser iniciado em um Apache Spark [(Spark 2.1 no Linux (HDI 3.6)]. A tentativa de reiniciar resulta na seguinte pilha de erros, a partir dos logs Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Motivo
java.lang.OutOfMemoryError: unable to create new native thread destaca que o sistema operacional não pode atribuir mais threads nativos às JVMs. Confirmado que essa exceção é causada pela violação do limite de contagem de threads por processo.
Quando o Livy Server termina inesperadamente, todas as conexões com o Spark Clusters também são encerradas, o que significa que todos os trabalhos e dados relacionados são perdidos. No mecanismo de recuperação de sessão HDP 2.6 foi introduzido, Livy armazena os detalhes da sessão no Zookeeper para serem recuperados depois que o Livy Server estiver de volta.
Quando tantos trabalhos são enviados via Livy, como parte da Alta Disponibilidade para o Livy Server armazena esses estados de sessão no ZK (em clusters HDInsight) e recupera essas sessões quando o serviço Livy é reiniciado. Na reinicialização após o encerramento inesperado, o Livy cria um thread por sessão e isso acumula algumas sessões a serem recuperadas, causando muitos threads sendo criados.
Resolução
Exclua todas as entradas usando as etapas a seguir.
Obter o endereço IP dos nós do zookeeper usando
grep -R zk /etc/hadoop/confO comando acima listou todos os tratadores de zoológicos para um cluster
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Obter todo o endereço IP dos nós do zookeeper usando ping Ou você também pode se conectar ao zookeeper a partir do nó principal usando o nome do zookeeper
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Uma vez conectado, para zookeeper execute o seguinte comando para listar todas as sessões que são tentadas reiniciar.
Na maioria dos casos, esta poderia ser uma lista de mais de 8000 sessões ####
ls /livy/v1/batchO comando a seguir é remover todas as sessões a serem recuperadas. #####
rmr /livy/v1/batch
Aguarde até que o comando acima seja concluído e o cursor retorne o prompt e, em seguida, reinicie o serviço Livy do Ambari, o que deve ser bem-sucedido.
Nota
DELETE a sessão de lívio, uma vez concluída a sua execução. As sessões em lote do Livy não serão excluídas automaticamente assim que o aplicativo spark for concluído, o que é por design. Uma sessão Livy é uma entidade criada por uma solicitação POST contra o servidor Livy REST. É necessária uma DELETE chamada para excluir essa entidade. Ou devemos esperar que o GC entre em ação.
Próximos passos
Se não viu o problema ou não conseguiu resolvê-lo, visite um dos seguintes canais para obter mais suporte:
Visão geral do gerenciamento de memória do Spark.
Depurando o aplicativo Spark em clusters HDInsight.
Obtenha respostas de especialistas do Azure através do Suporte da Comunidade do Azure.
Conecte-se com o @AzureSupport - a conta oficial do Microsoft Azure para melhorar a experiência do cliente. Ligar a comunidade do Azure aos recursos certos: respostas, suporte e especialistas.
Se precisar de mais ajuda, você pode enviar uma solicitação de suporte do portal do Azure. Selecione Suporte na barra de menus ou abra o hub Ajuda + suporte . Para obter informações mais detalhadas, consulte Como criar uma solicitação de suporte do Azure. O acesso ao suporte para Gestão de Subscrições e faturação está incluído na sua subscrição do Microsoft Azure e o Suporte Técnico é disponibilizado através de um dos Planos de Suporte do Azure.