Visão geral do Apache Spark Structured Streaming
O Apache Spark Structured Streaming permite implementar aplicativos escaláveis, de alta taxa de transferência e tolerantes a falhas para processar fluxos de dados. O Streaming Estruturado é criado com base no mecanismo Spark SQL e melhora as construções dos Quadros de Dados e Conjuntos de Dados do Spark SQL para que você possa escrever consultas de streaming da mesma forma que escreveria consultas em lote.
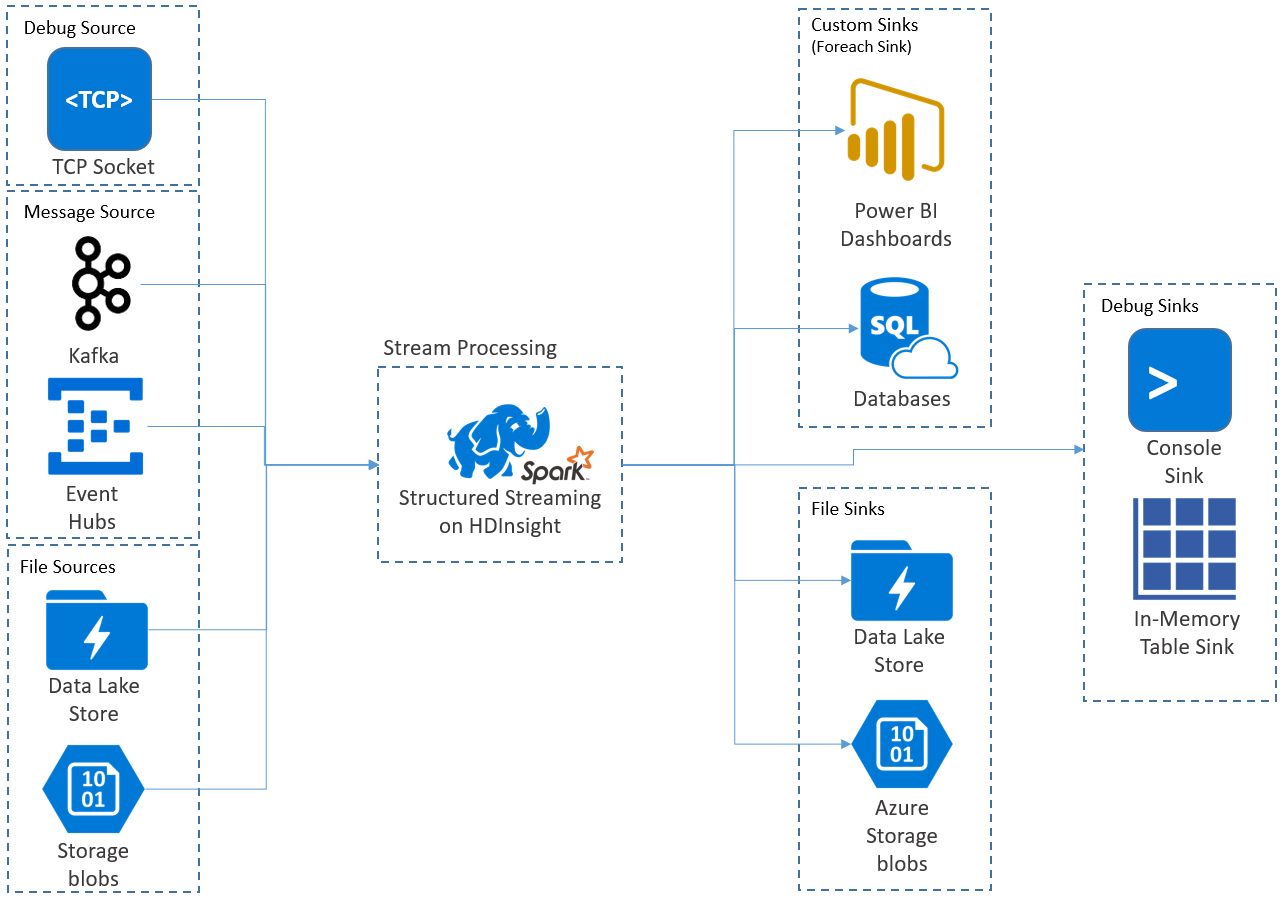
Os aplicativos de Streaming estruturado são executados em clusters HDInsight Spark e se conectam a dados de streaming do Apache Kafka, um soquete TCP (para fins de depuração), Armazenamento do Azure ou Armazenamento do Azure Data Lake. As duas últimas opções, que dependem de serviços de armazenamento externo, permitem que você observe novos arquivos adicionados ao armazenamento e processe seu conteúdo como se fossem transmitidos.
O Streaming Estruturado cria uma consulta de longa execução durante a qual você aplica operações aos dados de entrada, como seleção, projeção, agregação, janelas e junção do DataFrame de streaming com DataFrames de referência. Em seguida, você envia os resultados para o armazenamento de arquivos (Blobs de Armazenamento do Azure ou Armazenamento Data Lake) ou para qualquer armazenamento de dados usando código personalizado (como Banco de Dados SQL ou Power BI). O Streaming Estruturado também fornece saída para o console para depuração local e para uma tabela na memória para que você possa ver os dados gerados para depuração no HDInsight.
Nota
O Spark Structured Streaming está substituindo o Spark Streaming (DStreams). No futuro, o Streaming Estruturado receberá melhorias e manutenção, enquanto o DStreams estará apenas no modo de manutenção. Atualmente, o Streaming estruturado não é tão completo em termos de recursos quanto o DStreams para as fontes e coletores que ele suporta prontamente, portanto, avalie seus requisitos para escolher a opção de processamento de fluxo Spark apropriada.
Fluxos como tabelas
O Spark Structured Streaming representa um fluxo de dados como uma tabela que é ilimitada em profundidade, ou seja, a tabela continua a crescer à medida que novos dados chegam. Esta tabela de entrada é processada continuamente por uma consulta de longa execução e os resultados enviados para uma tabela de saída:

No Structured Streaming, os dados chegam ao sistema e são imediatamente ingeridos em uma tabela de entrada. Você escreve consultas (usando as APIs DataFrame e Dataset) que executam operações nessa tabela de entrada. A saída da consulta produz outra tabela, a tabela de resultados. A tabela de resultados contém os resultados da sua consulta, a partir da qual você extrai dados para um armazenamento de dados externo, como um banco de dados relacional. O tempo de quando os dados são processados da tabela de entrada é controlado pelo intervalo de disparo. Por padrão, o intervalo de gatilho é zero, portanto, o Streaming Estruturado tenta processar os dados assim que eles chegam. Na prática, isso significa que, assim que o Streaming Estruturado terminar de processar a execução da consulta anterior, ele iniciará outra execução de processamento em relação a quaisquer dados recém-recebidos. Você pode configurar o gatilho para ser executado em um intervalo, para que os dados de streaming sejam processados em lotes baseados no tempo.
Os dados nas tabelas de resultados podem conter apenas os dados que são novos desde a última vez que a consulta foi processada (modo de acréscimo), ou a tabela pode ser atualizada sempre que há novos dados para que a tabela inclua todos os dados de saída desde o início da consulta de streaming (modo completo).
Modo de acréscimo
No modo de acréscimo, apenas as linhas adicionadas à tabela de resultados desde a última execução de consulta estão presentes na tabela de resultados e são gravadas no armazenamento externo. Por exemplo, a consulta mais simples apenas copia todos os dados da tabela de entrada para a tabela de resultados inalterada. Cada vez que um intervalo de gatilho decorre, os novos dados são processados e as linhas que representam esses novos dados aparecem na tabela de resultados.
Considere um cenário em que você esteja processando telemetria de sensores de temperatura, como um termostato. Suponha que o primeiro gatilho processou um evento no tempo 00:01 para o dispositivo 1 com uma leitura de temperatura de 95 graus. No primeiro gatilho da consulta, apenas a linha com o tempo 00:01 aparece na tabela de resultados. No tempo 00:02 quando outro evento chega, a única nova linha é a linha com tempo 00:02 e, portanto, a tabela de resultados conteria apenas essa linha.
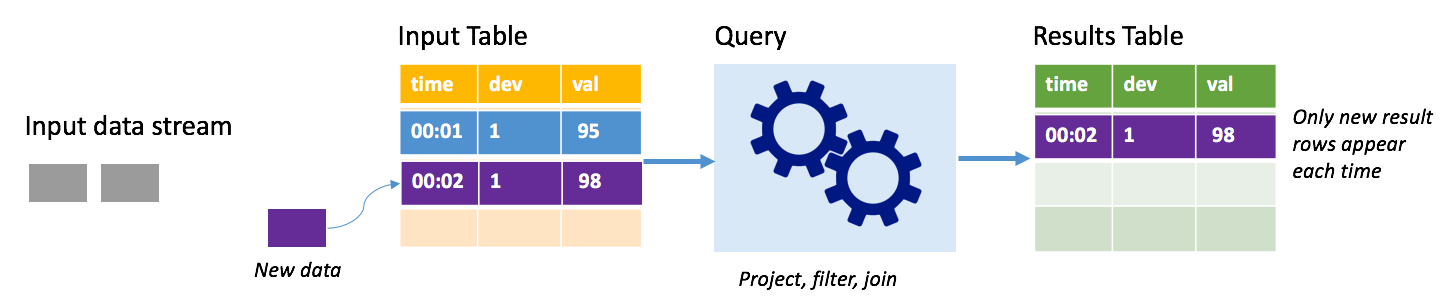
Ao usar o modo de acréscimo, sua consulta estaria aplicando projeções (selecionando as colunas que lhe interessam), filtrando (selecionando apenas linhas que correspondem a determinadas condições) ou unindo (aumentando os dados com dados de uma tabela de pesquisa estática). O modo de acréscimo facilita o envio apenas dos novos pontos de dados relevantes para o armazenamento externo.
Modo completo
Considere o mesmo cenário, desta vez usando o modo completo. No modo completo, toda a tabela de saída é atualizada em cada gatilho para que a tabela inclua dados não apenas da execução de gatilho mais recente, mas de todas as execuções. Você pode usar o modo completo para copiar os dados inalterados da tabela de entrada para a tabela de resultados. Em cada execução acionada, as novas linhas de resultado aparecem junto com todas as linhas anteriores. A tabela de resultados de saída acabará armazenando todos os dados coletados desde o início da consulta e você acabará ficando sem memória. O modo completo destina-se ao uso com consultas agregadas que resumem os dados recebidos de alguma forma, portanto, em cada disparador, a tabela de resultados é atualizada com um novo resumo.
Suponha que até agora há cinco segundos de dados já processados, e é hora de processar os dados pelo sexto segundo. A tabela de entrada tem eventos para o tempo 00:01 e o tempo 00:03. O objetivo desta consulta de exemplo é fornecer a temperatura média do dispositivo a cada cinco segundos. A implementação dessa consulta aplica uma agregação que usa todos os valores que estão dentro de cada janela de 5 segundos, calcula a média da temperatura e produz uma linha para a temperatura média nesse intervalo. No final da primeira janela de 5 segundos, há duas tuplas: (00:01, 1, 95) e (00:03, 1, 98). Assim, para a janela 00:00-00:05 a agregação produz uma tupla com a temperatura média de 96,5 graus. Na próxima janela de 5 segundos, há apenas um ponto de dados no tempo 00:06, então a temperatura média resultante é de 98 graus. No momento 00:10, usando o modo completo, a tabela de resultados tem as linhas para ambas as janelas 00:00-00:05 e 00:05-00:10 porque a consulta gera todas as linhas agregadas, não apenas as novas. Portanto, a tabela de resultados continua a crescer à medida que novas janelas são adicionadas.
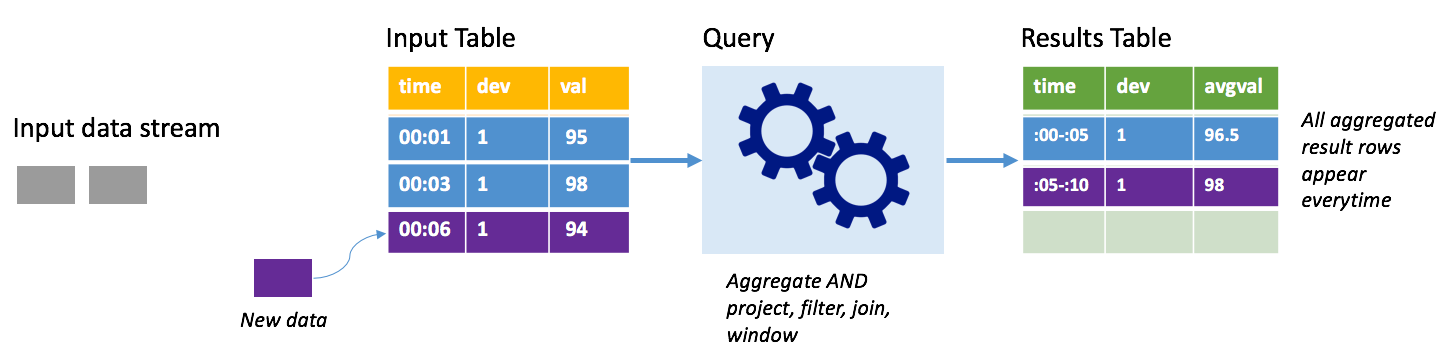
Nem todas as consultas usando o modo completo farão com que a tabela cresça sem limites. Considere no exemplo anterior que, em vez de calcular a média da temperatura por janela de tempo, ela calculava a média por ID do dispositivo. A tabela de resultados contém um número fixo de linhas (uma por dispositivo) com a temperatura média do dispositivo em todos os pontos de dados recebidos desse dispositivo. À medida que novas temperaturas são recebidas, a tabela de resultados é atualizada para que as médias na tabela estejam sempre atualizadas.
Componentes de um aplicativo Spark Structured Streaming
Um exemplo simples de consulta pode resumir as leituras de temperatura por janelas de uma hora. Nesse caso, os dados são armazenados em arquivos JSON no Armazenamento do Azure (anexados como o armazenamento padrão para o cluster HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Esses arquivos JSON são armazenados na temps subpasta abaixo do contêiner do cluster HDInsight.
Definir a fonte de entrada
Primeiro, configure um DataFrame que descreva a fonte dos dados e quaisquer configurações exigidas por essa fonte. Este exemplo extrai dos arquivos JSON no Armazenamento do Azure e aplica um esquema a eles em tempo de leitura.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Aplicar a consulta
Em seguida, aplique uma consulta que contenha as operações desejadas em relação ao Streaming DataFrame. Nesse caso, uma agregação agrupa todas as linhas em janelas de 1 hora e, em seguida, calcula as temperaturas mínimas, médias e máximas nessa janela de 1 hora.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Definir o coletor de saída
Em seguida, defina o destino para as linhas que são adicionadas à tabela de resultados dentro de cada intervalo de gatilho. Este exemplo apenas envia todas as linhas para uma tabela temps na memória que você pode consultar posteriormente com o SparkSQL. O modo de saída completo garante que todas as linhas de todas as janelas sejam sempre saídas.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Iniciar a consulta
Inicie a consulta de streaming e execute até que um sinal de terminação seja recebido.
val query = streamingOutDF.start()
Ver os resultados
Enquanto a consulta está em execução, no mesmo SparkSession, você pode executar uma consulta SparkSQL na temps tabela onde os resultados da consulta são armazenados.
select * from temps
Esta consulta produz resultados semelhantes aos seguintes:
| janela | min(temp) | média (temp) | max (temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Para obter detalhes sobre a API do Spark Structured Stream, juntamente com as fontes de dados de entrada, operações e coletores de saída suportados, consulte Apache Spark Structured Streaming Programming Guide.
Logs de ponto de verificação e write-ahead
Para oferecer resiliência e tolerância a falhas, o Streaming Estruturado depende de pontos de verificação para garantir que o processamento de fluxo possa continuar ininterruptamente, mesmo com falhas de nós. No HDInsight, o Spark cria pontos de verificação para armazenamento durável, Armazenamento do Azure ou Armazenamento Data Lake. Esses pontos de verificação armazenam as informações de progresso sobre a consulta de streaming. Além disso, o Streaming Estruturado usa um log write-ahead (WAL). A WAL captura dados ingeridos que foram recebidos, mas ainda não processados por uma consulta. Se ocorrer uma falha e o processamento for reiniciado a partir do WAL, os eventos recebidos da origem não serão perdidos.
Implantando aplicativos do Spark Streaming
Normalmente, você cria um aplicativo Spark Streaming localmente em um arquivo JAR e, em seguida, implanta-o no Spark no HDInsight copiando o arquivo JAR para o armazenamento padrão anexado ao cluster HDInsight. Você pode iniciar seu aplicativo com as APIs REST do Apache Livy disponíveis em seu cluster usando uma operação POST. O corpo do POST inclui um documento JSON que fornece o caminho para seu JAR, o nome da classe cujo método principal define e executa o aplicativo de streaming e, opcionalmente, os requisitos de recursos do trabalho (como o número de executores, memória e núcleos) e quaisquer definições de configuração que seu código de aplicativo exija.
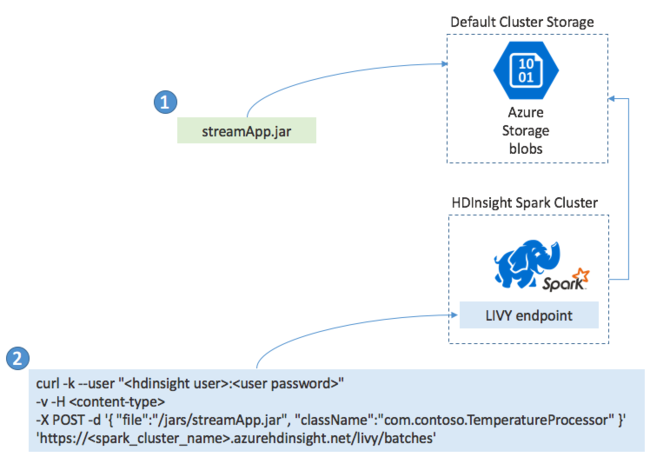
O status de todos os aplicativos também pode ser verificado com uma solicitação GET em relação a um ponto de extremidade LIVY. Finalmente, você pode encerrar um aplicativo em execução emitindo uma solicitação DELETE contra o ponto de extremidade LIVY. Para obter detalhes sobre a API LIVY, consulte Trabalhos remotos com o Apache LIVY