Analise logs de telemetria do Application Insights com o Apache Spark no HDInsight
Saiba como usar o Apache Spark no HDInsight para analisar dados de telemetria do Application Insight.
O Visual Studio Application Insights é um serviço de análise que monitora seus aplicativos Web. Os dados de telemetria gerados pelo Application Insights podem ser exportados para o Armazenamento do Azure. Quando os dados estiverem no Armazenamento do Azure, o HDInsight poderá ser usado para analisá-los.
Pré-requisitos
Um aplicativo configurado para usar o Application Insights.
Familiaridade com a criação de um cluster HDInsight baseado em Linux. Para obter mais informações, consulte Criar o Apache Spark no HDInsight.
Um navegador da Web.
Os seguintes recursos foram utilizados no desenvolvimento e teste deste documento:
Os dados de telemetria do Application Insights foram gerados usando um aplicativo Web Node.js configurado para usar o Application Insights.
Um cluster Spark on HDInsight baseado em Linux versão 3.5 foi usado para analisar os dados.
Arquitetura e planeamento
O diagrama a seguir ilustra a arquitetura de serviço deste exemplo:
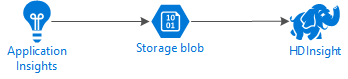
Armazenamento do Azure
O Application Insights pode ser configurado para exportar continuamente informações de telemetria para blobs. O HDInsight pode então ler os dados armazenados nos blobs. No entanto, existem alguns requisitos que você deve seguir:
Local: se a Conta de Armazenamento e o HDInsight estiverem em locais diferentes, isso poderá aumentar a latência. Também aumenta os custos, uma vez que são aplicadas taxas de saída aos dados que se deslocam entre regiões.
Aviso
Não há suporte para o uso de uma Conta de Armazenamento em um local diferente do HDInsight.
Tipo de blob: o HDInsight suporta apenas blobs de bloco. O padrão do Application Insights é usar blobs de bloco, portanto, deve funcionar por padrão com o HDInsight.
Para obter informações sobre como adicionar armazenamento a um cluster existente, consulte o documento Adicionar contas de armazenamento adicionais.
Esquema de dados
O Application Insights fornece informações de modelo de dados de exportação para o formato de dados de telemetria exportado para blobs. As etapas neste documento usam o Spark SQL para trabalhar com os dados. O Spark SQL pode gerar automaticamente um esquema para a estrutura de dados JSON registrada pelo Application Insights.
Exportar dados de telemetria
Siga as etapas em Configurar exportação contínua para configurar seu Application Insights para exportar informações de telemetria para um blob de armazenamento do Azure.
Configurar o HDInsight para acessar os dados
Se você estiver criando um cluster HDInsight, adicione a conta de armazenamento durante a criação do cluster.
Para adicionar a Conta de Armazenamento do Azure a um cluster existente, use as informações no documento Adicionar Contas de Armazenamento adicionais.
Analise os dados: PySpark
Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net/jupyteronde CLUSTERNAME é o nome do cluster.No canto superior direito da página Jupyter, selecione Novo e, em seguida , PySpark. Uma nova guia do navegador contendo um Jupyter Notebook baseado em Python é aberta.
No primeiro campo (chamado de célula) da página, digite o seguinte texto:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Esse código configura o Spark para acessar recursivamente a estrutura de diretórios para os dados de entrada. A telemetria do Application Insights é registrada em uma estrutura de diretórios semelhante ao
/{telemetry type}/YYYY-MM-DD/{##}/.Use SHIFT+ENTER para executar o código. No lado esquerdo da célula, aparece um '*' entre parênteses para indicar que o código nesta célula está a ser executado. Uma vez concluído, o '*' muda para um número, e a saída semelhante ao seguinte texto é exibida abaixo da célula:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Uma nova célula é criada abaixo da primeira. Insira o seguinte texto na nova célula. Substitua
CONTAINEReSTORAGEACCOUNTpelo nome da conta de Armazenamento do Azure e nome do contêiner de blob que contém dados do Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Use SHIFT+ENTER para executar esta célula. Você verá um resultado semelhante ao seguinte texto:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831O caminho wasbs retornado é o local dos dados de telemetria do Application Insights. Altere a
hdfs dfs -lslinha na célula para usar o caminho wasbs retornado e, em seguida, use SHIFT+ENTER para executar a célula novamente. Desta vez, os resultados devem exibir os diretórios que contêm dados de telemetria.Nota
Para o restante das etapas desta seção, o
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsdiretório foi usado. Sua estrutura de diretórios pode ser diferente.Na célula seguinte, insira o seguinte código: Substitua
WASB_PATHpelo caminho da etapa anterior.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Esse código cria um dataframe a partir dos arquivos JSON exportados pelo processo de exportação contínua. Use SHIFT+ENTER para executar esta célula.
Na próxima célula, insira e execute o seguinte para exibir o esquema que o Spark criou para os arquivos JSON:
jsonData.printSchema()O esquema para cada tipo de telemetria é diferente. O exemplo a seguir é o esquema gerado para solicitações da Web (dados armazenados no
Requestssubdiretório):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Use o seguinte para registrar o dataframe como uma tabela temporária e executar uma consulta nos dados:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Esta consulta retorna as informações da cidade para os 20 principais registros onde context.location.city não é nulo.
Nota
A estrutura de contexto está presente em toda a telemetria registrada pelo Application Insights. O elemento cidade pode não ser preenchido em seus logs. Use o esquema para identificar outros elementos que você pode consultar que podem conter dados para seus logs.
Esta consulta retorna informações semelhantes ao seguinte texto:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Analise os dados: Scala
Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net/jupyteronde CLUSTERNAME é o nome do cluster.No canto superior direito da página Jupyter, selecione Novo e, em seguida , Scala. Uma nova guia do navegador contendo um Jupyter Notebook baseado em Scala é exibido.
No primeiro campo (chamado de célula) da página, digite o seguinte texto:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Esse código configura o Spark para acessar recursivamente a estrutura de diretórios para os dados de entrada. A telemetria do Application Insights é registrada em uma estrutura de diretórios semelhante ao
/{telemetry type}/YYYY-MM-DD/{##}/.Use SHIFT+ENTER para executar o código. No lado esquerdo da célula, aparece um '*' entre parênteses para indicar que o código nesta célula está a ser executado. Uma vez concluído, o '*' muda para um número, e a saída semelhante ao seguinte texto é exibida abaixo da célula:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Uma nova célula é criada abaixo da primeira. Insira o seguinte texto na nova célula. Substitua
CONTAINEReSTORAGEACCOUNTpelo nome da conta de Armazenamento do Azure e nome do contêiner de blob que contém logs do Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Use SHIFT+ENTER para executar esta célula. Você verá um resultado semelhante ao seguinte texto:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831O caminho wasbs retornado é o local dos dados de telemetria do Application Insights. Altere a
hdfs dfs -lslinha na célula para usar o caminho wasbs retornado e, em seguida, use SHIFT+ENTER para executar a célula novamente. Desta vez, os resultados devem exibir os diretórios que contêm dados de telemetria.Nota
Para o restante das etapas desta seção, o
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsdiretório foi usado. Esse diretório pode não existir, a menos que seus dados de telemetria sejam para um aplicativo Web.Na célula seguinte, insira o seguinte código: Substitua
WASB\_PATHpelo caminho da etapa anterior.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Esse código cria um dataframe a partir dos arquivos JSON exportados pelo processo de exportação contínua. Use SHIFT+ENTER para executar esta célula.
Na próxima célula, insira e execute o seguinte para exibir o esquema que o Spark criou para os arquivos JSON:
jsonData.printSchemaO esquema para cada tipo de telemetria é diferente. O exemplo a seguir é o esquema gerado para solicitações da Web (dados armazenados no
Requestssubdiretório):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Use o seguinte para registrar o dataframe como uma tabela temporária e executar uma consulta nos dados:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Esta consulta retorna as informações da cidade para os 20 principais registros onde context.location.city não é nulo.
Nota
A estrutura de contexto está presente em toda a telemetria registrada pelo Application Insights. O elemento cidade pode não ser preenchido em seus logs. Use o esquema para identificar outros elementos que você pode consultar que podem conter dados para seus logs.
Esta consulta retorna informações semelhantes ao seguinte texto:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Próximos passos
Para obter mais exemplos de como usar o Apache Spark para trabalhar com dados e serviços no Azure, consulte os seguintes documentos:
- Apache Spark com BI: execute análise de dados interativa usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever resultados de inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Para obter informações sobre como criar e executar aplicativos Spark, consulte os seguintes documentos: