Resolver problemas do HDFS do Apache Hadoop com o Azure HDInsight
Conheça os principais problemas e resoluções ao trabalhar com o Hadoop Distributed File System (HDFS). Para obter uma lista completa de comandos, consulte o Guia de Comandos do HDFS e o Guia do Shell do Sistema de Arquivos.
Como posso aceder ao HDFS local a partir de um cluster?
Problema
Acesse o HDFS local a partir da linha de comando e do código do aplicativo em vez de usar o armazenamento de Blob do Azure ou o Armazenamento do Azure Data Lake de dentro do cluster HDInsight.
Passos de resolução
No prompt de comando, use
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...literalmente, como no seguinte comando:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userDo código-fonte, use o URI
hdfs://mycluster/literalmente, como no seguinte aplicativo de exemplo:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Execute o arquivo .jar compilado (por exemplo, um arquivo chamado
java-unit-tests-1.0.jar) no cluster HDInsight com o seguinte comando:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Exceção de armazenamento para gravação em blob
Problema
Ao usar os hadoop comandos ou hdfs dfs para gravar arquivos com ~12 GB ou mais em um cluster HBase, você pode se deparar com o seguinte erro:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Motivo
HBase em clusters HDInsight padrão para um tamanho de bloco de 256 KB ao gravar no armazenamento do Azure. Embora funcione para APIs do HBase ou APIs REST, ele resulta em um erro ao usar os utilitários de linha de hadoop comando ou hdfs dfs de comando.
Resolução
Use fs.azure.write.request.size para especificar um tamanho de bloco maior. Você pode fazer essa modificação por uso usando o -D parâmetro. O comando a seguir é um exemplo usando esse parâmetro com o hadoop comando:
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
Você também pode aumentar o valor globalmente fs.azure.write.request.size usando o Apache Ambari. As etapas a seguir podem ser usadas para alterar o valor na interface do usuário da Web do Ambari:
No navegador, vá para a interface do usuário da Web do Ambari para seu cluster. O URL é
https://CLUSTERNAME.azurehdinsight.net, ondeCLUSTERNAMEé o nome do cluster. Quando solicitado, digite o nome de administrador e a senha do cluster.No lado esquerdo da tela, selecione HDFS e, em seguida, selecione a guia Configurações .
No campo Filtro..., digite
fs.azure.write.request.size.Altere o valor de 262144 (256 KB) para o novo valor. Por exemplo, 4194304 (4 MB).
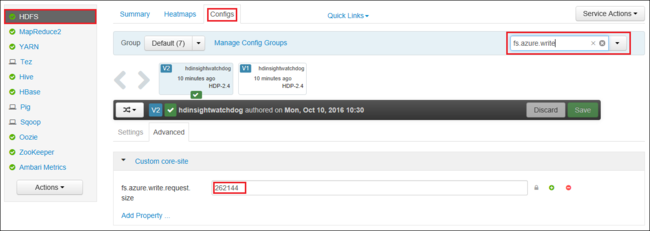
Para obter mais informações sobre como usar o Ambari, consulte Gerenciar clusters HDInsight usando a interface do usuário da Web do Apache Ambari.
Du
O -du comando exibe tamanhos de arquivos e diretórios contidos no diretório fornecido ou o comprimento de um arquivo, caso seja apenas um arquivo.
A -s opção produz um resumo agregado dos comprimentos de arquivo que estão sendo exibidos.
A -h opção formata os tamanhos dos arquivos.
Exemplo:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
RM
O comando -rm exclui arquivos especificados como argumentos.
Exemplo:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Próximos passos
Se não viu o problema ou não conseguiu resolvê-lo, visite um dos seguintes canais para obter mais suporte:
Obtenha respostas de especialistas do Azure através do Suporte da Comunidade do Azure.
Conecte-se com o @AzureSupport - a conta oficial do Microsoft Azure para melhorar a experiência do cliente. Ligar a comunidade do Azure aos recursos certos: respostas, suporte e especialistas.
Se precisar de mais ajuda, você pode enviar uma solicitação de suporte do portal do Azure. Selecione Suporte na barra de menus ou abra o hub Ajuda + suporte . Para obter informações mais detalhadas, consulte Como criar uma solicitação de suporte do Azure. O acesso ao suporte para Gestão de Subscrições e faturação está incluído na sua subscrição do Microsoft Azure e o Suporte Técnico é disponibilizado através de um dos Planos de Suporte do Azure.