Operacionalizar um pipeline de análise de dados
Os pipelines de dados estão subjacentes a muitas soluções de análise de dados. Como o nome sugere, um pipeline de dados recebe dados brutos, limpa e remodela conforme necessário e, em seguida, normalmente executa cálculos ou agregações antes de armazenar os dados processados. Os dados processados são consumidos por clientes, relatórios ou APIs. Um pipeline de dados deve fornecer resultados repetíveis, seja em um cronograma ou quando acionado por novos dados.
Este artigo descreve como operacionalizar seus pipelines de dados para repetibilidade, usando o Oozie em execução em clusters Hadoop HDInsight. O cenário de exemplo orienta você por um pipeline de dados que prepara e processa dados de séries cronológicas de voos de companhias aéreas.
No cenário a seguir, os dados de entrada são um arquivo simples contendo um lote de dados de voo por um mês. Esses dados de voo incluem informações como o aeroporto de origem e destino, as milhas voadas, os horários de partida e chegada, e assim por diante. O objetivo com este pipeline é resumir o desempenho diário das companhias aéreas, onde cada companhia aérea tem uma fila para cada dia, com a média de atrasos de partida e chegada em minutos, e o total de milhas voadas naquele dia.
| YEAR | MONTH | DAY_OF_MONTH | TRANSPORTADORA | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
O pipeline de exemplo aguarda até que os dados de voo de um novo período de tempo cheguem e, em seguida, armazena essas informações detalhadas de voo em seu data warehouse do Apache Hive para análises de longo prazo. O pipeline também cria um conjunto de dados muito menor que resume apenas os dados diários de voo. Esses dados de resumo de voo diário são enviados para um Banco de Dados SQL para fornecer relatórios, como para um site.
O diagrama a seguir ilustra o pipeline de exemplo.
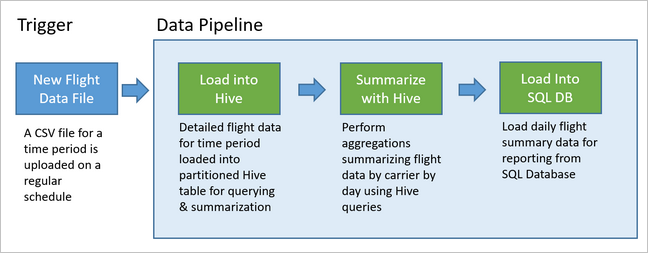
Visão geral da solução Apache Oozie
Esse pipeline usa o Apache Oozie em execução em um cluster Hadoop HDInsight.
O Oozie descreve seus pipelines em termos de ações, fluxos de trabalho e coordenadores. As ações determinam o trabalho real a ser executado, como a execução de uma consulta do Hive. Os fluxos de trabalho definem a sequência de ações. Os coordenadores definem o cronograma para quando o fluxo de trabalho é executado. Os coordenadores também podem aguardar a disponibilidade de novos dados antes de iniciar uma instância do fluxo de trabalho.
O diagrama a seguir mostra o design de alto nível deste pipeline Oozie de exemplo.
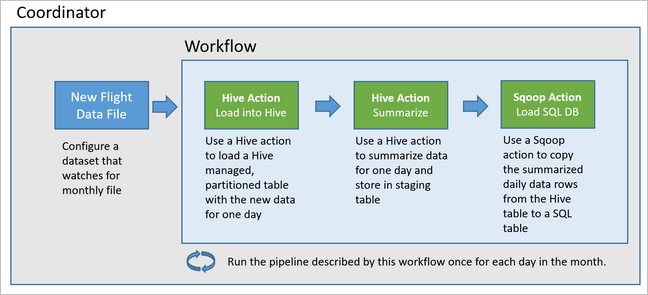
Provisionar recursos do Azure
Esse pipeline requer um Banco de Dados SQL do Azure e um cluster Hadoop HDInsight no mesmo local. O Banco de Dados SQL do Azure armazena os dados de resumo produzidos pelo pipeline e pelo Repositório de Metadados do Oozie.
Provisionar o Banco de Dados SQL do Azure
Crie um Banco de Dados SQL do Azure. Consulte Criar um Banco de Dados SQL do Azure no portal do Azure.
Para garantir que seu cluster HDInsight possa acessar o Banco de Dados SQL do Azure conectado, configure as regras de firewall do Banco de Dados SQL do Azure para permitir que os serviços e recursos do Azure acessem o servidor. Você pode habilitar essa opção no portal do Azure selecionando Definir firewall do servidor e selecionando ATIVADO abaixo de Permitir que os serviços e recursos do Azure acessem este servidor para o Banco de Dados SQL do Azure. Para obter mais informações, veja Criar e gerir regras de firewall de IP.
Use o Editor de consultas para executar as seguintes instruções SQL para criar a
dailyflightstabela que armazenará os dados resumidos de cada execução do pipeline.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Seu Banco de Dados SQL do Azure agora está pronto.
Provisionar um cluster Apache Hadoop
Crie um cluster Apache Hadoop com um metastore personalizado. Durante a criação do cluster a partir do portal, na guia Armazenamento , certifique-se de selecionar seu Banco de Dados SQL em Configurações do Metastore. Para obter mais informações sobre como selecionar um metastore, consulte Selecionar um metastore personalizado durante a criação do cluster. Para obter mais informações sobre a criação de clusters, consulte Introdução ao HDInsight no Linux.
Verificar a configuração do túnel SSH
Para usar o Console da Web Oozie para exibir o status do coordenador e das instâncias de fluxo de trabalho, configure um túnel SSH para o cluster HDInsight. Para obter mais informações, consulte Túnel SSH.
Nota
Também pode utilizar o Chrome com a extensão Foxy Proxy para procurar os recursos Web do cluster através do túnel SSH. Configure-o para proxy de todas as solicitações através do host localhost na porta 9876 do túnel. Esta abordagem é compatível com o Subsistema Windows para Linux, também conhecido como Bash no Windows 10.
Execute o seguinte comando para abrir um túnel SSH para o cluster, onde
CLUSTERNAMEé o nome do cluster:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netVerifique se o túnel está operacional navegando até Ambari no nó principal navegando para:
http://headnodehost:8080Para acessar o Oozie Web Console de dentro do Ambari, navegue até Oozie>Quick Links> [Ative server] >Oozie Web UI.
Configurar o Hive
Carregar dados
Faça o download de um arquivo CSV de exemplo que contém dados de voo por um mês. Baixe seu arquivo
2017-01-FlightData.zipZIP do repositório GitHub do HDInsight e descompacte-o para o arquivo2017-01-FlightData.csvCSV.Copie este ficheiro CSV para a conta de Armazenamento do Azure anexada ao cluster HDInsight e coloque-o
/example/data/flightsna pasta.Use o SCP para copiar os arquivos da máquina local para o armazenamento local do nó principal do cluster HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvUse o comando ssh para se conectar ao cluster. Edite o comando abaixo substituindo
CLUSTERNAMEpelo nome do cluster e digite o comando:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netNa sessão ssh, use o comando HDFS para copiar o arquivo do armazenamento local do nó principal para o Armazenamento do Azure.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Criar tabelas
Os dados de exemplo já estão disponíveis. No entanto, o pipeline requer duas tabelas Hive para processamento, uma para os dados de entrada (rawFlights) e outra para os dados resumidos (flights). Crie essas tabelas no Ambari da seguinte maneira.
Faça login no Ambari navegando até
http://headnodehost:8080.Na lista de serviços, selecione Hive.
Selecione Ir para visualização ao lado do rótulo Hive View 2.0.
Na área de texto da consulta, cole as instruções a seguir para criar a
rawFlightstabela. ArawFlightstabela fornece um esquema em leitura para os arquivos CSV dentro da/example/data/flightspasta no Armazenamento do Azure.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Selecione Executar para criar a tabela.
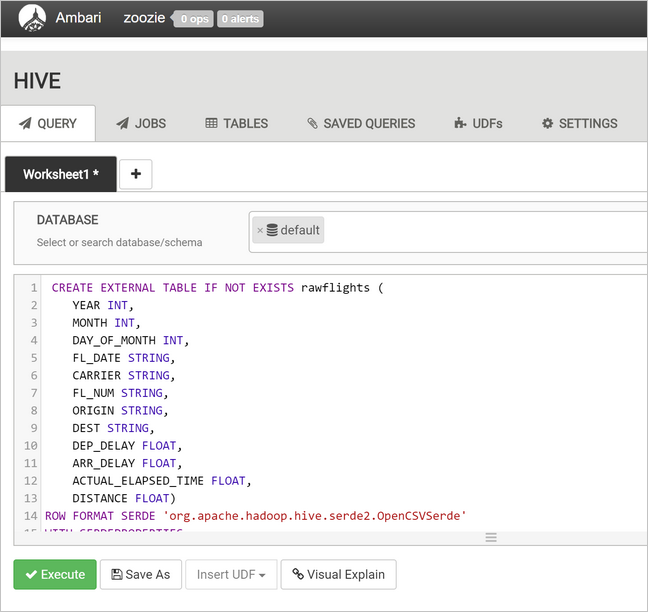
Para criar a
flightstabela, substitua o texto na área de texto da consulta pelas instruções a seguir. Aflightstabela é uma tabela gerenciada pelo Hive que particiona os dados carregados nela por ano, mês e dia do mês. Esta tabela conterá todos os dados históricos de voo, com a menor granularidade presente nos dados de origem de uma linha por voo.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Selecione Executar para criar a tabela.
Criar o fluxo de trabalho do Oozie
Os pipelines normalmente processam dados em lotes por um determinado intervalo de tempo. Neste caso, o pipeline processa os dados de voo diariamente. Essa abordagem permite que os arquivos CSV de entrada cheguem diariamente, semanalmente, mensalmente ou anualmente.
O fluxo de trabalho de exemplo processa os dados de voo diariamente, em três etapas principais:
- Execute uma consulta do Hive para extrair os dados do intervalo de datas desse dia do arquivo CSV de origem representado pela
rawFlightstabela e insira os dados naflightstabela. - Execute uma consulta do Hive para criar dinamicamente uma tabela de preparo no Hive para o dia, que contém uma cópia dos dados de voo resumidos por dia e transportadora.
- Use o Apache Sqoop para copiar todos os dados da tabela de preparo diária no Hive para a tabela de destino
dailyflightsno Banco de Dados SQL do Azure. O Sqoop lê as linhas de origem dos dados por trás da tabela do Hive que reside no Armazenamento do Azure e as carrega no Banco de Dados SQL usando uma conexão JDBC.
Essas três etapas são coordenadas por um fluxo de trabalho do Oozie.
Na estação de trabalho local, crie um arquivo chamado
job.properties. Use o texto abaixo como o conteúdo inicial do arquivo. Em seguida, atualize os valores para seu ambiente específico. A tabela abaixo do texto resume cada uma das propriedades e indica onde você pode encontrar os valores para seu próprio ambiente.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Property Fonte de valor nomeNode O caminho completo para o Contêiner de Armazenamento do Azure anexado ao cluster HDInsight. jobTracker O nome do host interno para o nó principal YARN do cluster ativo. Na página inicial do Ambari, selecione YARN na lista de serviços e, em seguida, escolha Ative Resource Manager. O URI do nome do host é exibido na parte superior da página. Anexe a porta 8050. queueName O nome da fila YARN usada ao agendar as ações do Hive. Não altere a predefinição. oozie.use.system.libpath Deixe como verdade. appBase O caminho para a subpasta no Armazenamento do Azure onde você implanta o fluxo de trabalho do Oozie e os arquivos de suporte. oozie.wf.application.path O local do fluxo de trabalho workflow.xmldo Oozie a ser executado.hiveScriptLoadPartition O caminho no Armazenamento do Azure para o arquivo de hive-load-flights-partition.hqlconsulta do Hive .hiveScriptCreateDailyTable O caminho no Armazenamento do Azure para o arquivo de hive-create-daily-summary-table.hqlconsulta do Hive .hiveDailyTableName O nome gerado dinamicamente a ser usado para a tabela de preparo. hiveDataFolder O caminho no Armazenamento do Azure para os dados contidos pela tabela de preparo. sqlDatabaseConnectionString A cadeia de conexão de sintaxe JDBC para seu Banco de Dados SQL do Azure. sqlDatabaseTableName O nome da tabela no Banco de Dados SQL do Azure na qual as linhas de resumo são inseridas. Deixe como dailyflights.ano O componente ano do dia para o qual os resumos de voo são calculados. Deixe como está. mês O componente mês do dia para o qual os resumos de voo são calculados. Deixe como está. Dia O componente dia do mês do dia para o qual os resumos de voo são calculados. Deixe como está. Na estação de trabalho local, crie um arquivo chamado
hive-load-flights-partition.hql. Use o código abaixo como o conteúdo do arquivo.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};As variáveis Oozie usam a sintaxe
${variableName}. Essas variáveis são definidas nojob.propertiesarquivo. Oozie substitui os valores reais em tempo de execução.Na estação de trabalho local, crie um arquivo chamado
hive-create-daily-summary-table.hql. Use o código abaixo como o conteúdo do arquivo.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Esta consulta cria uma tabela de preparo que armazenará apenas os dados resumidos por um dia, tome nota da instrução SELECT que calcula os atrasos médios e o total da distância percorrida pela transportadora por dia. Os dados inseridos nesta tabela armazenados em um local conhecido (o caminho indicado pela variável hiveDataFolder) para que possam ser usados como a fonte para Sqoop na próxima etapa.
Na estação de trabalho local, crie um arquivo chamado
workflow.xml. Use o código abaixo como o conteúdo do arquivo. Essas etapas acima são expressas como ações separadas no arquivo de fluxo de trabalho do Oozie.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
As duas consultas do Hive são acessadas por seu caminho no Armazenamento do Azure e os valores de variáveis restantes são fornecidos pelo job.properties arquivo. Este arquivo configura o fluxo de trabalho para ser executado para a data de 3 de janeiro de 2017.
Implantar e executar o fluxo de trabalho do Oozie
Use o SCP da sessão bash para implantar o fluxo de trabalho do Oozie (workflow.xml), as consultas do Hive (hive-load-flights-partition.hql e hive-create-daily-summary-table.hql) e a configuração do trabalho (job.properties). No Oozie, apenas o job.properties arquivo pode existir no armazenamento local do nó principal. Todos os outros arquivos devem ser armazenados no HDFS, neste caso, o Armazenamento do Azure. A ação Sqoop usada pelo fluxo de trabalho depende de um driver JDBC para comunicação com seu Banco de Dados SQL, que deve ser copiado do nó principal para o HDFS.
Crie a
load_flights_by_daysubpasta abaixo do caminho do usuário no armazenamento local do nó principal. Na sessão ssh aberta, execute o seguinte comando:mkdir load_flights_by_dayCopie todos os arquivos no diretório atual (o
workflow.xmlejob.propertiesarquivos) até aload_flights_by_daysubpasta. Na estação de trabalho local, execute o seguinte comando:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayCopie arquivos de fluxo de trabalho para o HDFS. A partir da sessão ssh aberta, execute os seguintes comandos:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayCopie
mssql-jdbc-7.0.0.jre8.jardo nó principal local para a pasta do fluxo de trabalho no HDFS. Revise o comando conforme necessário se o cluster contiver um arquivo jar diferente. Reviseworkflow.xmlconforme necessário para refletir um arquivo jar diferente. Na sessão ssh aberta, execute o seguinte comando:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayExecutar o fluxo de trabalho. Na sessão ssh aberta, execute o seguinte comando:
oozie job -config job.properties -runObserve o status usando o Oozie Web Console. No Ambari, selecione Oozie, Quick Links e, em seguida, Oozie Web Console. Na guia Trabalhos de Fluxo de Trabalho , selecione Todos os Trabalhos.
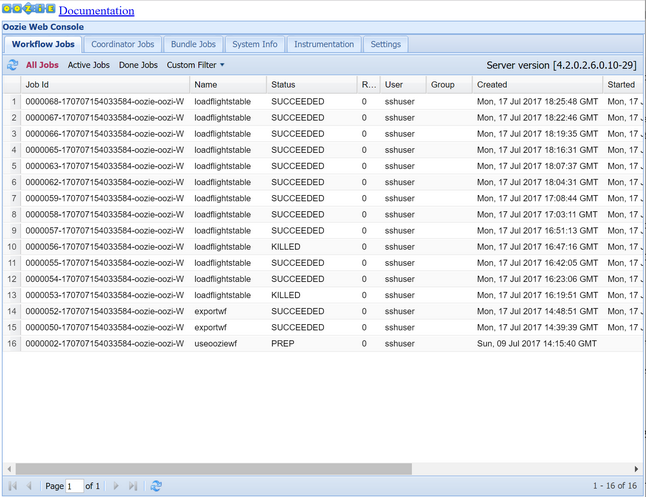
Quando o status for SUCCEEDED, consulte a tabela do Banco de dados SQL para exibir as linhas inseridas. Usando o portal do Azure, navegue até o painel do Banco de Dados SQL, selecione Ferramentas e abra o Editor de Consultas.
SELECT * FROM dailyflights
Agora que o fluxo de trabalho está sendo executado para o único dia de teste, você pode encapsular esse fluxo de trabalho com um coordenador que agenda o fluxo de trabalho para que ele seja executado diariamente.
Executar o fluxo de trabalho com um coordenador
Para agendar esse fluxo de trabalho para que ele seja executado diariamente (ou todos os dias em um intervalo de datas), você pode usar um coordenador. Um coordenador é definido por um ficheiro XML, por exemplo coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Como você pode ver, a maioria do coordenador está apenas passando informações de configuração para a instância do fluxo de trabalho. No entanto, há alguns itens importantes a serem destacados.
Ponto 1: Os
startatributos eendnocoordinator-apppróprio elemento controlam o intervalo de tempo durante o qual o coordenador é executado.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Um coordenador é responsável por agendar ações dentro do
startintervalo eenddatas, de acordo com o intervalo especificado pelofrequencyatributo. Cada ação agendada, por sua vez, executa o fluxo de trabalho conforme configurado. Na definição de coordenador acima, o coordenador está configurado para executar ações de 1º de janeiro de 2017 a 5 de janeiro de 2017. A frequência é definida como um dia pela expressão${coord:days(1)}de frequência Oozie Expression Language . Isso faz com que o coordenador programe uma ação (e, portanto, o fluxo de trabalho) uma vez por dia. Para intervalos de datas anteriores, como neste exemplo, a ação será agendada para ser executada sem demora. O início da data a partir da qual uma ação está agendada para ser executada é chamado de tempo nominal. Por exemplo, para processar os dados para 1 de janeiro de 2017, o coordenador agendará uma ação com uma hora nominal de 2017-01-01T00:00:00 GMT.Ponto 2: Dentro do intervalo de datas do fluxo de trabalho, o
datasetelemento especifica onde procurar no HDFS os dados de um determinado intervalo de datas e configura como o Oozie determina se os dados ainda estão disponíveis para processamento.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>O caminho para os dados no HDFS é construído dinamicamente de acordo com a expressão fornecida no
uri-templateelemento. Neste coordenador, uma frequência de um dia também é usada com o conjunto de dados. Enquanto as datas de início e término no elemento coordenador controlam quando as ações são agendadas (e definem seus tempos nominais), oinitial-instanceefrequencyno conjunto de dados controlam o cálculo da data usada na construção douri-template. Nesse caso, defina a instância inicial para um dia antes do início do coordenador para garantir que ele pegue os dados do primeiro dia (1º de janeiro de 2017). O cálculo da data do conjunto de dados avança a partir do valor deinitial-instance(31/12/2016) avançando em incrementos de frequência do conjunto de dados (um dia) até encontrar a data mais recente que não passa do tempo nominal definido pelo coordenador (2017-01-01T00:00:00 GMT para a primeira ação).O elemento vazio
done-flagindica que, quando o Oozie verifica a presença de dados de entrada no horário marcado, o Oozie determina se os dados estão disponíveis pela presença de um diretório ou arquivo. Neste caso, é a presença de um arquivo csv. Se um arquivo csv estiver presente, o Oozie assumirá que os dados estão prontos e iniciará uma instância de fluxo de trabalho para processar o arquivo. Se não houver nenhum arquivo csv presente, o Oozie assumirá que os dados ainda não estão prontos e que a execução do fluxo de trabalho entrará em um estado de espera.Ponto 3: O
data-inelemento especifica o carimbo de data/hora específico a ser usado como a hora nominal ao substituir os valores nouri-templatepara o conjunto de dados associado.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>Nesse caso, defina a instância para a expressão
${coord:current(0)}, que se traduz em usar o tempo nominal da ação conforme originalmente agendado pelo coordenador. Em outras palavras, quando o coordenador agenda a ação para ser executada com um tempo nominal de 01/01/2017, então 01/01/2017 é o que é usado para substituir as variáveis ANO (2017) e MÊS (01) no modelo URI. Depois que o modelo de URI é calculado para essa instância, o Oozie verifica se o diretório ou arquivo esperado está disponível e agenda a próxima execução do fluxo de trabalho de acordo.
Os três pontos anteriores combinam-se para produzir uma situação em que o coordenador agenda o processamento dos dados de origem de uma forma diária.
Ponto 1: O coordenador começa com uma data nominal de 2017-01-01.
Ponto 2: O Oozie procura os dados disponíveis em
sourceDataFolder/2017-01-FlightData.csv.Ponto 3: Quando o Oozie encontra esse arquivo, ele agenda uma instância do fluxo de trabalho que processará os dados para 1º de janeiro de 2017. Oozie então continua o processamento para 2017-01-02. Esta avaliação repete-se até, mas não incluindo, 2017-01-05.
Assim como nos fluxos de trabalho, a configuração de um coordenador é definida em um job.properties arquivo, que tem um superconjunto das configurações usadas pelo fluxo de trabalho.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
As únicas novas propriedades introduzidas neste job.properties ficheiro são:
| Property | Fonte de valor |
|---|---|
| oozie.coord.application.path | Indica o local do coordinator.xml arquivo que contém o coordenador do Oozie a ser executado. |
| hiveDailyTableNamePrefix | O prefixo usado ao criar dinamicamente o nome da tabela de preparo. |
| hiveDataFolderPrefix | O prefixo do caminho onde todas as tabelas de preparo serão armazenadas. |
Implantar e executar o Coordenador do Oozie
Para executar o pipeline com um coordenador, prossiga de forma semelhante à do fluxo de trabalho, exceto se você trabalhar a partir de uma pasta um nível acima da pasta que contém o fluxo de trabalho. Esta convenção de pasta separa os coordenadores dos fluxos de trabalho no disco, para que você possa associar um coordenador a diferentes fluxos de trabalho filho.
Use o SCP da máquina local para copiar os arquivos do coordenador até o armazenamento local do nó principal do cluster.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~SSH no seu nó principal.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netCopie os arquivos do coordenador para o HDFS.
hdfs dfs -put ./* /oozie/Execute o coordenador.
oozie job -config job.properties -runVerifique o status usando o Console da Web do Oozie, desta vez selecionando a guia Trabalhos do coordenador e, em seguida, Todos os trabalhos.
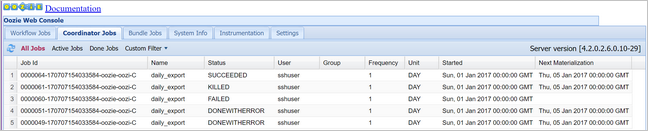
Selecione uma instância de coordenador para exibir a lista de ações agendadas. Neste caso, você deve ver quatro ações com tempos nominais no intervalo de 1º de janeiro de 2017 a 4 de janeiro de 2017.
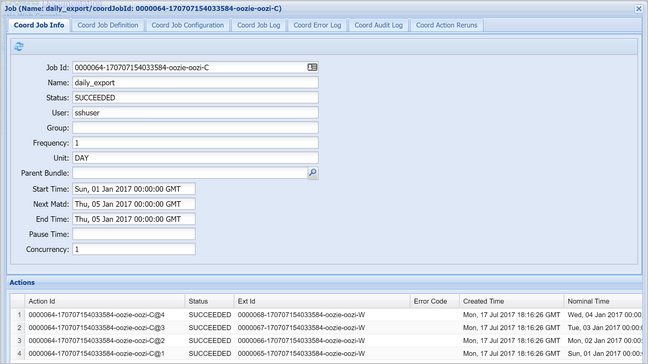
Cada ação nesta lista corresponde a uma instância do fluxo de trabalho que processa um dia de dados, onde o início desse dia é indicado pela hora nominal.