Executar consultas do Apache Hive com as ferramentas do Data Lake para Visual Studio
Saiba como usar as ferramentas Data Lake para Visual Studio para consultar o Apache Hive. As ferramentas Data Lake permitem que você crie, envie e monitore facilmente consultas do Hive para o Apache Hadoop no Azure HDInsight.
Pré-requisitos
Um cluster Apache Hadoop no HDInsight. Para obter informações sobre como criar este item, consulte Criar cluster Apache Hadoop no Azure HDInsight usando o modelo do Gerenciador de Recursos.
Visual Studio. As etapas neste artigo usam o Visual Studio 2019.
Ferramentas do HDInsight para Visual Studio ou ferramentas do Azure Data Lake para Visual Studio. Para obter informações sobre como instalar e configurar as ferramentas, consulte Instalar ferramentas Data Lake para Visual Studio.
Executar consultas do Apache Hive usando o Visual Studio
Tem duas opções para criar e executar consultas do Hive:
- Crie consultas ad-hoc.
- Crie um aplicativo Hive.
Criar uma consulta ad-hoc do Hive
As consultas ad hoc podem ser executadas no modo Batch ou Interativo .
Inicie o Visual Studio e selecione Continuar sem código.
No Gerenciador de Servidores, clique com o botão direito do mouse em Azure, selecione Conectar à Assinatura do Microsoft Azure... e conclua o processo de entrada.
Expanda HDInsight, clique com o botão direito do rato no cluster onde pretende executar a consulta e, em seguida, selecione Escrever uma Consulta do Hive.
Insira a seguinte consulta hive:
SELECT * FROM hivesampletable;Selecione Execute (Executar). O padrão do modo de execução é Interativo.
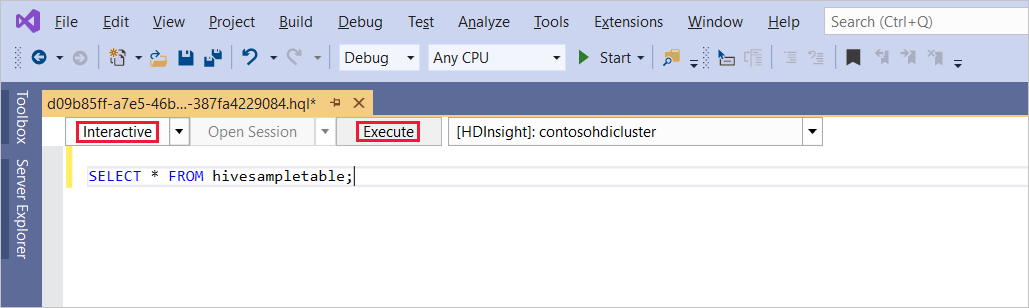
Para executar a mesma consulta no modo Lote , alterne a lista suspensa de Interativo para Lote. O botão de execução muda de Executar para Enviar.

O editor do Hive suporta IntelliSense. O Data Lake Tools para Visual Studio suportam o carregamento de metadados remotos durante a edição do script do Hive. Por exemplo, se você digitar
SELECT * FROM, o IntelliSense listará todos os nomes de tabela sugeridos. Quando é especificado um nome de tabela, o IntelliSense lista os nomes das colunas. As ferramentas suportam quase todas as instruções DML do Hive, subconsultas e os UDFs incorporados. O IntelliSense sugere apenas os metadados do cluster selecionado na barra de ferramentas do HDInsight.Na barra de ferramentas de consulta (a área abaixo da guia de consulta e acima do texto da consulta), selecione Enviar ou selecione a seta suspensa ao lado de Enviar e escolha Avançado na lista suspensa. Se selecionar esta última opção,
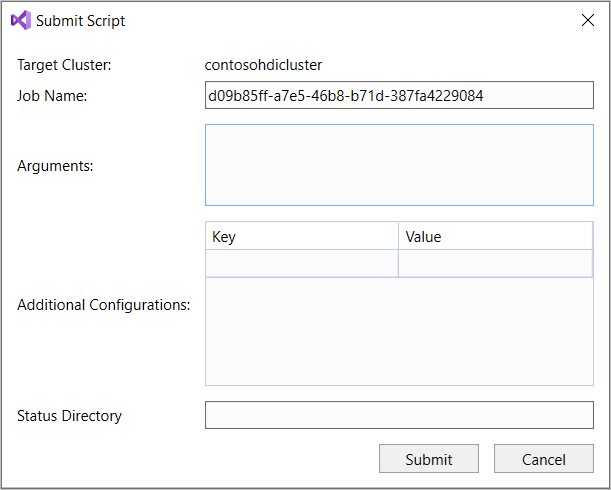
Se você selecionou a opção de envio avançado, configure Nome do trabalho, Argumentos, Configurações adicionais e Diretório de status na caixa de diálogo Enviar script . Em seguida, selecione Enviar.
Criar uma aplicação do Hive
Para executar uma consulta do Hive criando um aplicativo do Hive, siga estas etapas:
Abra o Visual Studio.
Na janela Iniciar, selecione Criar um novo projeto.
Na janela Criar um novo projeto, na caixa Pesquisar modelos, digite Hive. Em seguida, escolha Hive Application e selecione Next.
Na janela Configurar seu novo projeto, insira um nome de projeto, selecione ou crie um local para o novo projeto e, em seguida, selecione Criar.
Abra o arquivo Script.hql que é criado com este projeto e cole as seguintes instruções HiveQL:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Essas declarações executam as seguintes ações:
DROP TABLE: Exclui a tabela, se ela existir.CREATE EXTERNAL TABLE: Cria uma nova tabela 'externa' no Hive. As tabelas externas armazenam apenas a definição de tabela no Hive. (Os dados são deixados no local original.)Nota
As tabelas externas devem ser usadas quando você espera que os dados subjacentes sejam atualizados por uma fonte externa, como um trabalho MapReduce ou um serviço do Azure.
Soltar uma tabela externa não exclui os dados, apenas a definição da tabela.
ROW FORMAT: Informa ao Hive como os dados são formatados. Nesse caso, os campos em cada log são separados por um espaço.STORED AS TEXTFILE LOCATION: Informa ao Hive que os dados são armazenados no diretório example/data e que são armazenados como texto.SELECT: Seleciona uma contagem de todas as linhas onde a colunat4contém o valor[ERROR]. Esta instrução retorna um valor de3, porque três linhas contêm esse valor.INPUT__FILE__NAME LIKE '%.log': Diz ao Hive para retornar apenas dados de arquivos que terminam em .log. Esta cláusula restringe a pesquisa ao arquivo sample.log que contém os dados.
Na barra de ferramentas do arquivo de consulta (que tem uma aparência semelhante à barra de ferramentas de consulta ad-hoc), selecione o cluster HDInsight que você deseja usar para essa consulta. Em seguida, altere Interativo para Lote (se necessário) e selecione Enviar para executar as instruções como um trabalho do Hive.
O Resumo do Trabalho do Hive é exibido e exibe informações sobre o trabalho em execução. Use o link Atualizar para atualizar as informações do trabalho, até que o Status do Trabalho mude para Concluído.
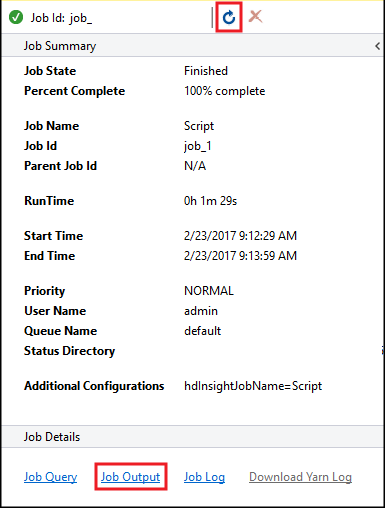
Selecione Saída do trabalho para exibir a saída desse trabalho. Ele exibe
[ERROR] 3, que é o valor retornado por esta consulta.
Exemplo adicional
O exemplo a log4jLogs seguir se baseia na tabela criada no procedimento anterior, Create a Hive application.
No Gerenciador de Servidores, clique com o botão direito do mouse no cluster e selecione Gravar uma consulta do Hive.
Insira a seguinte consulta hive:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Essas declarações executam as seguintes ações:
CREATE TABLE IF NOT EXISTS: Cria uma tabela se ela ainda não existir. Como aEXTERNALpalavra-chave não é usada, essa instrução cria uma tabela interna. As tabelas internas são armazenadas no data warehouse do Hive e gerenciadas pelo Hive.Nota
Ao contrário
EXTERNALdas tabelas, descartar uma tabela interna também exclui os dados subjacentes.STORED AS ORC: Armazena os dados no formato colunar de linha otimizado (ORC). O ORC é um formato altamente otimizado e eficiente para armazenar dados do Hive.INSERT OVERWRITE ... SELECT: Seleciona linhas dalog4jLogstabela que contêm[ERROR]e, em seguida, insere os dados naerrorLogstabela.
Altere Interativo para Lote , se necessário, e selecione Enviar.
Para verificar se o trabalho criou a tabela, vá para o Gerenciador de Servidores e expanda o Azure>HDInsight. Expanda o cluster HDInsight e, em seguida, expanda Bancos de dados>do Hive padrão. A tabela errorLogs e a tabela Log4jLogs são listadas.
Próximos passos
Como você pode ver, as ferramentas do HDInsight para Visual Studio fornecem uma maneira fácil de trabalhar com consultas do Hive no HDInsight.
Para obter informações gerais sobre o Hive no HDInsight, consulte O que é o Apache Hive e o HiveQL no Azure HDInsight?
Para obter informações sobre outras maneiras de trabalhar com o Hadoop no HDInsight, consulte Usar o MapReduce no Apache Hadoop no HDInsight
Para obter mais informações sobre as ferramentas do HDInsight para Visual Studio, consulte Usar ferramentas Data Lake para Visual Studio para se conectar ao Azure HDInsight e executar consultas do Apache Hive