O que é o Apache Flink® no Azure HDInsight no AKS? (Pré-visualização)
Importante
O Azure HDInsight no AKS foi desativado em 31 de janeiro de 2025. Saiba mais com este anúncio.
Você precisa migrar suas cargas de trabalho para Microsoft Fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho.
Importante
Esta funcionalidade está atualmente em pré-visualização. Os Termos de Utilização Suplementares para Pré-visualizações do Microsoft Azure incluem mais termos legais que se aplicam a características do Azure que estão em versão beta, em pré-visualização, ou ainda não disponibilizadas para uso geral. Para obter informações sobre essa visualização específica, consulte Azure HDInsight no AKS informações de visualização. Para perguntas ou sugestões de funcionalidades, envie uma solicitação em AskHDInsight com os detalhes e siga-nos para mais atualizações na Comunidade do Azure HDInsight .
Apache Flink é uma plataforma e motor de processamento distribuído para cálculos com estado em fluxos de dados ilimitados e limitados. O Flink foi projetado para ser executado em todos os ambientes de cluster comuns, executar cálculos e aplicações de streaming com estado à velocidade da memória e em qualquer escala. Os aplicativos são paralelizados em possivelmente milhares de tarefas que são distribuídas e executadas simultaneamente em um cluster. Portanto, um aplicativo pode usar quantidades ilimitadas de vCPUs, memória principal, disco e E/S de rede. Além disso, o Flink mantém facilmente um grande estado de aplicação. O seu algoritmo de ponto de verificação assíncrono e incremental assegura uma influência mínima nas latências de processamento, enquanto garante a consistência do estado exatamente uma vez.
O Apache Flink é um mecanismo de análise massivamente escalável para processamento de fluxo.
Alguns dos principais recursos que o Flink oferece são:
- Operações em fluxos limitados e não limitados
- Desempenho na memória
- Capacidade para streaming e cálculos em lote
- Operações de baixa latência e alta taxa de transferência
- Processamento exatamente uma vez
- Alta Disponibilidade
- Estado e tolerância a falhas
- Totalmente compatível com o ecossistema Hadoop
- APIs SQL unificadas para fluxo e lote
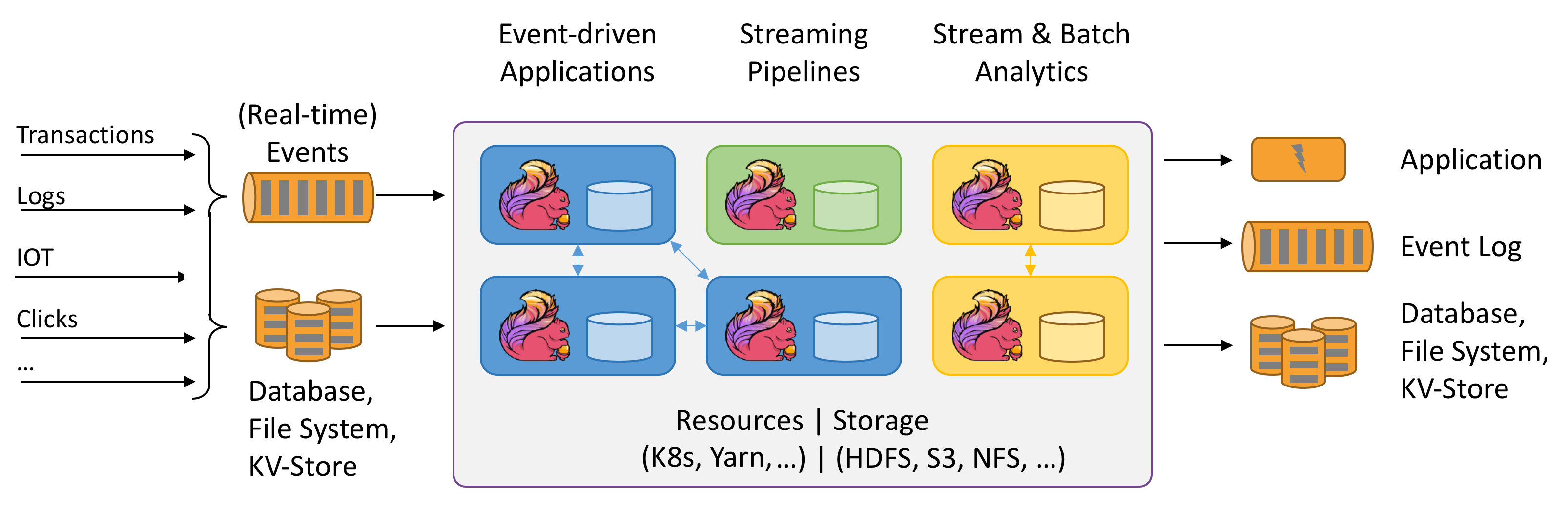
Porquê Apache Flink?
Apache Flink é uma excelente escolha para desenvolver e executar muitos tipos diferentes de aplicações devido ao seu extenso conjunto de recursos. Os recursos do Flink incluem suporte para processamento de fluxo e lote, gerenciamento de estado sofisticado, semântica de processamento de tempo de evento e garantias de consistência de 'exatamente uma vez' para o estado. O Flink não tem um único ponto de falha. Está provado que o Flink é dimensionado para milhares de núcleos e terabytes de estado do aplicativo, oferece alta taxa de transferência e baixa latência e alimenta alguns dos aplicativos de processamento de fluxo mais exigentes do mundo.
- Deteção de Fraude: O Flink pode ser usado para detetar transações ou atividades fraudulentas em tempo real, aplicando regras complexas e modelos de aprendizado de máquina sobre dados em fluxo contínuo.
- Deteção de Anomalias: Flink pode ser usado para identificar valores atípicos ou padrões anormais em dados de streaming, como leituras de sensores, tráfego de rede ou comportamento do utilizador.
- Alertas baseados em regras: O Flink pode ser usado para disparar alertas ou notificações com base em condições predefinidas ou limites em dados de streaming, como temperatura, pressão ou preços de ações.
- de monitoramento de processos de negócios: o Flink pode ser usado para rastrear e analisar o status e o desempenho de processos de negócios ou fluxos de trabalho em tempo real, como atendimento de pedidos, entrega ou atendimento ao cliente.
- aplicação Web (rede social): O Flink pode ser usado para alimentar aplicações Web que requerem processamento em tempo real de dados gerados pelo utilizador, tais como mensagens, gostos, comentários ou recomendações.
Leia mais sobre os casos de uso comuns descritos em casos de uso do Apache Flink
Os clusters Apache Flink no HDInsight no AKS são um serviço totalmente gerenciado. Os benefícios da criação de um cluster Flink no HDInsight no AKS estão listados aqui.
| Funcionalidade | Descrição |
|---|---|
| Facilite a criação | Você pode criar um novo cluster Flink no HDInsight em minutos usando o portal do Azure, o Azure PowerShell ou o SDK. Consulte Introdução ao cluster Apache Flink no HDInsight no AKS. |
| Facilidade de utilização | Os clusters Flink no HDInsight no AKS incluem gerenciamento de configuração baseado em portal e dimensionamento. Além disso com a API de gerenciamento de tarefas, você usa a API REST ou o portal do Azure para gerenciamento de tarefas. |
| REST APIs | Os clusters Flink no HDInsight no AKS incluem API de gerenciamento de tarefas, um método de envio de trabalho Flink baseado em API REST para enviar e monitorar trabalhos remotamente no portal do Azure. |
| Tipo de implantação | Flink pode executar aplicativos no modo de sessão ou modo de aplicativo. Atualmente, o HDInsight no AKS suporta apenas clusters de sessão. Você pode executar vários trabalhos Flink em um cluster de sessão. O modo de aplicativo está no roteiro do HDInsight em clusters AKS |
| Suporte para Metastore | Os clusters Flink no HDInsight em AKS podem suportar catálogos com Hive Metastore em diferentes formatos de ficheiro abertos, com pontos de verificação remotos para o Azure Data Lake Storage Gen2. |
| Suporte para o Armazenamento do Azure | Os clusters Flink no HDInsight podem usar o Azure Data Lake Storage Gen2 como coletor de arquivos. Para obter mais informações sobre o Data Lake Storage Gen2, consulte Azure Data Lake Storage Gen2. |
| Integração com os serviços do Azure | O cluster Flink no HDInsight no AKS vem com uma integração ao Kafka, juntamente com de Hubs de Eventos do Azure e Azure HDInsight. Você pode criar aplicativos de streaming usando os Hubs de Eventos ou o HDInsight. |
| Adaptabilidade | O HDInsight no AKS permite dimensionar os nós do cluster Flink com base na programação com o recurso Autoscale. Consulte Dimensionar automaticamente o Azure HDInsight em clusters AKS. |
| Back-end de estado | O HDInsight no AKS usa o RocksDB como StateBackend padrão. O RocksDB é um armazenamento de chave-valor persistente incorporável para armazenamento rápido. |
| Pontos de verificação | O checkpointing está ativado no HDInsight em clusters AKS por predefinição. As configurações padrão do HDInsight no AKS mantêm os últimos cinco pontos de verificação no armazenamento persistente. Caso a sua tarefa falhe, poderá ser reiniciada a partir do ponto de verificação mais recente. |
| Pontos de verificação incrementais | O RocksDB suporta pontos de verificação incrementais. Incentivamos o uso de pontos de verificação incrementais para estados grandes, você precisa habilitar esse recurso manualmente. Definir um padrão em seu flink-conf.yaml: state.backend.incremental: true permite pontos de verificação incrementais, a menos que o aplicativo substitua essa configuração no código. Esta afirmação é verdadeira por padrão. Como alternativa, você pode configurar esse valor diretamente no código (substitui o padrão de configuração) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); . Por padrão, preservamos os últimos cinco pontos de verificação no diretório de ponto de verificação configurado. Esse valor pode ser alterado alterando a configuração na seção de gerenciamento de configuração state.checkpoints.num-retained: 5 |
Os clusters Apache Flink no HDInsight no AKS incluem os seguintes componentes, eles estão disponíveis nos clusters por padrão.
Consulte o Roteiro no para ver o que está por vir em breve!
Gerenciamento de tarefas Apache Flink
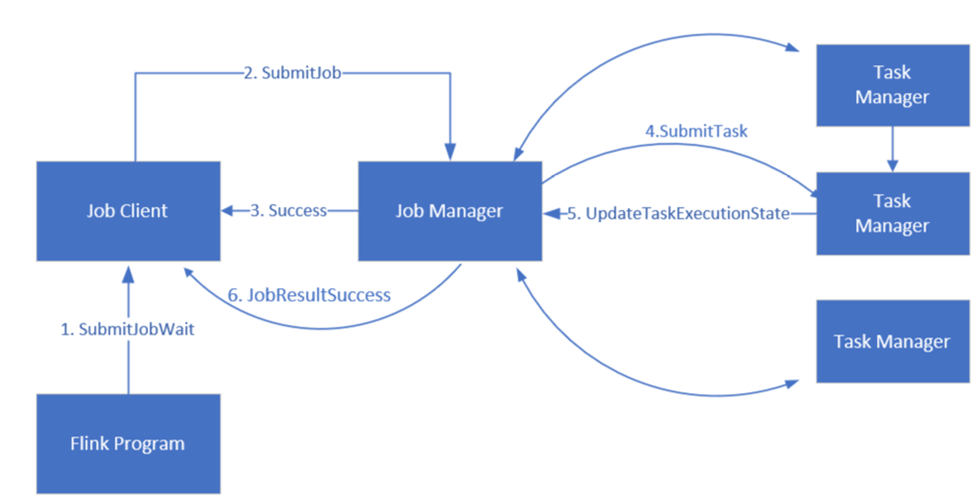
O Flink agenda trabalhos usando três componentes distribuídos: Gerenciador de trabalhos, Gerenciador de tarefas e Cliente de trabalho, que são definidos num padrão de Leader-Follower.
Flink Job: Um trabalho ou programa Flink consiste em várias tarefas. As tarefas são a unidade básica de execução no Flink. Cada tarefa Flink tem várias instâncias, dependendo do nível de paralelismo, e cada instância é executada em um TaskManager.
Job manager: O gestor de trabalhos atua como um agendador e atribui tarefas aos gestores de tarefas.
Gerenciador de tarefas: Os gerentes de tarefas vêm com um ou mais slots para executar tarefas em paralelo.
Job client: O cliente de tarefa comunica-se com o gestor de tarefas para submeter tarefas Flink
Flink Web UI: O Flink apresenta uma interface do usuário da Web para inspecionar, monitorar e depurar aplicativos em execução.
Referência
- Website Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas comerciais da Apache Software Foundation (ASF).