Otimizar origens
Para todas as fontes, exceto o Banco de Dados SQL do Azure, é recomendável que você mantenha Usar particionamento atual como o valor selecionado. Quando você está lendo de todos os outros sistemas de origem, os fluxos de dados particionam automaticamente os dados uniformemente com base no tamanho dos dados. Uma nova partição é criada para cerca de cada 128 MB de dados. À medida que o tamanho dos dados aumenta, o número de partições aumenta.
Qualquer particionamento personalizado acontece depois que o Spark lê os dados e afeta negativamente o desempenho do fluxo de dados. Como os dados são particionados uniformemente na leitura, não é recomendado, a menos que você entenda a forma e a cardinalidade dos dados primeiro.
Nota
As velocidades de leitura podem ser limitadas pela taxa de transferência do seu sistema de origem.
Origens do Banco de Dados SQL do Azure
O Banco de Dados SQL do Azure tem uma opção de particionamento exclusiva chamada particionamento 'Origem'. Habilitar o particionamento de origem pode melhorar seus tempos de leitura do Banco de Dados SQL do Azure habilitando conexões paralelas no sistema de origem. Especifique o número de partições e como particionar seus dados. Use uma coluna de partição com alta cardinalidade. Você também pode inserir uma consulta que corresponda ao esquema de particionamento da tabela de origem.
Gorjeta
Para o particionamento de origem, a E/S do SQL Server é o gargalo. Adicionar muitas partições pode saturar seu banco de dados de origem. Geralmente quatro ou cinco partições é ideal ao usar esta opção.
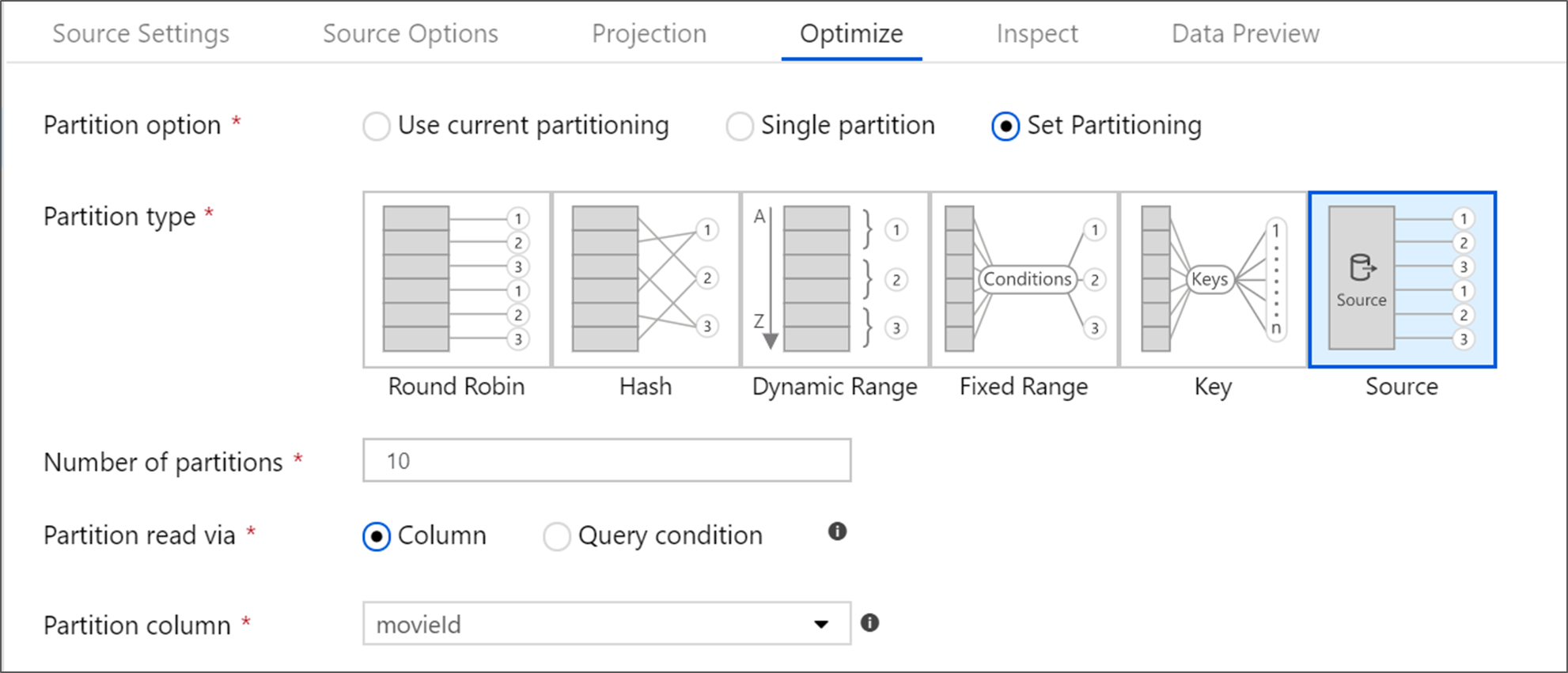
Nível de isolamento
O nível de isolamento da leitura em um sistema de origem SQL do Azure afeta o desempenho. Escolher 'Ler não confirmado' fornece o desempenho mais rápido e evita bloqueios de banco de dados. Para saber mais sobre os níveis de isolamento do SQL, consulte Noções básicas sobre os níveis de isolamento.
Ler usando consulta
Você pode ler do Banco de Dados SQL do Azure usando uma tabela ou uma consulta SQL. Se você estiver executando uma consulta SQL, a consulta deverá ser concluída antes que a transformação possa ser iniciada. As Consultas SQL podem ser úteis para reduzir operações que podem ser executadas mais rapidamente e reduzir a quantidade de dados lidos de um SQL Server, como instruções SELECT, WHERE e JOIN. Ao reduzir as operações, você perde a capacidade de rastrear a linhagem e o desempenho das transformações antes que os dados entrem no fluxo de dados.
Fontes do Azure Synapse Analytics
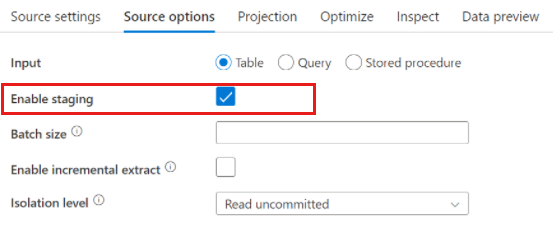
Ao usar o Azure Synapse Analytics, existe uma configuração chamada Habilitar preparo nas opções de origem. Isso permite que o serviço leia do Synapse usando Stagingo , o que melhora muito o desempenho de leitura usando o recurso de carregamento em massa mais eficiente, como CETAS e o comando COPY. A habilitação Staging exige que você especifique um local de preparo do Azure Blob Storage ou do Azure Data Lake Storage gen2 nas configurações de atividade de fluxo de dados.
Fontes baseadas em arquivos
Parquet vs. texto delimitado
Embora os fluxos de dados suportem vários tipos de arquivos, o formato Parquet nativo do Spark é recomendado para tempos ideais de leitura e gravação.
Se você estiver executando o mesmo fluxo de dados em um conjunto de arquivos, recomendamos ler a partir de uma pasta, usando caminhos curinga ou lendo a partir de uma lista de arquivos. Uma única atividade de fluxo de dados executada pode processar todos os seus arquivos em lote. Mais informações sobre como definir essas configurações podem ser encontradas na seção Transformação de origem da documentação do conector do Armazenamento de Blobs do Azure.
Se possível, evite usar a atividade For-Each para executar fluxos de dados em um conjunto de arquivos. Isso faz com que cada iteração do for-each gire seu próprio cluster Spark, o que muitas vezes não é necessário e pode ser caro.
Conjuntos de dados embutidos vs. conjuntos de dados compartilhados
Os conjuntos de dados ADF e Synapse são recursos compartilhados em suas fábricas e espaços de trabalho. No entanto, quando você está lendo um grande número de pastas de origem e arquivos com texto delimitado e fontes JSON, você pode melhorar o desempenho da descoberta de arquivos de fluxo de dados definindo a opção "Esquema projetado pelo usuário" dentro da Projeção | Caixa de diálogo de opções de esquema. Essa opção desativa a descoberta automática de esquema padrão do ADF e melhora consideravelmente o desempenho da descoberta de arquivos. Antes de definir essa opção, certifique-se de importar a projeção para que o ADF tenha um esquema existente para projeção. Esta opção não funciona com desvio de esquema.
Conteúdos relacionados
- Visão geral do desempenho do fluxo de dados
- Otimizar os sinks
- Otimizar as transformações
- Usando fluxos de dados em pipelines
Veja outros artigos do Data Flow relacionados ao desempenho: