Compreender os comprimentos de caminho nos Arquivos NetApp do Azure
O comprimento do arquivo e do caminho refere-se ao número de caracteres Unicode em um caminho de arquivo, incluindo diretórios. Esse limite é um fator nos comprimentos de caracteres individuais, que são determinados pelo tamanho do caractere em bytes. Por exemplo, NFS e SMB permitem componentes de caminho de 255 bytes. O formato de codificação de arquivo do American Standard Code for Information Interchange (ASCII) usa codificação de 8 bits, o que significa que os componentes de caminho de arquivo (como um nome de arquivo ou pasta) em ASCII podem ter até 255 caracteres, já que os caracteres ASCII têm 1 byte de tamanho.
A tabela a seguir mostra os comprimentos de componente e caminho suportados nos volumes do Azure NetApp Files:
| Componente | NFS | SMB |
|---|---|---|
| Tamanho do componente de caminho | 255 bytes | 255 bytes |
| Tamanho do comprimento do caminho | Ilimitado | Padrão: 255 bytes Máximo em versões posteriores do Windows: 32.767 bytes |
| Tamanho máximo do caminho para transversais | 4.096 bytes | 255 bytes |
Nota
Os volumes de protocolo duplo usam o menor valor máximo.
Se um nome de compartilhamento SMB for \\SMB-SHARE, o nome do compartilhamento adicionará 11 caracteres Unicode ao comprimento do caminho porque cada caractere tem 1 byte. Se o caminho para um arquivo específico for \\SMB-SHARE\apps\archive\file, são 29 caracteres Unicode, cada caractere, incluindo as barras, é de 1 byte. Para montagens NFS, aplicam-se os mesmos conceitos. O caminho /AzureNetAppFiles de montagem é de 17 caracteres Unicode de 1 byte cada.
Os Arquivos NetApp do Azure dão suporte ao mesmo comprimento de caminho para compartilhamentos SMB que os servidores Windows modernos suportam: até 32.767 bytes. No entanto, dependendo da versão do cliente Windows, alguns aplicativos não podem suportar caminhos com mais de 260 bytes. Os componentes de caminho individuais (os valores entre barras, como nomes de arquivos ou pastas) suportam até 255 bytes. Por exemplo, um nome de arquivo usando a maiúscula latina "A" (que ocupa 1 byte por caractere) em um caminho de arquivo nos Arquivos NetApp do Azure não pode exceder 255 caracteres.
# mkdir 256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
mkdir: cannot create directory ‘256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa’: File name too long
# mkdir 255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# ls | grep 255
255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
Tamanhos de caracteres exigentes
O utilitário uniutils Linux pode ser usado para encontrar o tamanho de byte de caracteres Unicode digitando várias instâncias da ocorrência de caractere e visualizando o campo bytes .
Exemplo 1: A maiúscula latina A aumenta em 1 byte cada vez que é usada (usando um único valor hexadecimal de 41, que está no intervalo de 0-255 caracteres ASCII).
# printf %b 'AAA' | uniname
character byte UTF-32 encoded as glyph name
0 0 000041 41 A LATIN CAPITAL LETTER A
1 1 000041 41 A LATIN CAPITAL LETTER A
2 2 000041 41 A LATIN CAPITAL LETTER A
Resultado 1: O nome AAA usa 3 bytes de 255.
Exemplo 2: O caractere japonês 字 incrementa 3 bytes em cada instância. Isto também pode ser calculado pelos 3 valores de código hexadecimal separados (E5, AD, 97) sob o campo codificado como . Cada valor hexadecimal representa 1 byte:
# printf %b '字字字' | uniname
character byte UTF-32 encoded as glyph name
0 0 005B57 E5 AD 97 字 CJK character Nelson 1281
1 3 005B57 E5 AD 97 字 CJK character Nelson 1281
2 6 005B57 E5 AD 97 字 CJK character Nelson 1281
Resultado 2: Um arquivo chamado 字字字 usa 9 bytes de 255.
Exemplo 3: A letra Ä com diaerese usa 2 bytes por instância (C3 + 84).
# printf %b 'ÄÄÄ' | uniname
character byte UTF-32 encoded as glyph name
0 0 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
1 2 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
2 4 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
Resultado 3: Um ficheiro denominado ÄÄÄ utiliza 6 bytes de um total de 255.
Exemplo 4: Um caractere especial, como o 😃 emoji, cai em um intervalo indefinido que excede os 0-3 bytes usados para caracteres Unicode. Como resultado, ele usa um par substituto para sua codificação de caracteres. Nesse caso, cada instância do caractere usa 4 bytes.
# printf %b '😃😃😃' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F603 F0 9F 98 83 😃 Character in undefined range
1 4 01F603 F0 9F 98 83 😃 Character in undefined range
2 8 01F603 F0 9F 98 83 😃 Character in undefined range
Resultado 4: Um arquivo chamado 😃😃😃 usa 12 bytes de 255.
A maioria dos emojis cai na faixa de 4 bytes, mas pode ir até 7 bytes. Dos mais de mil emojis padrão, aproximadamente 180 estão no Plano Multilíngüe Básico (BMP), o que significa que podem ser exibidos como texto ou emoji nos Arquivos NetApp do Azure, dependendo do suporte do cliente para o tipo de idioma.
Para obter informações mais detalhadas sobre o BMP e outros planos Unicode, consulte Compreender linguagens de volume em arquivos NetApp do Azure.
Impacto do byte de caracteres no comprimento do caminho
Embora um comprimento de caminho seja pensado para ser o número de caracteres em um nome de arquivo ou pasta, na verdade é o tamanho dos bytes suportados no caminho. Como cada caractere adiciona um tamanho de byte a um nome, diferentes conjuntos de caracteres em diferentes idiomas suportam diferentes comprimentos de nome de arquivo.
Considere os seguintes cenários:
Um arquivo ou pasta repete o caractere do alfabeto latino "A" para seu nome de arquivo. (por exemplo, AAAAAAAA)
Como "A" usa 1 byte e 255 bytes é o limite de tamanho do componente de caminho, então 255 instâncias de "A" seriam permitidas em um nome de arquivo.
Um arquivo ou pasta repete o caractere japonês 字 em seu nome.
Como "字" tem um tamanho de 3 bytes, o limite de comprimento do nome do arquivo seria de 85 instâncias de 字 (3 bytes * 85 = 255 bytes), ou um total de 85 caracteres.
Um arquivo ou pasta repete o emoji de rosto sorridente (😃) em seu nome.
Um emoji de rosto sorridente (😃) usa 4 bytes, o que significa que um nome de arquivo com apenas esse emoji permitiria um total de 64 caracteres (255 bytes/4 bytes).
- Um arquivo ou pasta usa uma combinação de caracteres diferentes (ou seja, Name字😃).
Quando caracteres diferentes com tamanhos de bytes diferentes são usados em um nome de arquivo ou pasta, o tamanho de byte de cada caractere leva em conta o comprimento do arquivo ou pasta. Um nome de arquivo ou pasta de Name字😃 usaria 1+1+1+1+3+4 bytes (11 bytes) do comprimento total de 255 bytes.
Conceitos especiais de emojis
Emojis especiais, como um emoji de bandeira, existem sob a classificação BMP: o emoji é renderizado como texto ou imagem, dependendo do suporte ao cliente. Quando um cliente não suporta a designação da imagem, ele usa designações regionais baseadas em texto.
Por exemplo, a bandeira dos Estados Unidos usa os caracteres "us" (que se assemelham aos caracteres latinos U+S, mas na verdade são caracteres especiais que usam codificações diferentes). Uniname mostra as diferenças entre os caracteres.
# printf %b 'US' | uniname
character byte UTF-32 encoded as glyph name
0 0 000055 55 U LATIN CAPITAL LETTER U
1 1 000053 53 S LATIN CAPITAL LETTER S
# printf %b '🇺🇸' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F1FA F0 9F 87 BA 🇺 Character in undefined range
1 4 01F1F8 F0 9F 87 B8 🇸 Character in undefined range
Os caracteres designados para os emojis de sinalizador são traduzidos em imagens de sinalizador em sistemas suportados, mas permanecem como valores de texto em sistemas não suportados. Esses caracteres usam 4 bytes por caractere para um total de 8 bytes quando um emoji de sinalizador é usado. Como tal, um total de 31 emojis de bandeira são permitidos em um nome de arquivo (255 bytes/8 bytes).
Limites de caminho SMB
Por padrão, os servidores e clientes Windows oferecem suporte a comprimentos de caminho de até 260 bytes, mas os comprimentos reais do caminho do arquivo são menores devido aos metadados adicionados aos caminhos do Windows, como o valor e as informações de <NUL> domínio.
Quando um limite de caminho é excedido no Windows, uma caixa de diálogo aparece:
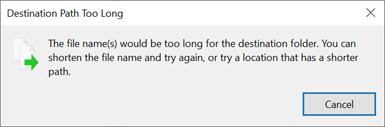
Os comprimentos de caminho SMB podem ser estendidos ao usar o Windows 10/Windows Server 2016 versão 1607 ou posterior, alterando um valor do Registro conforme abordado em Limitação de comprimento máximo de caminho. Quando esse valor é alterado, os comprimentos de caminho podem se estender até 32.767 bytes (menos valores de metadados).
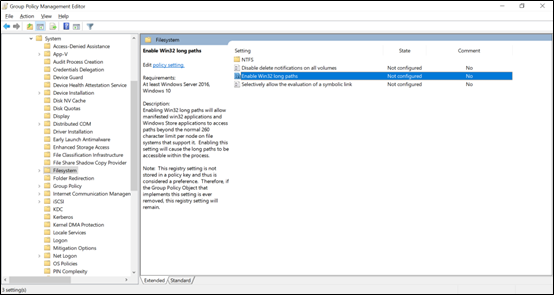
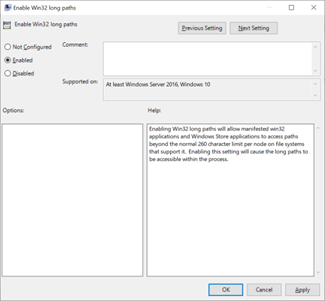
Depois que esse recurso estiver habilitado, você deve acessar as necessidades de compartilhamento SMB usando \\?\ no caminho para permitir comprimentos de caminho mais longos. Esse método não oferece suporte a caminhos UNC, portanto, o compartilhamento SMB precisa ser mapeado para uma letra de unidade.
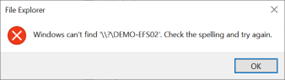
Em vez disso, o uso \\?\Z: permite o acesso e suporta caminhos de arquivo mais longos.

Nota
Atualmente, o CMD do Windows não suporta o uso do \\?\.
Solução alternativa se o comprimento máximo do caminho não puder ser aumentado
Se o comprimento máximo do caminho não puder ser habilitado no ambiente Windows ou se as versões do cliente Windows forem muito baixas, há uma solução alternativa. Você pode montar o compartilhamento SMB mais profundamente na estrutura de diretórios e reduzir o comprimento do caminho consultado.
Por exemplo, em vez de mapear \\NAS-SHARE\AzureNetAppFiles para Z:, mapeie \\NAS-SHARE\AzureNetAppFiles\folder1\folder2\folder3\folder4 para Z:.
Limites de caminho NFS
Os limites de caminho NFS com os volumes do Azure NetApp Files têm o mesmo limite de 255 bytes para componentes de caminho individuais. Cada componente, no entanto, é avaliado um de cada vez e pode processar até 4.096 bytes por solicitação com um comprimento total de caminho quase ilimitado. Por exemplo, se cada componente de caminho tiver 255 bytes, um cliente NFS poderá avaliar até 15 componentes por solicitação (incluindo / caracteres). Como tal, uma cd solicitação para um caminho acima do limite de 4.096 bytes produz uma mensagem de erro "Nome do arquivo muito longo".
Na maioria dos casos, os caracteres Unicode são de 1 byte ou menos, portanto, o limite de 4.096 bytes corresponde a 4.096 caracteres. Se um caractere tiver mais de 1 byte, o comprimento do caminho será menor que 4.096 caracteres. Os caracteres com um tamanho maior que 1 byte contam mais em relação à contagem total de caracteres do que caracteres de 1 byte.
O comprimento máximo do caminho pode ser consultado usando o getconf PATH_MAX /NFSmountpoint comando.
Nota
O limite é definido no limits.h arquivo no cliente NFS. Você não deve ajustar esses limites.
Considerações sobre volume de protocolo duplo
Ao usar os Arquivos NetApp do Azure para acesso de protocolo duplo, a diferença na forma como os comprimentos de caminho são manipulados nos protocolos NFS e SMB pode criar incompatibilidades entre arquivos e pastas. Por exemplo, o Windows SMB suporta até 32.767 caracteres em um caminho (desde que o recurso de caminho longo esteja habilitado no cliente SMB), mas o suporte a NFS pode exceder essa quantidade. Como tal, se um comprimento de caminho for criado no NFS que exceda o suporte do SMB, os clientes não poderão acessar os dados depois que os máximos de comprimento do caminho forem atingidos. Nesses casos, tenha o cuidado de considerar os limites finais inferiores dos comprimentos de caminho de arquivo entre protocolos ao criar nomes de arquivos e pastas (e profundidade do caminho da pasta) ou mapeie os compartilhamentos SMB mais próximos do caminho de pasta desejado para reduzir o comprimento do caminho.
Em vez de mapear o compartilhamento SMB para o nível superior do volume para navegar até um caminho de \\share\folder1\folder2\folder3\folder4, considere mapear o compartilhamento SMB para todo o caminho do \\share\folder1\folder2\folder3\folder4. Como resultado, um mapeamento de letra de unidade para Z: pousa na pasta desejada e reduz o comprimento do caminho de Z:\folder1\folder2\folder3\folder4\file para Z:\file.
Considerações sobre caracteres especiais
Os volumes de Arquivos NetApp do Azure usam um tipo de idioma C.UTF-8, que abrange muitos países/regiões e idiomas, incluindo alemão, cirílico, hebraico e a maioria dos chineses/japoneses/coreanos (CJK). Os caracteres de texto mais comuns em Unicode são de 3 bytes ou menos. Caracteres especiais - como emojis, símbolos musicais e símbolos matemáticos - geralmente são maiores do que 3 bytes. Alguns usam a lógica de par substituto UTF-16.
Se você usar um caractere que os Arquivos NetApp do Azure não suportam, poderá ver um aviso solicitando um nome de arquivo diferente.
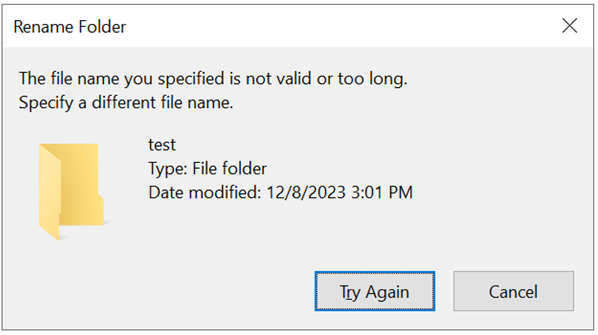
Em vez de o nome ser muito longo, o erro realmente resulta do tamanho do byte de caractere ser muito grande para o volume de Arquivos NetApp do Azure usar no SMB. Não há solução alternativa nos Arquivos NetApp do Azure para essa limitação. Para obter mais informações sobre a manipulação de caracteres especiais em Arquivos NetApp do Azure, consulte Comportamento de protocolo com conjuntos de caracteres especiais.