Alta disponibilidade e recuperação de desastres com o Azure Managed Redis (visualização)
Tal como acontece com todos os sistemas cloud, podem ocorrer interrupções não planeadas que podem levar à inatividade de uma instância de máquinas virtuais (VMs), uma Zona de Disponibilidade ou uma região completa do Azure. Recomendamos que os clientes tenham um plano para lidar com interrupções regionais ou de zona.
Este artigo apresenta as informações para os clientes criarem um plano de continuidade de negócios e recuperação de desastres para sua implementação do Azure Managed Redis (visualização).
Opções de alta disponibilidade:
| Opção | Description | Disponibilidade |
|---|---|---|
| Replicação padrão | Configuração replicada de nó duplo em um único data center com failover automático | 99,9% (ver detalhes) |
| Redundância de zona | Configuração replicada de vários nós em zonas de disponibilidade, com failover automático | 99,99% (ver detalhes) |
| Georreplicação | Instâncias de cache vinculadas em duas regiões, com failover controlado pelo usuário | Ativo (ver detalhes) |
| Importação/Exportação | Instantâneo point-in-time de dados em cache. | 99,9% (ver detalhes) |
| Persistência | Poupança periódica de dados na conta de armazenamento. | 99,9% (ver detalhes) |
Replicação padrão para alta disponibilidade
Recomendado para: Alta disponibilidade
O Azure Managed Redis tem uma arquitetura de alta disponibilidade que garante que sua instância gerenciada esteja funcionando, mesmo quando interrupções afetam as máquinas virtuais (VMs) subjacentes. Quer a interrupção seja planeada ou não planeada, o Azure Managed Redis proporciona taxas de disponibilidade percentuais superiores às que é possível obter através da alojação do Redis numa única VM. Uma instalação do Azure Managed Redis é executada em um par de servidores Redis por padrão. Os dois servidores são hospedados em VMs dedicadas.
Com o Azure Managed Redis, um servidor é o nó primário , enquanto o outro é a réplica. Depois de provisionar os nós do servidor, o Azure Managed Redis atribui funções primárias e de réplica a eles. O nó primário geralmente é responsável pelo atendimento de solicitações de gravação e leitura de clientes. Em uma operação de gravação, ele confirma uma nova chave e uma atualização de chave em sua memória interna e responde imediatamente ao cliente. Ele encaminha a operação para a réplica de forma assíncrona.
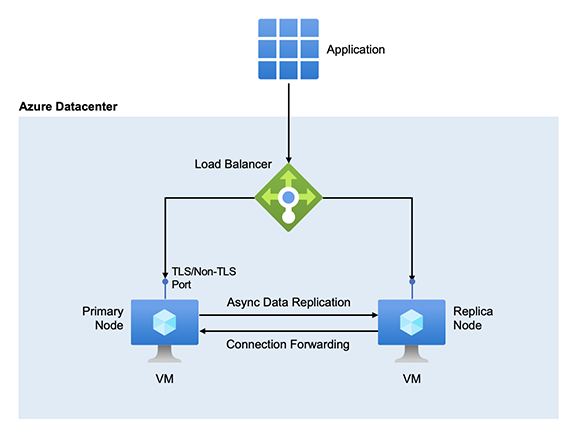
Se o nó primário em um cache não estiver disponível, a réplica se promoverá automaticamente para se tornar a nova principal. Esse processo é chamado de failover. Um failover é apenas dois nós, principal/réplica, funções de negociação, réplica/principal, com um dos nós possivelmente ficando offline por alguns minutos. Na maioria dos failovers, os nós primário e de réplica coordenam a entrega para que você tenha quase zero tempo sem um principal.
A antiga primária fica offline brevemente para receber atualizações da nova primária. Em seguida, a réplica agora volta a ficar online e volta ao cache totalmente sincronizada. A chave é que, quando um nó está indisponível, é uma condição temporária e volta a ficar online.
Uma sequência de failover típica tem esta aparência, quando um primário precisa ser desativado para manutenção:
- Os nós primários e de réplica negociam um failover coordenado e funções comerciais.
- A réplica (anteriormente primária) fica offline para uma reinicialização.
- Alguns segundos ou minutos depois, a réplica volta a ficar online.
- A réplica sincroniza os dados do primário.
Um nó primário pode sair de serviço como parte de uma atividade de manutenção planejada, como uma atualização do software Redis ou do sistema operacional. Ele também pode parar de funcionar devido a eventos não planejados, como falhas no hardware, software ou rede subjacentes. O failover e a aplicação de patches para o Azure Managed Redis fornecem uma explicação detalhada sobre os tipos de failovers. Um Redis Gerenciado do Azure passa por muitos failovers durante seu tempo de vida. O design da arquitetura de alta disponibilidade torna essas alterações dentro de um cache o mais transparentes possível para seus clientes.
Redundância entre zonas
Recomendado para: Alta disponibilidade, Recuperação de desastres - intrarregião
O Azure Managed Redis dá suporte à configuração redundante de zona por padrão. Um cache redundante de zona coloca automaticamente seus nós em diferentes Zonas de Disponibilidade do Azure na mesma região. Quando uma zona fica inativa, nós de cache em outras zonas estão disponíveis para manter o cache funcionando normalmente. Ele elimina a interrupção do data center ou da zona de disponibilidade como um único ponto de falha e aumenta a disponibilidade geral do cache.
Experiência Zone Down
Quando um nó de dados fica indisponível ou ocorre uma divisão de rede, ocorre um failover semelhante ao descrito na replicação padrão. O cluster usa um modelo baseado em quórum para determinar quais nós sobreviventes participam de um novo quórum. Ele também promove partições de réplica dentro desses nós para primárias, conforme necessário.
Disponibilidade regional
Os caches com redundância de zona estão disponíveis nas seguintes regiões:
| Américas | Europa | Médio Oriente | África | Ásia-Pacífico |
|---|---|---|---|---|
| Canadá Central* | Europa do Norte | Leste da Austrália | ||
| Centro dos EUA* | Sul do Reino Unido | Índia Central | ||
| E.U.A. Leste | Europa Ocidental | Sudeste Asiático | ||
| E.U.A. Leste 2 | Leste do Japão* | |||
| E.U.A. Centro-Sul | Ásia Leste | |||
| E.U.A. Oeste 2 | ||||
| EUA Oeste 3 | ||||
| Sul do Brasil |
Persistência
Recomendado para: Durabilidade dos dados
Como os dados do cache são armazenados na memória, uma falha rara e não planejada de vários nós pode fazer com que todos os dados sejam descartados. Para evitar a perda completa de dados, a persistência do Redis permite tirar instantâneos periódicos dos dados na memória e armazená-los em um disco gerenciado conectado diretamente à instância de cache. Em caso de perda de dados, os dados do cache são restaurados automaticamente usando o instantâneo no disco gerenciado. Para obter mais informações, consulte Configurar persistência de dados para uma instância do Azure Managed Redis.
Importação/Exportação
Recomendado para: Recuperação de desastres
O Azure Managed Redis dá suporte à opção de importar e exportar arquivos do Banco de Dados Redis (RDB) para fornecer portabilidade de dados. Ele permite que você importe dados para o Azure Managed Redis ou exporte dados do Azure Managed Redis usando um instantâneo RDB. O instantâneo RDB de um cache é exportado para um blob em uma Conta de Armazenamento do Azure. Você pode criar um script para acionar a exportação periodicamente para sua conta de armazenamento. Para obter mais informações, consulte Importar e exportar dados no Azure Managed Redis.
Conta de armazenamento para exportação
Considere escolher uma conta de armazenamento com redundância geográfica para garantir a alta disponibilidade dos dados exportados. Para obter mais informações, veja Redundância do Armazenamento do Microsoft Azure.
Georreplicação ativa
Recomendado para: Alta disponibilidade, recuperação de desastres - multi-região
A replicação geográfica é um mecanismo para vincular instâncias do Azure Managed Redis em várias regiões do Azure. O Azure Managed Redis dá suporte a uma forma avançada de replicação geográfica chamada replicação geográfica ativa que oferece maior disponibilidade e recuperação de desastres entre regiões em várias regiões. O software Azure Managed Redis usa tipos de dados replicados sem conflitos para dar suporte a gravações em várias instâncias de cache, mescla alterações e resolve conflitos. Você pode unir até cinco instâncias de cache em diferentes regiões do Azure para formar um grupo de replicação geográfica.
Um aplicativo que usa esse cache pode ler e gravar em qualquer uma das instâncias de cache distribuídas geograficamente por meio de seus pontos de extremidade correspondentes. O aplicativo deve usar o que é mais próximo de cada instância do aplicativo, oferecendo a menor latência. Para obter mais informações, consulte Configurar a replicação geográfica ativa para instâncias do Azure Managed Redis.
Se uma região de um dos caches no grupo de replicação ficar inativa, seu aplicativo precisará alternar para outra região disponível.
Quando um cache no grupo de replicação não estiver disponível, recomendamos monitorar o uso de memória para outros caches no mesmo grupo de replicação. Enquanto um dos caches está inativo, todos os outros caches no grupo de replicação começam a salvar metadados que não puderam compartilhar com o cache inativo. Se o uso de memória para os caches disponíveis começar a crescer a uma taxa alta depois que um dos caches ficar inativo, considere desvincular o cache que não está disponível do grupo de replicação.
Para obter mais informações sobre a desvinculação forçada, consulte Forçar-desvincular se houver interrupção de região.
Excluir e recriar cache
Se você enfrentar uma interrupção regional, considere recriar o cache em uma região diferente e atualizar seu aplicativo para se conectar ao novo cache. É importante entender que os dados são perdidos durante uma interrupção regional, a menos que você use a replicação geográfica ativa. O código do aplicativo deve ser resiliente à perda de dados.
Depois que a região afetada for restaurada, seu Redis Gerenciado do Azure indisponível será restaurado automaticamente e estará disponível para uso novamente. Para obter mais estratégias para mover seu cache para uma região diferente, consulte Mover instâncias Redis gerenciadas do Azure para regiões diferentes.