O modelo para sistemas distribuídos
Tradicionalmente, ter um sistema monolítico executado em vários computadores significava dividir o sistema em componentes separados de cliente e servidor. Nesses sistemas, o componente cliente lidava com a interface do usuário e o servidor forneceu processamento de back-end, como acesso ao banco de dados, impressão e assim por diante. À medida que os computadores proliferavam, caíam no custo e se conectavam por redes de largura de banda cada vez mais altas, a divisão de sistemas de software em vários componentes tornou-se mais conveniente, com cada componente em execução em um computador diferente e executando uma função especializada. Essa abordagem simplificava o desenvolvimento, o gerenciamento, a administração e, muitas vezes, melhorou o desempenho e a robustez, uma vez que a falha em um computador não necessariamente desabilitou todo o sistema.
Em muitos casos, o sistema aparece para o cliente como uma nuvem opaca que executa as operações necessárias, embora o sistema distribuído seja composto por nós individuais, conforme ilustrado na figura a seguir.
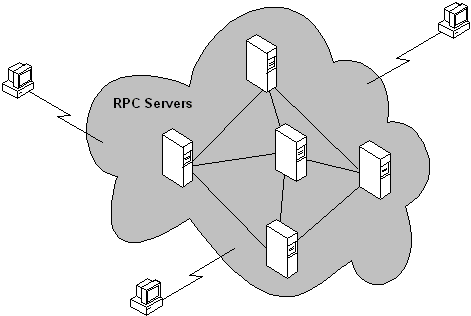
A opacidade da nuvem é mantida porque as operações de computação são invocadas em nome do cliente. Dessa forma, os clientes podem localizar um computador (um nó) na nuvem e solicitar uma determinada operação; ao executar a operação, esse computador pode invocar a funcionalidade em outros computadores na nuvem sem expor as etapas adicionais, ou o computador no qual eles foram executados, ao cliente.
Com esse paradigma, a mecânica de um sistema distribuído, semelhante à nuvem, pode ser dividida em muitas trocas de pacotes individuais ou conversas entre nós individuais.
Os sistemas cliente-servidor tradicionais têm dois nós com funções e responsabilidades fixas. Sistemas distribuídos modernos podem ter mais de dois nós e suas funções geralmente são dinâmicas. Em uma conversa, um nó pode ser um cliente, enquanto em outra conversa o nó pode ser o servidor. Em muitos casos, o consumidor final da funcionalidade exposta é um cliente com um usuário sentado em um teclado, observando a saída. Em outros casos, as funções do sistema distribuído são autônomas, executando operações em segundo plano.
O sistema distribuído pode não ter clientes e servidores dedicados para cada troca de pacotes específica, mas é importante lembrar que há um chamador (ou iniciador, que geralmente é chamado de cliente). Há também o destinatário da chamada (geralmente chamado de servidor). Não é necessário ter trocas de pacote bidirecional no formato solicitação-resposta de um sistema distribuído; geralmente, as mensagens são enviadas apenas de uma maneira.