WinMLRunner
O WinMLRunner é uma ferramenta para testar se um modelo é executado com sucesso quando avaliado com as APIs do Windows ML. Você também pode capturar o tempo de avaliação e o uso de memória na GPU e na CPU. Os modelos no formato .onnx ou .pb podem ser avaliados onde as variáveis de entrada e saída são tensores ou imagens. Há duas maneiras de usar o WinMLRunner:
- Baixar a ferramenta python de linha de comando.
- Usar no WinML Dashboard. Para obter mais informações, confira a documentação do WinML Dashboard
Executar um modelo
Abra a ferramenta Python que foi baixada. Navegue até a pasta que contém o WinMLRunner.exe e execute o executável, conforme mostrado abaixo. Certifique-se de substituir o local de instalação pelo seu:
.\WinMLRunner.exe -model SqueezeNet.onnx
Você também pode executar uma pasta de modelos, com um comando como o exibido a seguir.
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
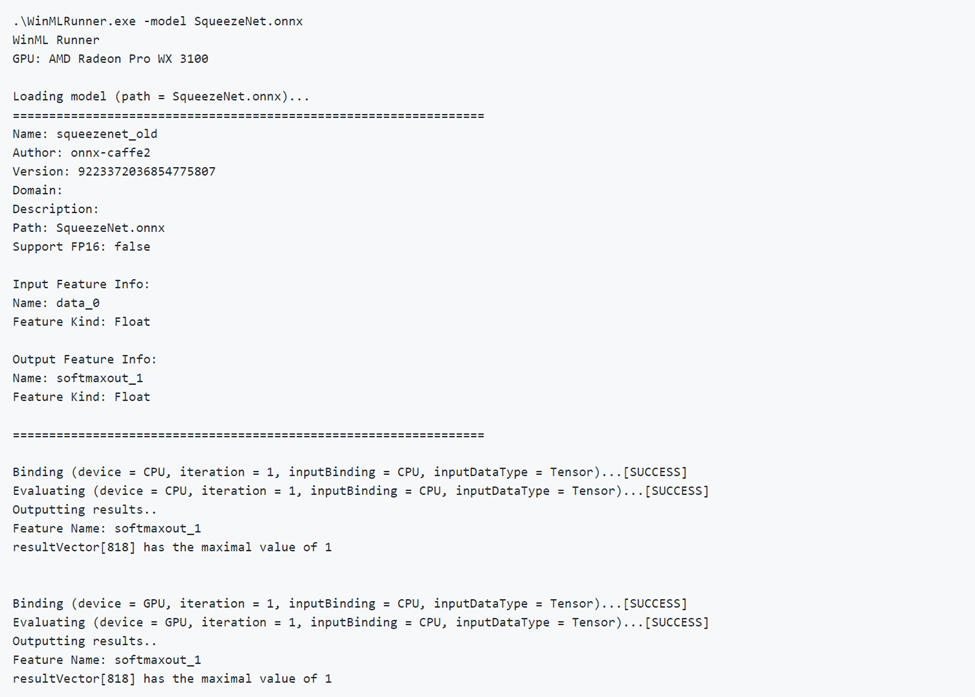
Executar um modelo com sucesso
Abaixo está um exemplo de execução bem-sucedida de modelo. Observe como primeiro o modelo carrega e dá saída os metadados. Em seguida, o modelo é executado na CPU e na GPU separadamente, o que faz com que a associação, a avaliação e a saída do modelo sejam bem-sucedidas.
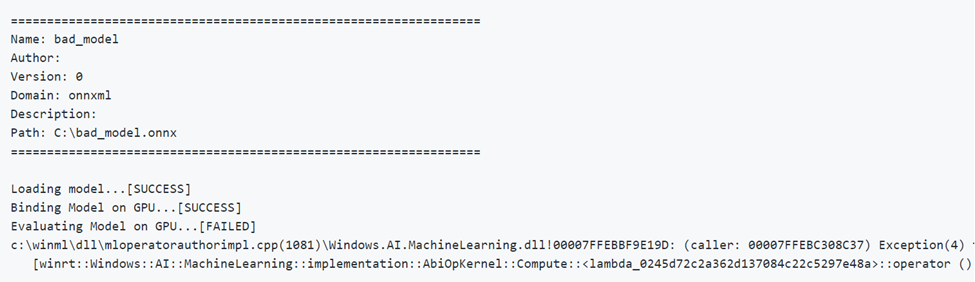
Executar um modelo sem sucesso
Veja abaixo um exemplo de execução de modelo com parâmetros incorretos. Observe a saída COM FALHA ao avaliar na GPU.
Seleção e otimização de dispositivo
Por padrão, o modelo é executado na CPU e na GPU separadamente, mas você pode especificar um dispositivo com um sinalizador -CPU ou -GPU. Este é um exemplo de execução de um modelo usando apenas a CPU por três vezes:
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
Dados de desempenho de Log
Use o sinalizador -perf para capturar os dados de desempenho. Este é um exemplo de execução de todos os modelos na pasta de dados na CPU e na GPU por três vezes separadamente e captura dos dados de desempenho:
WinMLRunner.exe -folder c:\data iterations 3 -perf
Medidas de desempenho
As seguintes medidas de desempenho serão as saídas para a linha de comando e o arquivo .csv de cada operação de carregamento, associação e avaliação:
- Hora do relógio (ms): o tempo real decorrido entre o início e o fim de uma operação.
- Tempo de GPU (ms): tempo para que uma operação passe da CPU para a GPU e seja executada na GPU (observação: o Load() não é executado na GPU).
- Tempo de CPU (ms): tempo para uma operação ser executada na CPU.
- Uso de memória dedicada e compartilhada (MB): uso médio de memória no nível do kernel e do usuário (em MB) durante a avaliação na CPU ou na GPU.
- Memória do conjunto de trabalho (MB): a quantidade de memória DRAM necessária durante a avaliação do processo na CPU. Memória dedicada (MB): a quantidade de memória que foi usada na VRAM da GPU dedicada.
- Memória compartilhada (MB): a quantidade de memória que foi usada na DRAM pela GPU.
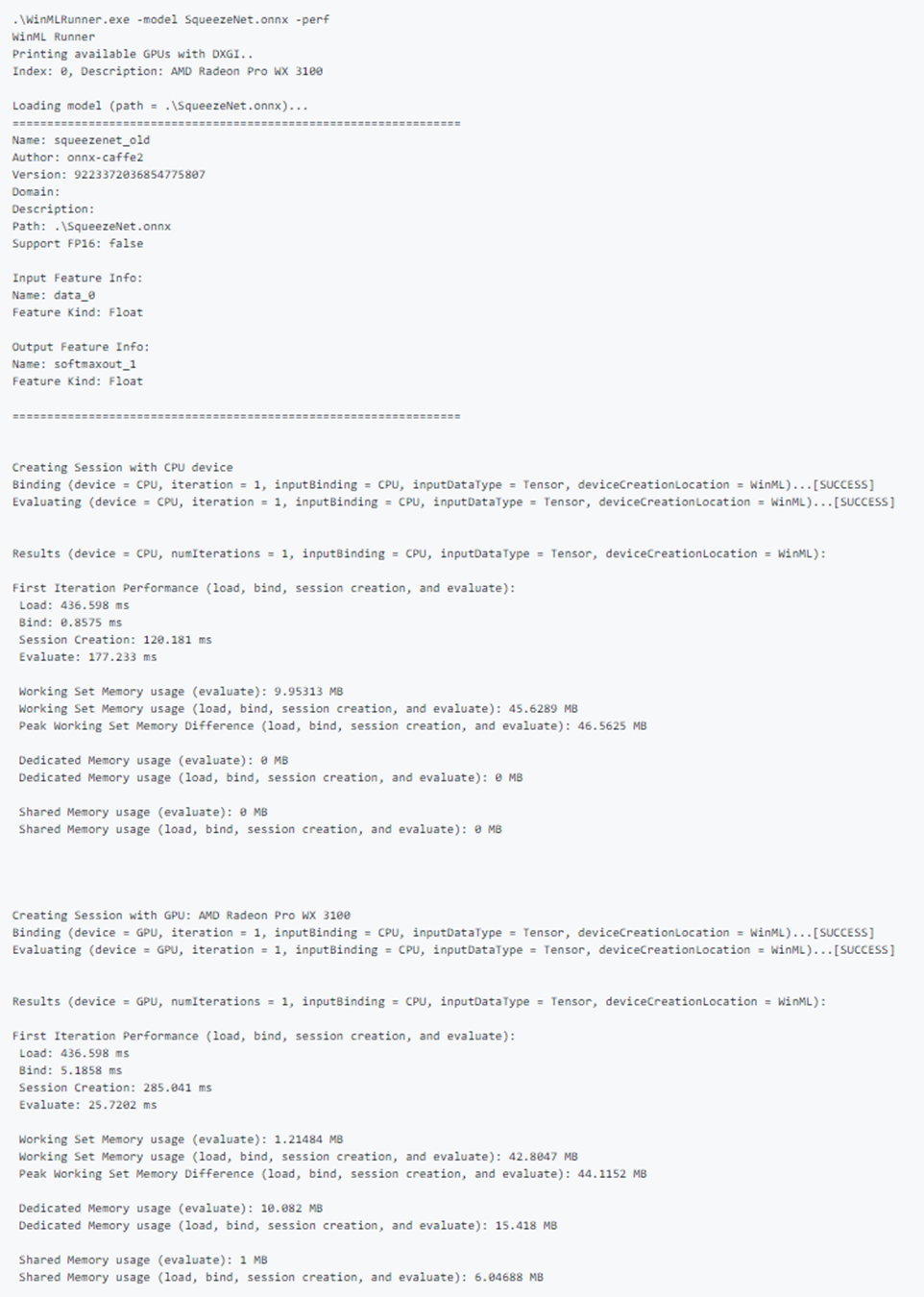
Exemplo de saída de desempenho:
Testar as entradas de exemplo
Execute um modelo na CPU e na GPU separadamente e associando a entrada à CPU e à GPU também em separado (total de 4 execuções):
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
Execute um modelo na CPU com a entrada associada à GPU e carregada como uma imagem RGB:
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
Capturar os logs de rastreamento
Para capturar os logs de rastreamento usando a ferramenta, use os comandos logman junto com o sinalizador de depuração:
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
O arquivo winmllog.etl vai aparecer no mesmo diretório que o WinMLRunner.exe.
Ler os logs de rastreamento
Usando o traceprt.exe, execute o comando a seguir da linha de comando.
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
Em seguida, abra o arquivo logdump.csv.
Como alternativa, você pode usar o Windows Performance Analyzer (do Visual Studio). Inicie o Windows Performance Analyzer e abra winmllog.etl.
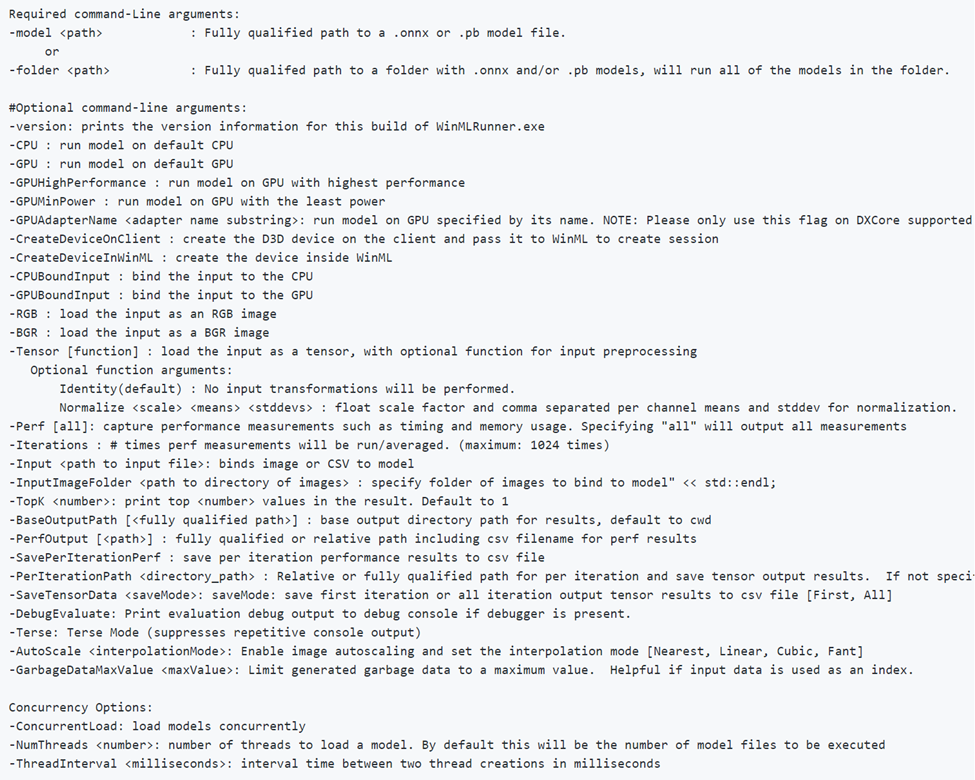
Observe que -CPU, -GPU, -GPUHighPerformance, -GPUMinPower -BGR, -RGB, -tensor, -CPUBoundInput, -GPUBoundInput não são mutuamente exclusivos (ou seja, você pode combinar quantos quiser para executar o modelo com configurações diferentes).
Carregamento dinâmico de DLL
Se você quiser executar o WinMLRunner com outra versão do WinML (por exemplo, comparando o desempenho com uma versão mais antiga ou testando uma versão mais recente), basta colocar os arquivos windows.ai.machinelearning.dll e directml.dll na mesma pasta que o WinMLRunner.exe. O WinMLRunner vai procurar as DLLs primeiro e vai retornar para C:/Windows/System32 se não as encontrar.
Problemas conhecidos
- Ainda não há suporte para entradas de sequência e de mapa (o modelo é apenas ignorado, portanto, ele não bloqueia os outros modelos na pasta);
- Não é possível executar vários modelos de maneira confiável com o argumento -folder com os dados reais. Como é possível especificar apenas 1 entrada, o tamanho da entrada seria incompatível com a maioria dos modelos. No momento, o argumento -folder só funciona bem com os dados de lixo;
- Atualmente, não há suporte para a geração de entrada de lixo como GRAY ou YUV. Idealmente, o pipeline de dados de lixo do WinMLRunner deve dar suporte a todos os tipos de entradas dadas ao winml.