Estrutura DML_MULTIHEAD_ATTENTION_OPERATOR_DESC (DirectML.h)
Executa uma operação de atenção multi-head (para obter mais informações, consulte Atenção é tudo de que você precisa). Exatamente um tensor de Query, Key e Value deve estar presente, estejam eles empilhados ou não. Por exemplo, se StackedQueryKey for fornecido, os tensores Query e Key deverão ser nulos, pois já são fornecidos em um layout empilhado. O mesmo vale para StackedKeyValue e StackedQueryKeyValue. Os tensores empilhados sempre têm cinco dimensões, e são sempre empilhados na quarta dimensão.
Logicamente, o algoritmo pode ser decomposto nas seguintes operações (operações entre colchetes são opcionais):
[Add Bias to query/key/value] -> GEMM(Query, Transposed(Key)) * Scale -> [Add RelativePositionBias] -> [Add Mask] -> Softmax -> GEMM(SoftmaxResult, Value);
Importante
Essa API está disponível como parte do pacote redistribuível autônomo DirectML (consulte Microsoft.AI.DirectML versão 1.12 e posterior. Confira também o histórico de versões do DirectML.
Sintaxe
struct DML_MULTIHEAD_ATTENTION_OPERATOR_DESC
{
_Maybenull_ const DML_TENSOR_DESC* QueryTensor;
_Maybenull_ const DML_TENSOR_DESC* KeyTensor;
_Maybenull_ const DML_TENSOR_DESC* ValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* BiasTensor;
_Maybenull_ const DML_TENSOR_DESC* MaskTensor;
_Maybenull_ const DML_TENSOR_DESC* RelativePositionBiasTensor;
_Maybenull_ const DML_TENSOR_DESC* PastKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* PastValueTensor;
const DML_TENSOR_DESC* OutputTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentValueTensor;
FLOAT Scale;
FLOAT MaskFilterValue;
UINT HeadCount;
DML_MULTIHEAD_ATTENTION_MASK_TYPE MaskType;
};
Membros
QueryTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Consulta com forma [batchSize, sequenceLength, hiddenSize], em que hiddenSize = headCount * headSize. Esse tensor é mutuamente exclusivo com StackedQueryKeyTensor e StackedQueryKeyValueTensor. O tensor também pode ter 4 ou 5 dimensões, desde que as dimensões principais sejam 1s.
KeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Chave com forma [batchSize, keyValueSequenceLength, hiddenSize], em que hiddenSize = headCount * headSize. Esse tensor é mutuamente exclusivo com StackedQueryKeyTensor, StackedKeyValueTensor e StackedQueryKeyValueTensor. O tensor também pode ter 4 ou 5 dimensões, desde que as dimensões principais sejam 1s.
ValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Valor com forma [batchSize, keyValueSequenceLength, valueHiddenSize], em que valueHiddenSize = headCount * valueHeadSize. Esse tensor é mutuamente exclusivo com StackedKeyValueTensor e StackedQueryKeyValueTensor. O tensor também pode ter 4 ou 5 dimensões, desde que as dimensões principais sejam 1s.
StackedQueryKeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
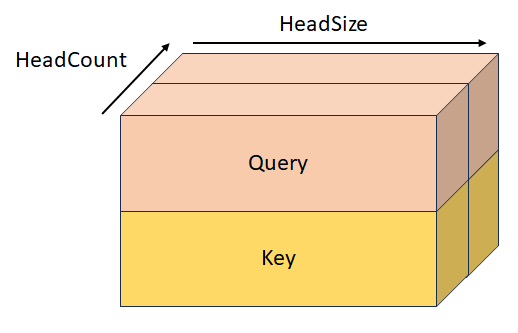
Consulta empilhada e chave com forma [batchSize, sequenceLength, headCount, 2, headSize]. Esse tensor é mutuamente exclusivo com QueryTensor, KeyTensor, StackedKeyValueTensor e StackedQueryKeyValueTensor.
StackedKeyValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
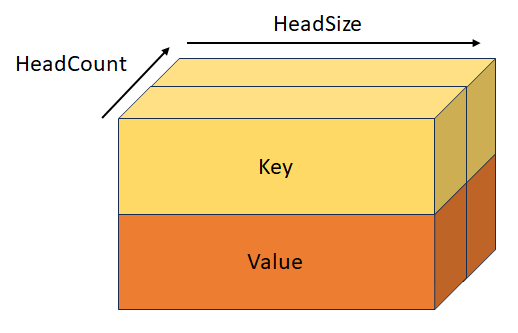
Chave e valor empilhados com forma [batchSize, keyValueSequenceLength, headCount, 2, headSize]. Esse tensor é mutuamente exclusivo com KeyTensor, ValueTensor, StackedQueryKeyTensor e StackedQueryKeyValueTensor.
StackedQueryKeyValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
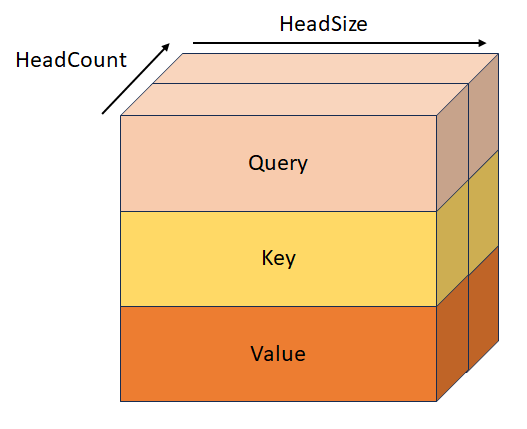
Consulta, chave e valor empilhados com forma [batchSize, sequenceLength, headCount, 3, headSize]. Esse tensor é mutuamente exclusivo com QueryTensor, KeyTensor, ValueTensor, StackedQueryKeyTensor e StackedKeyValueTensor.
BiasTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Esse é o desvio, de forma [hiddenSize + hiddenSize + valueHiddenSize], que é adicionado a Query/Key/Value antes da primeira operação GEMM. Este tensor também pode ter 2, 3, 4 ou 5 dimensões, desde que as dimensões principais sejam 1s.
MaskTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Essa é a máscara que determina quais elementos têm seu valor definido como MaskFilterValue após a operação QxK GEMM. O comportamento dessa máscara depende do valor de MaskType e é aplicado após RelativePositionBiasTensor, ou após a primeira operação GEMM se RelativePositionBiasTensor for null. Consulte a definição de MaskType para obter mais informações.
RelativePositionBiasTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Este é o desvio que se soma ao resultado da primeira operação do GEMM.
PastKeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Tensor de tecla da iteração anterior com forma [batchSize, headCount, pastSequenceLength, headSize]. Quando esse tensor não é nulo, ele é concatenado com o tensor chave, o que resulta em um tensor de forma [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize].
PastValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Tensor de valor da iteração anterior com forma [batchSize, headCount, pastSequenceLength, headSize]. Quando esse tensor não é nulo, ele é concatenado com ValueDesc que resulta em um tensor de forma [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize].
OutputTensor
Tipo: const DML_TENSOR_DESC*
Saída, de forma [batchSize, sequenceLength, valueHiddenSize].
OutputPresentKeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Estado presente para chave de atenção cruzada, com forma [batchSize, headCount, keyValueSequenceLength, headSize] ou estado presente para autoatenção com forma [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Ele tem o conteúdo do tensor chave ou o conteúdo do tensor PastKey + Key concatenado para passar para a próxima iteração.
OutputPresentValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Estado presente para valor de atenção cruzada, com forma [batchSize, headCount, keyValueSequenceLength, headSize] ou estado presente para autoatenção com forma [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Ele contém o conteúdo do tensor de valor ou o conteúdo do tensor PastValue + Value concatenado para passar para a próxima iteração.
Scale
Tipo: FLOAT
Dimensione para multiplicar o resultado da operação QxK GEMM, mas antes da operação Softmax. Normalmente, esse valor é 1/sqrt(headSize).
MaskFilterValue
Tipo: FLOAT
Valor que é adicionado ao resultado da operação QxK GEMM às posições que a máscara definiu como elementos de preenchimento. Esse valor deve ser um número negativo muito grande (geralmente -10000.0f).
HeadCount
Tipo: UINT
Número de heads de atenção.
MaskType
Tipo: DML_MULTIHEAD_ATTENTION_MASK_TYPE
Descreve o comportamento de MaskTensor.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_BOOLEAN. Quando a máscara contém um valor de 0, MaskFilterValue é adicionado, mas quando contém um valor de 1, nada é adicionado.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_LENGTH. A máscara, de forma [1, batchSize], contém os comprimentos de sequência da área não preenchida para cada lote, e todos os elementos após o comprimento da sequência têm seu valor definido como MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_END_START. A máscara, de forma [2, batchSize], contém os índices de fim (exclusivo) e início (inclusive) da área não preenchida, e todos os elementos fora da área têm seu valor definido como MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_QUERY_SEQUENCE_LENGTH_START_END. A máscara, de forma [batchSize * 3 + 2], tem os seguintes valores: [keyLength[0], ..., keyLength[batchSize - 1], queryStart[0], ..., queryStart[batchSize - 1], queryEnd[batchSize - 1], keyStart[0], ..., keyStart[batchSize - 1], keyEnd[batchSize - 1]].
Disponibilidade
Esse operador foi introduzido em DML_FEATURE_LEVEL_6_1.
Restrições de tensor
BiasTensor, KeyTensor, OutputPresentKeyTensor, OutputPresentValueTensor, OutputTensor, PastKeyTensor, PastValueTensor, QueryTensor, RelativePositionBiasTensor, StackedKeyValueTensor, StackedQueryKeyTensor, StackedQueryKeyValueTensor e ValueTensor devem ter o mesmo DataType.
Suporte a tensores
| Tensor | Tipo | Contagens de dimensões compatíveis | Tipos de dados com suporte |
|---|---|---|---|
| QueryTensor | Entrada opcional | 3 a 5 | FLOAT32, FLOAT16 |
| KeyTensor | Entrada opcional | 3 a 5 | FLOAT32, FLOAT16 |
| ValueTensor | Entrada opcional | 3 a 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyTensor | Entrada opcional | 5 | FLOAT32, FLOAT16 |
| StackedKeyValueTensor | Entrada opcional | 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyValueTensor | Entrada opcional | 5 | FLOAT32, FLOAT16 |
| BiasTensor | Entrada opcional | 1 a 5 | FLOAT32, FLOAT16 |
| MaskTensor | Entrada opcional | 1 a 5 | INT32 |
| RelativePositionBiasTensor | Entrada opcional | 4 a 5 | FLOAT32, FLOAT16 |
| PastKeyTensor | Entrada opcional | 4 a 5 | FLOAT32, FLOAT16 |
| PastValueTensor | Entrada opcional | 4 a 5 | FLOAT32, FLOAT16 |
| OutputTensor | Saída | 3 a 5 | FLOAT32, FLOAT16 |
| OutputPresentKeyTensor | Saída opcional | 4 a 5 | FLOAT32, FLOAT16 |
| OutputPresentValueTensor | Saída opcional | 4 a 5 | FLOAT32, FLOAT16 |
Requisitos
| Cabeçalho | directml.h |