Análise de CPU
Este guia fornece técnicas detalhadas que você pode usar para investigar problemas relacionados a Unidades Centrais de Processamento (CPU) que afetam as métricas de avaliação.
As seções de métricas ou problemas individuais nos guias de análise específicos da avaliação identificam problemas comuns para investigação. Este guia fornece técnicas e ferramentas que você pode usar para investigar esses problemas.
As técnicas neste guia usam o Windows Performance Analyzer (WPA) do Windows Performance Toolkit (WPT). O WPT faz parte do Windows ADK (Kit de Avaliação e Implantação do Windows) e pode ser baixado do Programa Windows Insider. Para obter mais informações, consulte Referência técnica do Windows Performance Toolkit.
Este guia está organizado nas três seções a seguir:
Esta seção descreve como os recursos da CPU são gerenciados no Windows 10. |
|
Esta seção explica como exibir e interpretar informações de CPU no Windows ADK Toolkit. |
|
Esta seção contém uma coleção de técnicas que você pode usar para investigar e resolver problemas comuns relacionados ao desempenho da CPU. |
Fundo
Esta seção contém descrições simples e uma discussão básica sobre o desempenho da CPU. Para um estudo mais abrangente sobre este tópico, recomendamos o livro Windows Internals, Fifth Edition.
Os computadores modernos podem conter várias CPUs instaladas em soquetes separados. Cada CPU pode hospedar vários núcleos de processador físico, cada um capaz de processar um ou dois fluxos de instruções separados simultaneamente. Esses processadores de fluxo de instruções individuais são gerenciados pelo sistema operacional Windows como processadores lógicos.
Neste guia, tanto o processador quanto a CPU referem-se a um processador lógico — ou seja, um dispositivo de hardware que o sistema operacional pode usar para executar instruções do programa.
O Windows 10 gerencia ativamente o hardware do processador de duas maneiras principais: gerenciamento de energia, para equilibrar o consumo de energia e o desempenho; e uso, para equilibrar os requisitos de processamento de programas e drivers.
Gerenciamento de energia do processador
Os processadores nem sempre existem em um estado operacional. Quando nenhuma instrução estiver pronta para ser executada, o Windows colocará um processador em um estado ocioso de destino (ou C-State), conforme determinado pelo Windows Power Manager. Com base nos padrões de uso da CPU, o estado C alvo de um processador será ajustado ao longo do tempo.
Os estados ociosos são estados numerados de C0 (ativo; não ocioso) até estados de energia progressivamente mais baixos. Esses estados incluem C1 (interrompido, mas o relógio ainda está habilitado), C2 (parado e o relógio desabilitado) e assim por diante. A implementação de estados ociosos é específica do processador. No entanto, um número de estado mais alto em todos os processadores reflete menor consumo de energia, mas também um tempo de espera mais longo antes que o processador possa retornar ao processamento de instruções. O tempo gasto em estados ociosos afeta significativamente o uso de energia e a vida útil da bateria.
Alguns processadores podem operar nos estados de desempenho (P-) e aceleração (T-) mesmo quando estão processando instruções ativamente. Os estados P definem as freqüências de clock e os níveis de tensão suportados pelo processador. Os estados T não alteram diretamente a frequência do clock, mas podem diminuir a velocidade efetiva do clock ignorando a atividade de processamento em alguma fração dos tiques do clock. Juntos, os estados P e T atuais determinam a frequência de operação efetiva do processador. Frequências mais baixas correspondem a menor desempenho e menor consumo de energia.
O Windows Power Manager determina um estado P e T apropriado para cada processador, com base nos padrões de uso da CPU e na política de energia do sistema. O tempo gasto em estados de alto desempenho versus estados de baixo desempenho afeta significativamente o uso de energia e a vida útil da bateria.
Gerenciamento de uso do processador
O Windows usa três abstrações principais para gerenciar o uso do processador.
Processos
Threads
Chamadas de procedimento adiado (DPCs) e rotinas de serviço de interrupção (ISRs)
Processos e threads
Todos os programas de modo de usuário no Windows são executados no contexto de um processo. Um processo inclui os seguintes atributos e componentes:
Um espaço de endereço virtual
Classe de prioridade
Módulos de programa carregados
Informações de ambiente e configuração
Pelo menos um fio
Embora os processos contenham os módulos do programa, o contexto e o ambiente, eles não são programados diretamente para serem executados em um processador. Em vez disso, os threads que pertencem a um processo são agendados para serem executados em um processador.
Um thread mantém informações de contexto de execução. Quase toda a computação é gerenciada como parte de um thread. A atividade da rosca afeta fundamentalmente as medições e o desempenho do sistema.
Como o número de processadores em um sistema é limitado, todos os threads não podem ser executados ao mesmo tempo. O Windows implementa o compartilhamento de tempo do processador, que permite que um thread seja executado por um período de tempo antes que o processador alterne para outro thread. O ato de alternar entre threads é chamado de alternância de contexto e é executado por um componente do Windows chamado dispatcher. O dispatcher toma decisões de agendamento de thread com base na prioridade, processador ideal e afinidade, quantum e estado.
Prioridade
A prioridade é um fator chave na forma como o dispatcher seleciona qual thread executar. A prioridade do thread é um número inteiro de 0 a 31. Se um thread for executável e tiver uma prioridade mais alta do que um thread em execução no momento, o thread de prioridade mais baixa será imediatamente preemptado e o thread de prioridade mais alta será comutado por contexto.
Quando um thread está em execução ou pronto para ser executado, nenhum thread de prioridade mais baixa pode ser executado, a menos que haja processadores suficientes para executar os dois threads ao mesmo tempo ou a menos que o thread de prioridade mais alta seja restrito a ser executado apenas em um subconjunto de processadores disponíveis. Os threads têm uma prioridade base que pode ser temporariamente elevada para prioridades mais altas em determinados momentos: por exemplo, quando o processo possui a janela em primeiro plano ou quando uma E/S é concluída.
Processador ideal e afinidade
O processador e a afinidade ideais de um thread determinam os processadores nos quais um determinado thread está agendado para ser executado. Cada thread tem um processador ideal que é definido pelo programa ou automaticamente pelo Windows. O Windows usa uma metodologia round-robin para que um número aproximadamente igual de threads em cada processo seja atribuído a cada processador. Quando possível, o Windows agenda um thread para ser executado em seu processador ideal; no entanto, o thread pode ocasionalmente ser executado em outros processadores.
A afinidade de processador de um thread restringe os processadores nos quais um thread será executado. Essa é uma restrição mais forte do que o atributo de processador ideal do thread. O programa define a afinidade usando SetThreadAffinityMask. A afinidade pode impedir que threads sejam executados em processadores específicos.
Quantum
As alternâncias de contexto são operações caras. O Windows geralmente permite que cada thread seja executado por um período de tempo chamado quantum antes de alternar para outro thread. A duração quântica é projetada para preservar a capacidade de resposta aparente do sistema. Ele maximiza a taxa de transferência minimizando a sobrecarga da alternância de contexto. As durações quânticas podem variar entre clientes e servidores. As durações quânticas geralmente são mais longas em um servidor para maximizar a taxa de transferência às custas da capacidade de resposta aparente. Em computadores cliente, o Windows atribui quantums mais curtos em geral, mas fornece um quantum mais longo ao thread associado à janela de primeiro plano atual.
Estado
Cada thread existe em um estado de execução específico a qualquer momento. O Windows usa três estados que são relevantes para o desempenho; são eles: Running, Ready e Waiting.
Os threads que estão sendo executados no momento estão no estado Running . Os threads que podem ser executados, mas não estão em execução no momento, estão no estado Pronto . Os threads que não podem ser executados porque estão aguardando um evento específico estão no estado Aguardando .
Uma transição de estado para estado é mostrada na Figura 1 Transições de estado de thread:
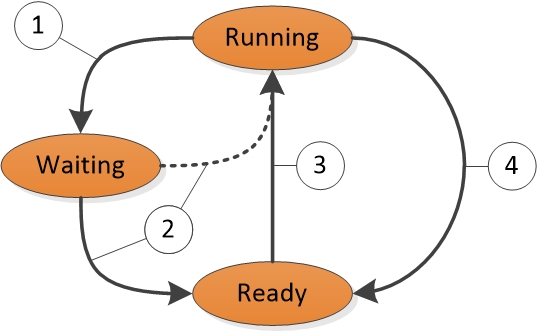
Figura 1 Transições de estado de thread
A Figura 1 Transições de estado de thread é explicada da seguinte maneira:
Um thread no estado Running inicia uma transição para o estado Waiting chamando uma função de espera, como WaitForSingleObject ou Sleep(> 0).
Uma operação de thread ou kernel em execução prepara um thread no estado Waiting (por exemplo, SetEvent ou expiração do temporizador). Se um processador estiver ocioso ou se o thread preparado tiver uma prioridade mais alta do que um thread em execução no momento, o thread preparado poderá alternar diretamente para o estado Running. Caso contrário, ele será colocado no estado Pronto.
Um thread no estado Pronto é agendado para processamento pelo dispatcher quando um thread em execução aguarda, produz (Sleep(0)) ou atinge o final de seu quantum.
Um thread no estado Running é comutado e colocado no estado Ready pelo dispatcher quando é preemptado por um thread de prioridade mais alta, produz (Sleep(0)) ou quando seu quantum termina.
Um thread que existe no estado Aguardando não indica necessariamente um problema de desempenho. A maioria dos threads passa um tempo significativo no estado Aguardando, o que permite que os processadores entrem em estados ociosos e economizem energia. O estado do thread se torna um fator importante no desempenho somente quando um usuário está aguardando a conclusão de uma operação de thread.
DPCs e ISRs
Além de processar threads, os processadores respondem a notificações de dispositivos de hardware, como placas de rede ou temporizadores. Quando um dispositivo de hardware requer atenção do processador, ele gera uma interrupção. O Windows responde a uma interrupção de hardware suspendendo um thread em execução no momento e executando o ISR associado à interrupção.
Durante o tempo em que está executando um ISR, um processador pode ser impedido de lidar com qualquer outra atividade, incluindo outras interrupções. Por esse motivo, os ISRs devem ser concluídos rapidamente ou o desempenho do sistema pode diminuir. Para diminuir o tempo de execução, os ISRs geralmente agendam DPCs para executar o trabalho que deve ser feito em resposta a uma interrupção. Para cada processador lógico, o Windows mantém uma fila de DPCs agendados. Os DPCs têm prioridade sobre threads em qualquer nível de prioridade. Antes que um processador retorne ao processamento de threads, ele executa todos os DPCs em sua fila.
Durante o tempo em que um processador está executando DPCs e ISRs, nenhum thread pode ser executado nesse processador. Essa propriedade pode levar a problemas para threads que devem executar o trabalho em uma determinada taxa de transferência ou com tempo preciso, como um thread que reproduz áudio ou vídeo. Se o tempo do processador usado para executar DPCs e ISRs impedir que esses threads recebam tempo de processamento suficiente, o thread poderá não atingir a taxa de transferência necessária ou concluir seus itens de trabalho a tempo.
Ferramentas do Windows ADK
O Windows ADK grava informações de hardware e avaliações em arquivos de resultados de avaliações. O WPA fornece informações detalhadas sobre o uso da CPU em vários gráficos. Esta seção explica como usar o Windows ADK e o WPA para coletar, exibir e analisar dados de desempenho da CPU.
Arquivos de resultados de avaliação do Windows ADK
Como o Windows dá suporte apenas a sistemas de multiprocessamento simétricos, todas as informações nesta seção se aplicam a todas as CPUs e núcleos instalados.
Informações detalhadas de hardware da CPU estão disponíveis na EcoSysInfo seção de arquivos de resultados de avaliação no <Processor><Instance id=”0”> nó.
Por exemplo:
<Processor>
<Instance id="0">
<ProcessorName>The name of the first CPU</ProcessorName>
<TSCFrequency>The maximum frequency of the first CPU</TSCFrequency>
<NumProcs>The total number of processors</NumProcs>
<NumCores>The total number of cores</NumCores>
<NumCPUs>The total number of logical processors</NumCPUs>
...and so on...
Gráficos WPA
Depois de carregar um rastreamento no WPA, você pode encontrar informações de hardware do processador nas seções Rastreamento/Configuração do sistema/Geral e Rastreamento/Configuração do sistema/PnP da interface do usuário do WPA.
Observação Todos os procedimentos neste guia ocorrem no WPA.
Gráfico de estados ociosos da CPU
Se as informações de estado ocioso forem coletadas em um rastreamento, o gráfico de estados ociosos de energia/CPU será exibido na interface do usuário do WPA. Esse gráfico sempre contém dados sobre o estado ocioso de destino para cada processador. O gráfico também conterá informações sobre o estado ocioso real de cada processador se esse estado for suportado pelo processador.
Cada linha na tabela a seguir descreve uma alteração de estado ocioso para o estado Destino ou Real de um processador. As seguintes colunas estão disponíveis para cada linha no gráfico:
| Coluna | Detalhes |
|---|---|
CPU |
O processador afetado pela alteração de estado. |
EntryTime |
A hora em que o processador entrou no estado ocioso. |
Hora de Saída |
A hora em que o processador saiu do estado ocioso. |
Max:Duração (ms) |
O tempo gasto no estado ocioso (agregação padrão:máximo). |
Min:Duração(ms) |
O tempo gasto no estado ocioso (agregação padrão:minimum). |
Próximo estado |
O estado para o qual o processador fez a transição após o estado atual. |
Estado anterior |
O estado do qual o processador fez a transição antes do estado atual. |
Estado |
O estado ocioso atual. |
Estado (Numérico) |
O estado ocioso atual como um número (por exemplo, 0 para C0). |
Soma:Duração(ms) |
O tempo gasto no estado ocioso (agregação padrão:sum). |
Tabela |
Não usado |
Tipo |
Destino (para o estado de destino selecionado pelo Power Manager para o processador) ou Real (para o estado ocioso real do processador). |
O perfil WPA padrão fornece duas predefinições para este gráfico: Estado por Tipo, CPU e Diagrama de Estado por Tipo, CPU.
Estado por tipo, CPU
Os estados Destino e Real de cada CPU são representados graficamente junto com o número do estado no eixo Y no gráfico Estado por Tipo, CPU . Figura 2 Estados ociosos da CPU Estado por tipo, a CPU mostra o estado real da CPU à medida que ela flutua entre os estados ociosos ativo e de destino.
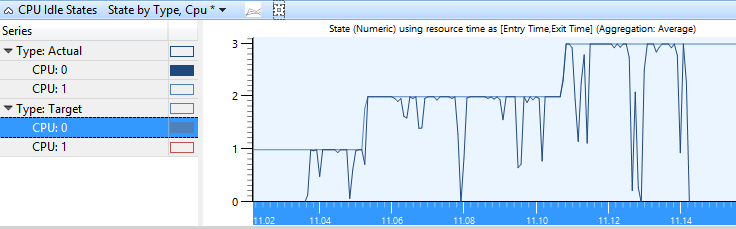
Figura 2 Estados ociosos da CPU Estado por tipo, CPU
Diagrama de estado por tipo, CPU
Neste gráfico, os estados Destino e Real de cada CPU são apresentados no formato de linha do tempo. Cada estado tem uma linha separada na linha do tempo. Figura 3 Diagrama de estado de estados ociosos da CPU por tipo, CPU mostra os mesmos dados que Figura 2 Estados ociosos da CPU Estado por tipo, CPU, em uma exibição de linha do tempo.
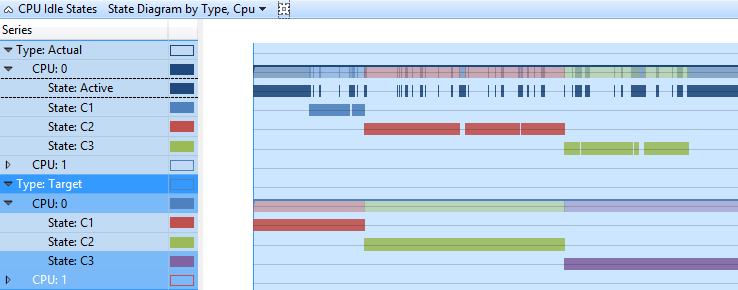
Figura 3 Diagrama de estado de estados ociosos da CPU por tipo, CPU
Gráfico de frequência da CPU
Se os dados de frequência da CPU foram coletados em um sistema que suporta vários estados P ou T, o gráfico de frequência da CPU estará disponível na interface do usuário do WPA. Cada linha na tabela a seguir representa o tempo em um nível de frequência específico para um processador. A coluna Freqüência (MHz) contém um número limitado de freqüências que correspondem aos estados P e T suportados pelo processador. As seguintes colunas estão disponíveis para cada linha no gráfico:
| Coluna | Detalhes |
|---|---|
% Duração |
A duração é expressa como uma porcentagem do tempo total de CPU durante o período de tempo visível no momento. |
Count |
O número de alterações de frequência (sempre 1 para linhas individuais). |
CPU |
A CPU afetada pela mudança de frequência. |
EntryTime |
A hora em que a CPU entrou no estado P. |
Hora de Saída |
A hora em que a CPU saiu do estado P. |
Frequência (MHz) |
A frequência da CPU durante o tempo em que ela está no estado P. |
Max:Duração (ms) |
O tempo gasto no estado P (agregação padrão:máximo). |
Min:Duração(ms) |
O tempo gasto no estado P (agregação padrão:mínimo). |
Soma:Duração(ms) |
O tempo gasto no estado P (agregação padrão:sum). |
Tabela |
Não usado |
Tipo |
Informações adicionais sobre o P-State. |
O perfil padrão define a predefinição Frequência por CPU para este gráfico. A Figura 4 Frequência da CPU por CPU mostra uma CPU à medida que ela faz a transição entre três estados P:

Figura 4 Frequência da CPU por CPU
Gráfico de uso da CPU (amostrado)
Os dados exibidos no gráfico Uso da CPU (Amostrado) representam amostras de atividade da CPU que são obtidas em um intervalo de amostragem regular. Na maioria dos traços, isso é um milissegundo (1ms). Cada linha na tabela representa uma única amostra.
O peso da amostra representa a significância dessa amostra, em relação a outras amostras. O peso é igual ao carimbo de data/hora da amostra atual menos o carimbo de data/hora da amostra anterior. O peso nem sempre é exatamente igual ao intervalo de amostragem devido a flutuações no estado e na atividade do sistema.
A Figura 5 Amostragem de CPU representa como os dados são coletados:
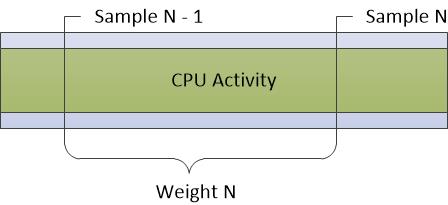
Figura 5 Amostragem de CPU
Qualquer atividade de CPU que ocorra entre amostras não é registrada por esse método de amostragem. Portanto, atividades de duração muito curta, como DPCs e ISRs, não estão bem representadas no gráfico de amostragem da CPU.
As seguintes colunas estão disponíveis para cada linha no gráfico:
| Coluna | Detalhes |
|---|---|
% Peso |
O peso é expresso como uma porcentagem do tempo total de CPU gasto no intervalo de tempo visível no momento. |
Address |
O endereço de memória da função que está na parte superior da pilha. |
Todos contam |
O número de amostras representadas por uma linha. Esse número inclui amostras que são obtidas quando um processador está ocioso. Para linhas individuais, essa coluna é sempre 1. |
Count |
O número de amostras representadas por uma linha, excluindo amostras que são obtidas quando um processador está ocioso. Para linhas individuais, essa coluna é sempre 1 (ou 0, para casos em que a CPU estava em um estado de baixa energia). |
CPU |
O índice baseado em 0 da CPU na qual este exemplo foi obtido. |
Nome para Exibição |
O nome de exibição do processo ativo. |
DPC/ISR |
Se o exemplo mediu o uso regular da CPU, um DPC/ISR ou um estado de baixo consumo de energia. |
Função |
A função na parte superior da pilha. |
Módulo |
O módulo que contém a função na parte superior da pilha. |
Prioridade |
A prioridade do thread em execução. |
Processo |
O nome da imagem do processo que possui o código em execução. |
Nome do Processo |
O nome completo (incluindo a ID do processo) do processo que possui o código em execução. |
Pilha |
A pilha do thread em execução. |
ID do thread |
A ID do thread em execução. |
Função de início de rosca |
A função com a qual o thread em execução foi iniciado. |
Módulo de início de thread |
O módulo que contém a Função de Início de Thread. |
TimeStamp |
A hora em que a amostra foi coletada. |
Weight |
O tempo (em milissegundos) representado pela amostra (ou seja, o tempo desde a última amostra). |
O perfil padrão fornece as seguintes predefinições para este gráfico:
Utilização por CPU
Utilização por prioridade
Utilização por processo
Utilização por processo e thread
Utilização por CPU
O gráfico Utilização de uso da CPU por CPU mostra como o trabalho é distribuído entre os processadores. A Figura 6 Utilização do uso da CPU por CPU mostra essa distribuição para duas CPUs:
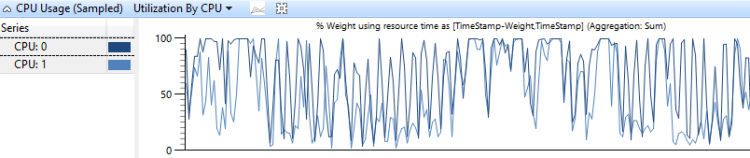
Figura 6 Utilização do uso da CPU pela CPU
Utilização por prioridade
Uso da CPU agrupado por prioridade de thread mostra como os threads de alta prioridade afetam os threads de prioridade mais baixa. A Figura 7 Utilização de uso da CPU (amostrada) por prioridade exibe este gráfico:
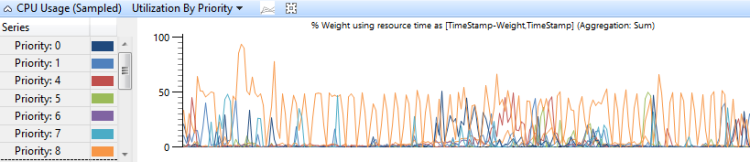
Figura 7 Utilização de uso da CPU (amostrada) por prioridade
Utilização por processo
O uso da CPU agrupado por processo mostra o uso relativo dos processos. A Figura 8 Utilização da CPU (amostrada) por processo mostra essa predefinição. Neste gráfico de exemplo, um processo é mostrado consumindo mais tempo de CPU do que os outros processos.
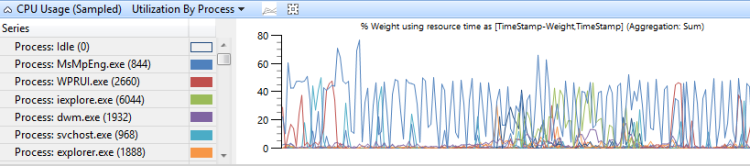
Figura 8 Utilização de uso da CPU (amostrada) por processo
Utilização por processo e thread
O uso da CPU agrupado por processo e, em seguida, agrupado por thread mostra o uso relativo de processos e threads em cada processo. A Figura 9 Utilização da CPU (amostrada) por processo e thread mostra essa predefinição. Os threads de um único processo são selecionados neste gráfico.
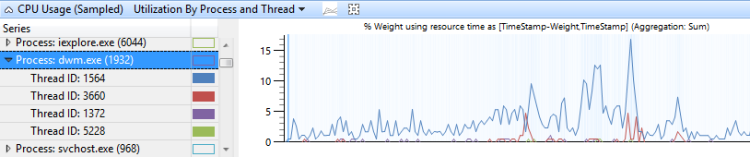
Figura 9 Utilização de uso da CPU (amostrada) por processo e thread
Gráfico de uso da CPU (preciso)
O gráfico Uso da CPU (Preciso) registra informações associadas a eventos de alternância de contexto. Cada linha representa um conjunto de dados associado a uma única alternância de contexto; ou seja, quando um thread começou a ser executado. Os dados são coletados para a seguinte sequência de eventos:
O novo thread é trocado.
O novo thread é feito pronto para ser executado pelo thread de preparação.
O novo thread é comutado, alternando assim um thread antigo.
O novo thread é trocado novamente.
Na Figura 10 Diagrama preciso de uso da CPU, o tempo flui da esquerda para a direita. Os rótulos do diagrama correspondem aos nomes das colunas no gráfico Uso da CPU (Preciso). Os rótulos das colunas de carimbo de data/hora são exibidos na parte superior do diagrama e os rótulos das colunas de duração do intervalo são exibidos na parte inferior do diagrama.
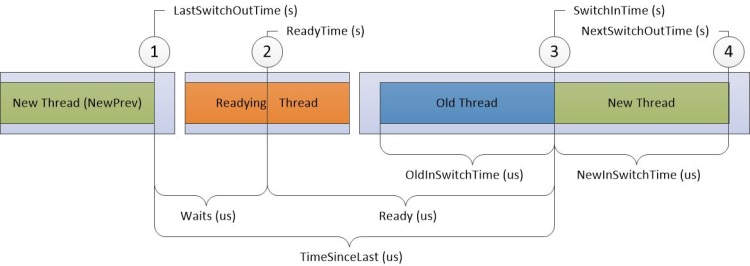
Figura 10 Diagrama preciso de uso da CPU
As quebras na linha do tempo na Figura 10 Diagrama preciso de uso da CPU dividem a linha do tempo em regiões que podem ocorrer simultaneamente em diferentes CPUs. Essas linhas do tempo podem se sobrepor, desde que a ordem dos eventos numerados não seja modificada. Por exemplo, o Readying Thread pode ser executado no Processor-2 ao mesmo tempo em que um novo thread é comutado e depois de volta no Processor-1).
As informações são registradas para os quatro destinos a seguir na linha do tempo:
Novo thread, que é o thread que foi trocado. É o foco principal desta linha no gráfico.
NewPrev, que se refere à vez anterior em que o novo thread foi alternado.
Threading de preparação, que é o thread que preparou o novo thread a ser processado.
Thread antigo, que é o thread que foi trocado quando o novo thread foi trocado.
Os dados na tabela a seguir estão relacionados a cada thread de destino:
| Coluna | Detalhes |
|---|---|
% de uso da CPU |
O uso da CPU do novo thread depois que ele é alternado. Esse valor é expresso como uma porcentagem do tempo total de CPU durante o período de tempo visível no momento. |
Count |
O número de alternâncias de contexto representadas pela linha. Isso é sempre 1 para linhas individuais. |
Contagem:Espera |
O número de esperas representadas pela linha. Isso é sempre 1 para linhas individuais, exceto quando um thread é alternado para um estado ocioso; Nesse caso, ele é definido como 0. |
CPU |
A CPU na qual ocorreu a alternância de contexto. |
Uso da CPU (ms) |
O uso da CPU do novo thread após a alternância de contexto. Isso é igual a NewInSwitchTime, mas é exibido em milissegundos. |
IdealCPU |
A CPU ideal selecionada pelo agendador para o novo thread. |
LastSwitchOutTime (s) |
A vez anterior em que o novo thread foi trocado. |
NewInPri |
A prioridade do novo thread que é comutado. |
Novo(s) |
NextSwitchOutTime(s) menos SwitchInTime(s) |
NewOutPri |
A prioridade do novo thread quando ele é alternado. |
NewPrevOutPri |
A prioridade do novo thread quando ele foi trocado anteriormente. |
NewPrevState |
O estado do novo thread depois que ele foi trocado anteriormente. |
NewPrevWaitMode |
O Modo de Espera do novo thread quando ele foi alternado anteriormente. |
NewPrevWaitReason |
O motivo pelo qual o novo thread foi trocado. |
NewPriDecr |
O aumento de prioridade que afeta o thread. |
NewProcess |
O processo do novo thread. |
Nome do NewProcess |
O nome do processo do novo thread, incluindo PID. |
Novo Qnt |
Não utilizado. |
Estado Novo |
O estado do novo thread depois que ele é comutado. |
NewThreadId |
A ID do thread do novo thread. |
NewThreadStack |
A pilha do novo thread quando ele é comutado. |
NewThreadStartFunction |
A função de início do novo thread. |
NewThreadStartModule |
O módulo inicial do novo thread. |
NovoModo de espera |
O modo de espera do novo thread. |
NewWaitReason |
O motivo pelo qual o novo thread foi trocado. |
PróximoSwitchOutTime(s) |
A hora em que o novo thread foi trocado em seguida. |
Antigo(s) |
A hora em que o thread antigo foi comutado antes de ser trocado. |
OldOutPri |
A prioridade do thread antigo quando ele foi trocado. |
Processo antigo |
O processo que possui o thread antigo. |
Nome do OldProcess |
O nome do processo que possui o thread antigo, incluindo PID. |
OldQnt |
Não utilizado. |
Estado antigo |
O estado do thread antigo depois que ele é trocado. |
OldThreadId |
A ID do thread antigo. |
Função OldThreadStartFunction |
A função de início do thread antigo. |
Módulo OldThreadStartModule |
O módulo de início do thread antigo. |
OldWaitMode |
O modo de espera do thread antigo. |
Razão de espera antiga |
A razão pela qual o tópico antigo foi trocado. |
AnteriorCState |
O CState anterior do processador. Se não for 0 (Ativo), o processador estava em um estado ocioso antes que o novo thread fosse comutado por contexto. |
Pronto(s) |
SwitchInTime(s) minusReadyTime (s) |
Preparando ThreadId |
A ID do thread de preparação. |
Preparando ThreadStartFunction |
A função de início da linha de preparação. |
Preparando ThreadStartModule |
O módulo inicial do thread de preparação. |
Processo de preparação |
O processo que possui o thread de preparação. |
Nome do ReadyingProcess |
O nome do processo que possui o thread de preparação, incluindo PID. |
ReadyThreadStack |
A pilha do thread de preparação. |
ReadyTime (s) |
A hora em que o novo thread foi preparado. |
SwitchInTime(s) |
A hora em que o novo thread foi trocado. |
TimeSinceLast (s) |
SwitchInTime(s) menos LastSwitchOutTime (s) |
Espera(s) |
ReadyTime (s) menos LastSwitchOutTime (s) |
O perfil padrão usa as seguintes predefinições para este gráfico:
Linha do tempo por CPU
Linha do tempo por processo, thread
Uso por prioridade no início da troca de contexto
Utilização por CPU
Utilização por processo, thread
Linha do tempo por CPU
O uso da CPU em uma linha do tempo por CPU mostra como o trabalho é distribuído entre os processadores. Figura 11 Linha do tempo de uso da CPU (precisa) por CPU exibe a linha do tempo em um sistema de oito processadores:
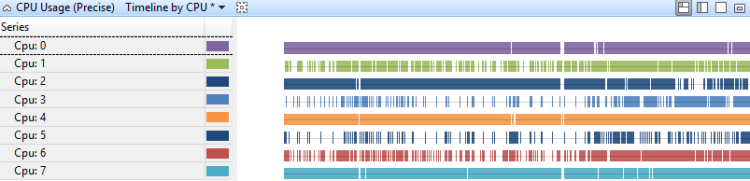
Figura 11 Linha do tempo de uso da CPU (precisa) por CPU
Linha do tempo por processo, thread
O uso da CPU em uma linha do tempo por processo e por thread mostra quais processos tiveram threads em execução em determinados momentos. Figura 12 Linha do tempo de uso (precisa) por processo, thread mostra essa linha do tempo em vários processos:
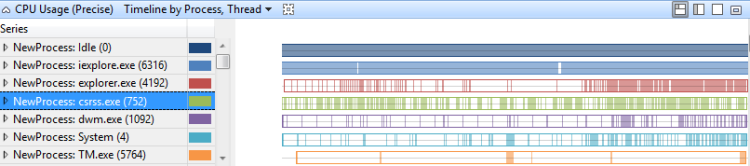
Figura 12 Linha do tempo de uso (precisa) por processo, thread
Uso por prioridade no início da troca de contexto
Este gráfico identifica intermitências de atividade de thread de alta prioridade em cada nível de prioridade. A Figura 13 Uso da CPU (preciso) por prioridade no início da alternância de contexto mostra a distribuição de prioridades:
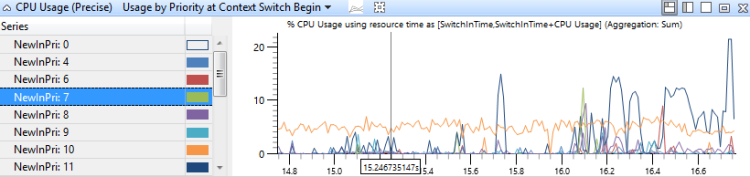
Figura 13 Uso da CPU (preciso) por prioridade no início da alternância de contexto
Utilização por CPU
Neste gráfico, o uso da CPU é agrupado e representado graficamente por CPU para mostrar como o trabalho é distribuído entre os processadores. Figura 14 Uso da CPU (preciso) Utilização por CPU mostra este gráfico para um sistema que tem oito processadores.
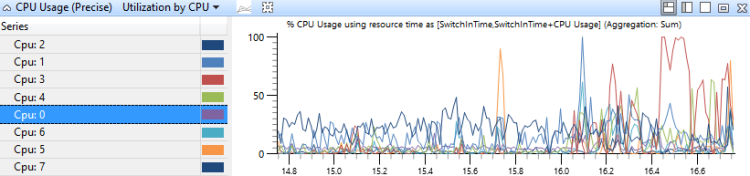
Figura 14 Utilização do uso da CPU (precisa) pela CPU
Utilização por processo, thread
Neste gráfico, o uso da CPU é agrupado primeiro por processo e depois por thread. Ele mostra o uso relativo de processos e threads em cada processo Figura 15 Uso da CPU (preciso) Utilização por processo, Thread mostra essa distribuição em vários processos:
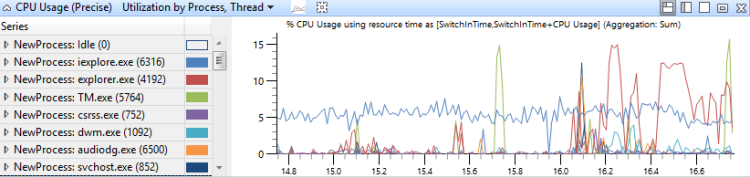
Figura 15 Utilização de uso da CPU (precisa) por processo, thread
Gráfico DPC/ISR
O gráfico DPC/ISR é a principal fonte de informações de DPC/ISR no WPA. Cada linha no gráfico representa um fragmento, que é um período de tempo durante o qual um DPC ou ISR foi executado ininterruptamente. Os dados são coletados no início e no final dos fragmentos. Dados adicionais são coletados quando um DPC/ISR é concluído. A Figura 16 Diagrama DPC/ISR mostra como isso funciona:
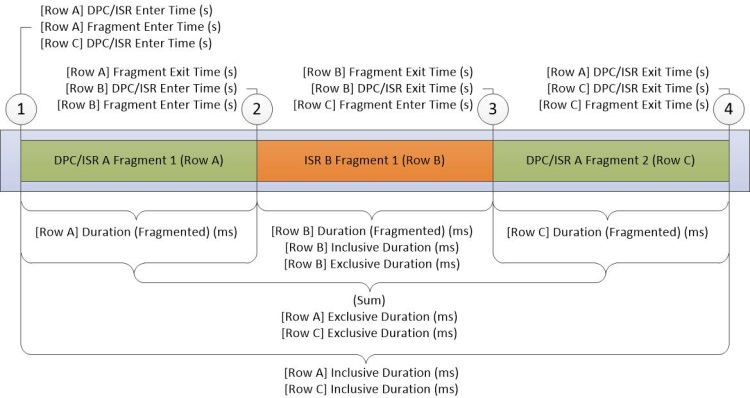
Figura 16 Diagrama DPC/ISR
A Figura 16 Diagrama DPC/ISR descreve os dados coletados durante as seguintes atividades:
O DPC/ISR-A começa a ser executado.
Uma interrupção de dispositivo que tem um nível de interrupção mais alto do que DPC/ISR-A faz com que o ISR-B interrompa o DPC/ISR A, encerrando assim o primeiro fragmento de DPC/ISR-A.
O ISR-B completa e, portanto, encerra o fragmento do ISR-B. O DPC/ISR-A retoma a execução em um segundo fragmento.
DPC/ISR-A é concluído, encerrando assim o segundo fragmento de DPC/ISR-A.
Uma linha para cada fragmento é exibida na tabela de dados. Os fragmentos para DPC/ISR-A compartilham informações idênticas com colunas que não são de fragmento.
As colunas do gráfico DPC/ISR descrevem informações no nível do fragmento ou colunas de nível DPC/ISR. Cada fragmento tem dados diferentes em colunas de nível de fragmento e dados idênticos em colunas DPC/ISR.
| Coluna | Detalhes |
|---|---|
% de duração (fragmentada) |
Duração (fragmentada) expressa como uma porcentagem do tempo total da CPU durante o período de tempo visível no momento. |
% Duração Exclusiva |
Duração exclusiva expressa como uma porcentagem do tempo total de CPU durante o período de tempo visível no momento. |
% Duração Inclusiva |
Duração inclusiva expressa como uma porcentagem do tempo total de CPU durante o período de tempo visível no momento. |
Address |
O endereço de memória da função DPC ou ISR. |
Contagem (DPCs/ISRs) |
A contagem de DPCs/ISRs representados por essa linha. Isso é sempre 1 para linhas que representam o fragmento final de um DPC/ISR; caso contrário, essa contagem será 0. |
Contagem (Fragmentos) |
O número de fragmentos representados pela linha. Isso é sempre 1 para linhas individuais. |
CPU |
O índice do processador lógico no qual o DPC ou ISR foi executado. |
Tipo DPC |
Para DPC, o tipo de DPC, - Regular ou Timer. Esse valor está em branco para um ISR. |
DPC/ISR Inserir Tempo(s) |
O tempo no rastreamento quando o DPC/ISR foi iniciado. |
Tempo(s) de saída do DPC/ISR |
O tempo desde o início do rastreamento até a conclusão do DPC/ISR. |
Duração (fragmentada) (ms) |
Tempo (s) de saída do fragmento menos Tempo (s) de entrada do fragmento (s) em milissegundos. |
Duração Exclusiva (ms) |
A soma das durações fragmentadas em ms. para todos os fragmentos deste DPC/ISR. |
Fragmento |
Se o DPC/ISR dessa linha tiver vários fragmentos, esse valor será True; caso contrário, será False. |
Fragmento |
Se esse não foi o único fragmento para esse DPC/ISR, esse valor será True; caso contrário, será False. |
Fragmento Inserir Tempo (s) |
A hora em que o fragmento começou a ser executado. |
Tempo (s) de saída do fragmento |
A hora em que o fragmento parou de ser executado. |
Função |
A função DPC ou ISR que foi executada. |
Duração Inclusiva (ms) |
Tempo (s) de saída DPC/ISR menos tempo (s) de entrada DPC/ISR em milissegundos. |
Índice de mensagens |
O índice de interrupção para interrupções sinalizadas por mensagem. |
Módulo |
O módulo que contém a função DPC ou ISR. |
Valor de retorno |
O valor retornado do DPC/ISR |
Tipo |
O tipo de evento; isto é- DPC ou Interrupção (ISR). |
Vetor |
O valor do vetor de interrupção no dispositivo. |
O perfil padrão usa as seguintes predefinições para este gráfico:
[DPC, ISR, DPC / ISR] Duração por CPU
[DPC, ISR, DPC / ISR] Duração por módulo, função
[DPC, ISR, DPC / ISR] Linha do tempo por módulo, função
[DPC, ISR, DPC / ISR] Duração por CPU
Os eventos DPC/ISR são agregados pela CPU na qual foram executados e são classificados por duração. Este gráfico mostra a alocação da atividade DPC entre CPUs. Figura 17 Duração do DPC/ISR por CPU mostra este gráfico para um sistema que tem oito processadores.
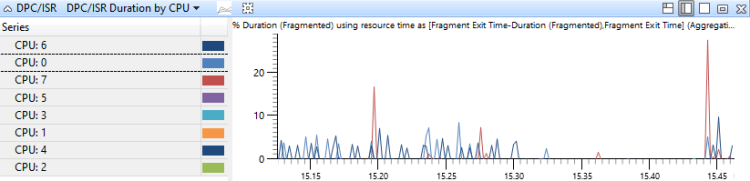
Figura 17 Duração do DPC/ISR por CPU
[DPC, ISR, DPC / ISR] Duração por módulo, função
Os eventos DPC/ISR são agregados neste gráfico pelo módulo e função das rotinas DPC/ISR e são classificados por duração. Isso mostra quais rotinas DPC/ISR consumiram mais tempo Figura 18 Duração do DPC/ISR por módulo, função mostra um período de tempo que incorre na atividade DPC/ISR em dois módulos:
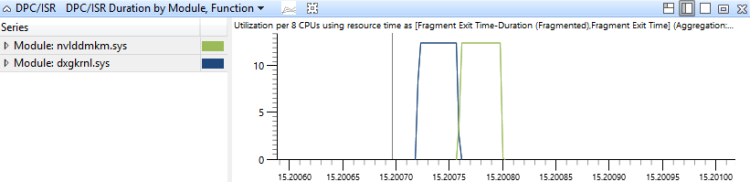
Figura 18 Duração do DPC/ISR por módulo, função
[DPC, ISR, DPC / ISR] Linha do tempo por módulo, função
Os eventos DPC/ISR são agregados neste gráfico pelo módulo e função das rotinas DPC/ISR. Eles são representados graficamente como uma linha do tempo. Este gráfico fornece uma visão detalhada do período de tempo durante o qual os DPCs/ISRs foram executados. Este gráfico também pode mostrar como DPC/ISRs únicos podem ser fragmentados. Figura 19 Linha do tempo DPC/ISR por módulo, função mostra uma linha do tempo de atividade em três módulos:

Figura 19 Linha do tempo DPC/ISR por módulo, função
Empilhar árvores
As árvores de pilha são exibidas nas tabelas Uso da CPU (Amostrado), Uso da CPU (Preciso) e DPC/ISR no WPA e em problemas relatados em relatórios de avaliação. As árvores de pilha retratam as pilhas de chamadas associadas a vários eventos durante um período de tempo. Cada nó na árvore representa um segmento de pilha que é compartilhado por um subconjunto dos eventos. A árvore é construída a partir das pilhas individuais e é mostrada na Figura 20 Pilhas de três eventos:

Figura 20 Pilhas de três eventos
A Figura 21 Segmentos comuns identificados mostra como as sequências comuns são identificadas para este gráfico:

Figura 21 Segmentos comuns identificados
A Figura 22 Tree Built from Stacks mostra como os segmentos comuns são combinados para formar os nós de uma árvore:
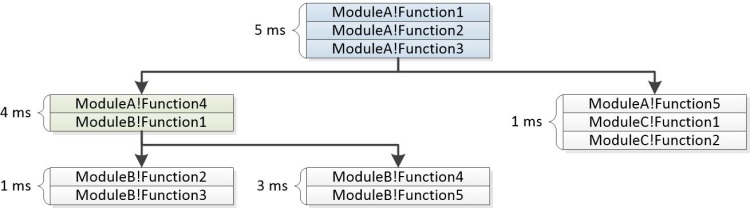
Figura 22 Árvore criada a partir de pilhas
A coluna Pilhas na interface do usuário do WPA contém um expansor para cada nó não folha. Em problemas relatados pela avaliação, a árvore é exibida junto com os pesos agregados. Algumas ramificações podem ser removidas do gráfico se seus pesos não atenderem a um limite especificado. A pilha de exemplo abaixo mostra como os eventos representados acima são exibidos como parte de um problema relatado pela avaliação.
5ms ModuleA!Function1
5ms ModuleA!Function2
5ms ModuleA!Function3
|
4ms |-ModuleA!Function4
4ms | ModuleB!Function1
| |
1ms | |-ModuleB-Function2
1ms | | ModuleB-Function3
| |
3ms | |-ModuleB!Function3
3ms | ModuleB!Function4
|
1ms |-ModuleA!Function5
1ms ModuleC!Function1
1ms ModuleC!Function2
O <itself> nó em uma pilha representa o tempo em que uma função em si está no topo da pilha. O <itself> nó não inclui o tempo gasto em funções chamadas pela função pai. Essa duração é chamada de tempo exclusivo gasto na função.
Por exemplo, Function1 chama Function2. Function2 gastou 2ms em um loop intensivo de CPU e chamou outra função que foi executada por 4ms. Isso pode ser representado pela seguinte pilha:
6ms ModuleA!Function1
|
2ms |-<itself>
4ms |-ModuleA!Function2
4ms ModuleB!Function3
4ms ModuleB-Function4
Técnicas
Esta seção descreve uma abordagem padrão para análise de desempenho. Ele fornece técnicas que você pode usar para investigar problemas comuns de desempenho relacionados à CPU.
A análise de desempenho é um processo de quatro etapas:
Defina o cenário e o problema.
Identifique os componentes envolvidos e o intervalo de tempo relevante.
Crie um modelo do que deveria ter acontecido.
Use o modelo para identificar problemas e investigar as causas raiz.
Defina o cenário e o problema
O primeiro passo na análise de desempenho é definir claramente o cenário e o problema. Muitos problemas de desempenho afetam cenários que são medidos por métricas de avaliação. Por exemplo:
Cenário 1: Um recurso físico não está sendo totalmente utilizado. Por exemplo, um servidor não pode utilizar totalmente uma conexão de rede porque não pode criptografar pacotes com rapidez suficiente.
Cenário 2: Um recurso físico está sendo utilizado mais do que deveria. Por exemplo, um sistema usa recursos significativos da CPU durante um período ocioso que usa energia da bateria.
Cenário 3: As atividades não estão sendo concluídas na taxa exigida. Por exemplo, os quadros são descartados durante a reprodução de vídeo porque os quadros não estão sendo decodificados com rapidez suficiente.
Cenário 4: Uma atividade foi atrasada. Por exemplo, o usuário iniciou o Internet Explorer, mas demorou mais do que o esperado para abrir uma guia.
Os cenários 3 e 4 relacionados aos recursos da CPU são abordados neste guia. Os cenários 1 e 2 estão fora do escopo e não são cobertos. Para analisar esses problemas, você pode começar com uma observação ambígua como "é muito lento" e fazer perguntas adicionais para identificar o cenário e o problema exato.
Identifique os componentes e o período de tempo
Depois que o cenário e o problema forem identificados, você poderá identificar os componentes envolvidos e o período de interesse. Os componentes incluem recursos de hardware, processos e threads.
Muitas vezes, você pode encontrar o intervalo de tempo de interesse identificando a atividade associada no guia de análise. Uma atividade é um intervalo entre um evento de início e um evento de parada que você pode selecionar e ampliar, no WPA. Se uma atividade não estiver definida, você poderá encontrar o intervalo de tempo procurando eventos genéricos específicos associados ao cenário ou procurando alterações na utilização de recursos que possam marcar o início e o fim de um cenário. Por exemplo, se a CPU ficou ociosa por dois segundos e, em seguida, totalmente utilizada por quatro segundos e, em seguida, ociosa novamente por dois segundos, os quatro segundos de utilização total podem ser a área de interesse em um rastreamento que captura a reprodução de vídeo.
Criar um modelo
Para entender as causas raiz de um problema, você deve ter um modelo do que deveria ter acontecido. O modelo começa com o problema ou qualquer meta associada à métrica; por exemplo, "Esta operação deve ter sido concluída em menos de 5 segundos".
Um modelo mais completo contém informações sobre como os componentes devem ser executados. Por exemplo, qual comunicação é esperada entre os componentes? Qual utilização de recursos é típica? Quanto tempo as operações geralmente levam?
As informações para o modelo geralmente podem ser encontradas no guia de análise de avaliação. Se esse recurso não estiver disponível, você poderá produzir um rastreamento de hardware e software semelhantes que não exibam o problema de desempenho, para criar um modelo.
Use o modelo para identificar problemas e, em seguida, investigar as causas raiz
Depois de ter um modelo, você pode comparar um traço com o modelo para identificar problemas. Por exemplo, um modelo para uma atividade específica chamada Suspender Dispositivos pode sugerir que toda a atividade deve ser concluída em três segundos, enquanto cada instância de uma subatividade chamada Suspender <Nome> do Dispositivo não deve levar mais de 100 ms. Se duas instâncias da subatividade Suspender <nome> do dispositivo levarem 800 ms cada, você deverá investigar essas instâncias.
Cada desvio do modelo pode ser analisado para encontrar uma causa raiz. Você deve examinar o estado dos threads envolvidos e procurar causas raiz comuns. Algumas das principais causas raiz relacionadas à CPU, para atividades que não são concluídas na taxa necessária ou estão atrasadas, são descritas aqui:
Uso direto da CPU: os threads apropriados receberam todos os recursos da CPU, mas o programa necessário não foi executado com rapidez suficiente. Isso pode ser causado por um mau funcionamento do programa ou por hardware lento.
Interferência de thread: um thread não obteve tempo de execução suficiente porque outros threads estavam em execução. Nesse caso, o thread é considerado faminto ou preemptado.
Interferência DPC/ISR: os threads não obtiveram tempo de execução suficiente porque as CPUs estavam ocupadas processando DPCs ou ISRs.
Em muitos casos, uma dessas causas raiz não afeta visivelmente o thread, e o thread passa a maior parte do tempo em um estado de espera. Nesse caso, você deve identificar e investigar o evento pelo qual o thread está aguardando. Esse tipo recursivo de investigação é chamado de análise de espera e começa identificando o caminho crítico.
Técnica Avançada: Análise de Espera e o Caminho Crítico
Uma atividade é uma rede de operações, algumas sequenciais e outras paralelas, que fluem de um evento inicial para um evento final. Qualquer par de eventos de início/término em um rastreamento pode ser exibido como uma atividade. O caminho mais longo por essa rede de operações é conhecido como caminho crítico. Reduzir a duração de qualquer operação no caminho crítico reduz diretamente a duração da atividade geral, embora também possa alterar o caminho crítico.
A Figura 23 Operações de Atividade mostra a atividade de três threads. O Thread-1 envia o evento de início da atividade e aguarda que o Thread-2 e o Thread-3 concluam suas tarefas. O Thread-2 conclui sua tarefa primeiro, seguido pelo Thread-3. Quando ambos os threads tiverem concluído suas tarefas, o Thread-1 será preparado e concluirá o evento de atividade.
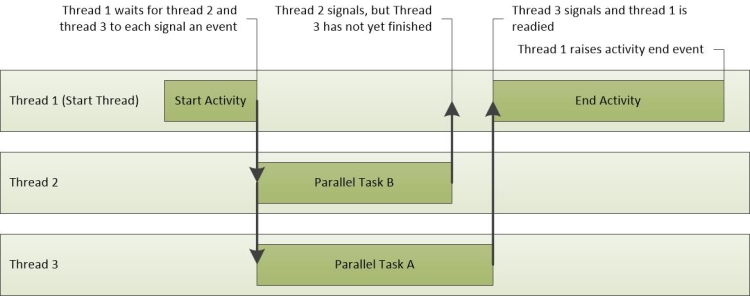
Figura 23 Operações de atividade
Nesse cenário, o caminho crítico inclui partes do Thread-3 e do Thread-1. Eles são rastreados na Figura 24 Caminho Crítico. Como o Thread-2 não está no caminho crítico, o tempo necessário para concluir sua tarefa não afeta o tempo geral da atividade.
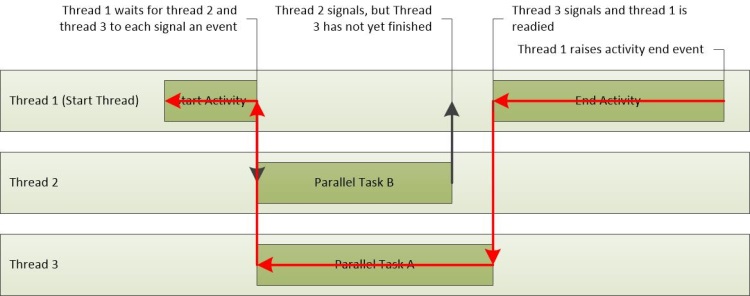
Figura 24 Caminho crítico
O caminho crítico é uma resposta literal de baixo nível para a pergunta de por que uma atividade levou tanto tempo quanto levou. Depois que os principais segmentos do caminho crítico são conhecidos, eles podem ser analisados para encontrar os problemas que contribuem para o atraso geral.
Abordagem geral para encontrar o caminho crítico
O primeiro passo para encontrar o caminho crítico é revisar o modelo de cenário para entender o propósito e a implementação da atividade.
Entender uma atividade pode ajudar a identificar operações, processos e threads específicos que podem estar no caminho crítico. Por exemplo, um atraso na atividade de inicialização rápida do Gerenciador de Retomada de Inicialização pode ser causado por aplicativos RunOnce e pelo processo de inicialização do Explorer, que exigem uma quantidade significativa de E/S.
Depois de examinar o modelo de cenário, verifique se a avaliação relatou algum problema para a atividade afetada. Muitas vezes, uma aproximação do caminho crítico é incluída nos problemas de atraso relatados pela avaliação. O caminho crítico é mostrado como uma sequência de esperas e ações prontas. Ele pode ser lido do início ao fim como uma sequência de eventos, com o segmento atrasado primário do caminho crítico no meio da lista. A última entrada na lista é a ação que preparou o thread que concluiu a atividade.
Se você precisar procurar manualmente o caminho crítico, recomendamos que você identifique o processo e o thread que concluiu a atividade e trabalhe de trás para frente a partir do instante em que a atividade foi concluída. Você pode identificar o processo e o thread que iniciou uma atividade e o processo e o thread que concluíram uma atividade por meio do gráfico Atividades no WPA.
O gráfico Atividades é exibido quando o rastreamento é carregado por meio de um arquivo XML de resultados de avaliação. Para identificar o processo e o thread associados a uma atividade específica, expanda o gráfico para a Atividade de interesse e alterne a exibição para Gráfico+Tabela. Defina o modo de gráfico como Tabela. As colunas Iniciar Processo, ID do Thread Inicial, Finalizar Processo e ID do Thread Final são exibidas para cada atividade na tabela.
Depois de conhecer o processo de início e término, o thread e a implementação da atividade, o caminho crítico pode ser rastreado para trás. Comece analisando o thread que concluiu a atividade para determinar como esse thread passou a maior parte do tempo: em execução, pronto ou aguardando.
O tempo de execução significativo indica que o uso direto da CPU pode ter contribuído para a duração do caminho crítico. O tempo gasto no modo pronto indica que outros threads contribuem para a duração do caminho crítico, impedindo que um thread no caminho crítico seja executado. O tempo gasto em espera aponta para E/S, temporizadores ou outros threads e processos no caminho crítico para o qual o thread atual estava aguardando.
Cada thread que preparou o thread atual é provavelmente outro link no caminho crítico e também pode ser analisado até que a duração do caminho crítico seja contabilizada.
Procedimento: Encontrando o caminho crítico no WPA
O procedimento a seguir pressupõe que você tenha identificado uma atividade no gráfico Atividades para a qual deseja localizar o caminho crítico.
Você pode identificar o processo que concluiu a atividade passando o mouse sobre a atividade no gráfico Atividades .
Adicione o gráfico Uso da CPU (Preciso). Amplie a atividade afetada e aplique a predefinição Utilização por processo, Thread .
Clique com o botão direito do mouse nos cabeçalhos das colunas e torne visíveis as colunas ReadyThreadStack e Uso da CPU (ms). Remova as colunas Pronto (us) [Max] e Aguarda (us) [Max].
Expanda o processo de destino e classifique-o, respectivamente, por Uso da CPU (ms), Pronto (us) [Soma] e Esperas (us) [Soma].
Pesquise os NewThreadIds no processo que tem a maior quantidade de tempo gasto no estado Em execução, Pronto ou Aguardando.
Os threads que passam um tempo significativo nos estados Em execução ou Pronto podem representar o uso direto da CPU no caminho crítico. Observe suas IDs de thread.Threads que passam um tempo significativo no estado Aguardando podem estar aguardando E/S, um temporizador ou outro thread no caminho crítico.
Para descobrir o que os threads estavam esperando, expanda o grupo NewThreadId para exibir o ReadyThreadStack.
Expanda [Raiz].
As pilhas que começam com KiDispatchInterrupt não estão relacionadas a outro thread. Para determinar o que o thread estava aguardando nessas pilhas, expanda KiDispatchInterrupt e exiba as funções na pilha filho. IopfCompleteRequest indica que o thread preparado estava aguardando E/S. KiTimerExpiration indica que o thread preparado estava aguardando um temporizador.
Expanda as pilhas que não começam com KiDispatchInterrupt até ver um ReadyingProcess e um ReadyingThread. Se o processo já estiver expandido, expanda o NewThreadId que corresponde ao ReadyingThread. Repita essa etapa até encontrar um thread em execução, pronto, aguardando outro motivo ou aguardando um processo diferente. Se o thread estiver aguardando um processo diferente, repita esse procedimento usando esse processo.
Exemplo
Este exemplo apresenta um atraso na atividade de inicialização rápida do Gerenciador de Retomada de Inicialização. Uma pesquisa no painel Problemas mostra que sete problemas do tipo atraso são relatados para essa atividade. Cada uma dessas questões pode ser revisada como um segmento do caminho crítico. Os seguintes segmentos-chave são identificados:
O thread 3872 do TestBootStrapper.exe de processo (3024) é preemptado por 2,1 segundos.
O thread 3872 do processo TestBootStrapper.exe (3024) usa 1 segundo de tempo de CPU.
O thread 3872 do processo TestBootStrapper.exe (3024) libera um hive do Registro por 544 milissegundos.
O thread 3872 do processo TestBootStrapper.exe (3024) dorme por 513 milissegundos.
Os threads 4052 e 4036 de Explorer.exe lidos do disco, causando um atraso de 461 milissegundos.
O thread 3872 do processo TestBootStrapper.exe (3024) morre de fome por 187 milissegundos.
O thread 3872 do processo TestBootStrapper.exe grava 3,5 MB no disco, causando um atraso de 178 milissegundos.
Os problemas mostram que essa atividade foi atrasada em 5,2 segundos. Esses atrasos contribuem com uma grande proporção da duração geral de 6,3 segundos das atividades. O aplicativo TestBootStrapper.exe é o principal responsável pelo atraso, principalmente porque antecipou outras tarefas de processamento.
Investigue problemas no caminho crítico
Amplie a região afetada e adicione as colunas ReadyThreadStack e Uso da CPU (ms).
Nesse caso, Explorer.exe é o processo que conclui a atividade. Expanda o processo explorer.exe e classifique-o, respectivamente, por Uso da CPU (ms), Pronto (us) [Soma] e Esperas (us) [Soma], conforme mostrado nas figuras a seguir:

Figura 25 Atividade por uso da CPU (ms)

Figura 26 Atividade por Ready (us)

Figura 27 Atividade de Waits (us)
A classificação pela coluna Uso da CPU (ms) mostra uma linha filho superior de 299 milissegundos. A classificação pela coluna Pronto (us) [Soma] mostra uma linha secundária superior de 46 ms. A classificação pela coluna Aguarda (us) [Soma] mostra uma linha filho superior de 5749 milissegundos e uma segunda linha de 4902 milissegundos. Como essas linhas contribuem significativamente para o atraso, você deve investigá-las mais a fundo.
Expanda as pilhas para revelar os threads de preparação, conforme mostrado nas figuras a seguir:
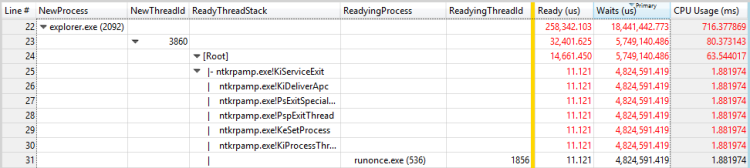
Figura 28 Processo de preparação e encadeamento de preparação para um encadeamento
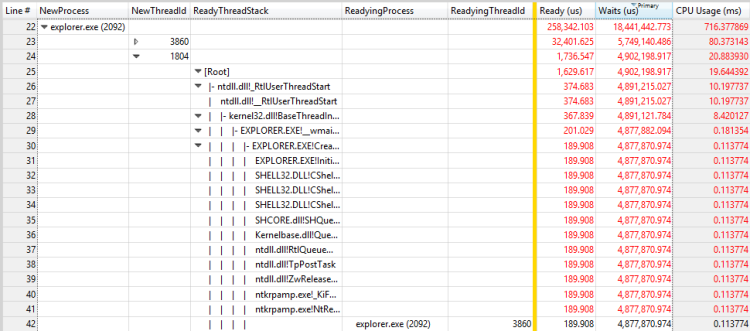
Figura 29 Processo de preparação e threading de preparação para outro thread
Neste exemplo, o primeiro thread passa a maior parte do tempo aguardando a saída do processo RunOnce.exe. Você deve investigar por que o processo de RunOnce.exe está demorando tanto para ser concluído. O segundo thread está aguardando o primeiro thread e provavelmente é um elo insignificante na mesma cadeia de espera.
Repita as etapas deste procedimento para RunOnce.exe. A coluna principal de contribuição é Waits (nós) e tem quatro possíveis contribuidores.
Expanda cada colaborador para ver se os três primeiros colaboradores estão esperando o quarto colaborador. Essa situação torna os três primeiros colaboradores insignificantes para a cadeia de espera. O quarto colaborador está aguardando outro processo, TestBootStrapper.exe.
Esse cenário é mostrado na Figura 30 Processo de preparação e Threading de preparação para um thread no RunOnce.exe:
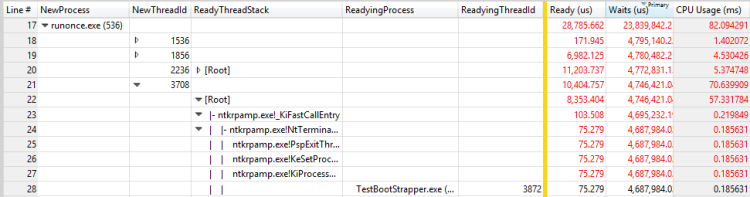
Figura 30 Processo de preparação e linha de execução de preparação para um thread no RunOnce.exe
Repita as etapas deste procedimento para TestBootStrapper.exe. Os resultados são mostrados nas três figuras a seguir:

Figura 31 Threads por uso da CPU (ms)

Figura 32 Threads por Ready (us)

Figura 33 Threads por Waits (us)
O thread 3872 passou aproximadamente 1 segundo em execução, 2 segundos pronto e 1,3 segundos aguardando. Como esse thread também é o thread de preparação para o thread 3872, os tempos de execução e pronto provavelmente contribuem para o atraso. A avaliação relata os seguintes problemas cujos tempos correspondem aos atrasos:
O thread 3872 do processo TestBootStrapper.exe (3024) é preemptado por 2,1 segundos.
O thread 3872 do processo TestBootStrapper.exe (3024) morre de fome por 187 milissegundos.
O thread 3872 do processo TestBootStrapper.exe (3024) usa 1 segundo de tempo de CPU.
Para encontrar outros problemas de contribuição, exiba o evento pelo qual o thread 3872 estava aguardando. Expanda ReadyThreadStack para exibir os colaboradores dos 1,3 segundos de espera, conforme mostrado na Figura 34 Colaboradores do tempo de espera:

Figura 34 Contribuintes para o tempo de espera
KiRetireDpcList normalmente está relacionado à E/S e KiTimerExpiration é um temporizador. Você pode exibir como as E/S e o temporizador foram iniciados removendo o ReadyThreadStack e, em seguida, exibindo o NewThreadStack. Essa exibição mostra três funções relacionadas, conforme mostrado na Figura 35 E/Ss e Timer em NewThreadStack:

Figura 35 E/S e temporizador em NewThreadStack
Essa exibição revela os seguintes detalhes:
O thread 3872 do processo TestBootStrapper.exe (3024) libera um hive do Registro por 544 milissegundos.
O thread 3872 do processo TestBootStrapper.exe (3024) dorme por 513 milissegundos.
O thread 3872 do processo TestBootStrapper.exe grava 3,5 MB no disco, causando um atraso de 178 milissegundos.
Quando você começou a investigar o caminho crítico, analisou a causa de espera mais significativa em Explorer.exe e desconsiderou todas as partes do caminho crítico que ocorreram após essa causa de espera. Para capturar essa seção anteriormente desconsiderada do caminho crítico, você deve olhar para a linha do tempo. Adicione o uso da CPU (preciso) e aplique a linha do tempo por processo, predefinição de thread .
Filtre para incluir apenas os processos identificados como parte do caminho crítico. O gráfico resultante é mostrado na Figura 36 Linha do tempo do caminho crítico:

Figura 36 Linha do tempo do caminho crítico
A Figura 36 Linha do tempo do caminho crítico mostra que Explorer.exe executou mais trabalho depois que parou de esperar por RunOnce.exe. Amplie o período de tempo após a cadeia de espera analisada anteriormente e execute outra análise. Nesse caso, a análise revela um grande número de threads internos ao Explorer.exe e nenhum rastreamento claro no caminho crítico. Nesse caso, uma análise mais aprofundada provavelmente não produzirá insights acionáveis.
Uso direto da CPU
As atividades geralmente são atrasadas porque um thread no caminho crítico usa um tempo de CPU significativo. Usando o modelo de estado de thread, você pode ver que esse problema é caracterizado por um thread no caminho crítico que gasta uma quantidade excepcional de tempo no estado Running. Em alguns hardwares, esse uso intenso da CPU pode contribuir para atrasos.
Identificação do problema
Muitas avaliações usam heurística para identificar problemas diretos relacionados ao uso da CPU. O uso significativo da CPU no caminho crítico é relatado como um problema da seguinte forma:
O uso da CPU pelo processo P atrasa a atividade afetada A por x segundos
Onde P é o processo que está em execução, A é a atividade e x é o tempo em segundos.
Se esses problemas forem relatados para uma atividade que incorre em atrasos, o uso direto da CPU poderá ser a causa.
Investigar o uso direto da CPU
Você pode identificar manualmente o problema procurando CPUs individuais que incorrem em 100% de uso da CPU no gráfico Uso da CPU (Amostrado).
Amplie uma área de interesse no gráfico e selecione a predefinição Utilização por processo e thread .
Por padrão, a tabela exibe as linhas na parte superior que têm o maior uso agregado da CPU. Esses threads também são exibidos na parte superior do gráfico Uso da CPU (Amostrado).
Observação Em um sistema que tem vários processadores, um thread que usa 100% de um único processador parecerá estar consumindo 100/(número de processadores lógicos). Nesse tipo de sistema, apenas o thread ocioso virtual (PID 0, TID 0) pode mostrar uma utilização maior do processador do que 100/(número de processadores lógicos). Se os processos e threads que consomem mais CPU corresponderem a qualquer thread no caminho crítico, o uso direto da CPU provavelmente será um fator.
Exemplo de problema de uso direto da CPU relatado pela avaliação
O uso da CPU pelo processo TestUM.exe (4024) atrasa a atividade afetada, processo de desligamento rápido de inicialização TestIM.exe, por 2,1 segundos. Este exemplo é mostrado na Figura 37 Thread 3208:
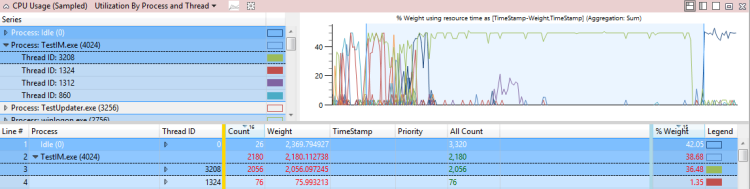
Figura 37 Rosca 3208
Investigação
Depois de descobrir que o uso direto da CPU contribui para um atraso no caminho crítico, você deve identificar os módulos e funções específicos que contribuem para o atraso.
Técnica: Examinar um problema de uso direto da CPU relatado pela avaliação
Você pode expandir um problema de uso direto da CPU relatado pela avaliação para exibir o caminho crítico afetado pelo uso direto da CPU. Se você expandir o nó associado ao uso da CPU, as pilhas associadas ao uso da CPU e aos módulos associados serão exibidas. Essa exibição é mostrada na Figura 38 Segmento de uso expandido da CPU:
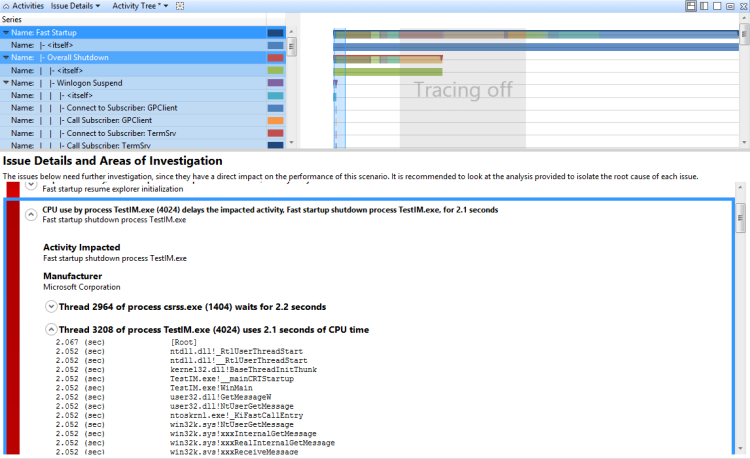
Figura 38 Segmento de uso expandido da CPU
Técnica: explorar manualmente as pilhas de um problema de uso direto da CPU
Se a avaliação não relatou um problema ou se você precisar de verificação adicional, poderá usar o gráfico Uso da CPU (Amostrado) para coletar manualmente informações sobre os módulos e funções envolvidos em um problema de uso da CPU. Para fazer isso, você deve ampliar a área de interesse e exibir as pilhas classificadas por uso da CPU.
Explore manualmente as pilhas de um problema de uso direto da CPU
No menu Rastrear, clique em Carregar Símbolos.
Amplie a linha do tempo para exibir apenas a parte do caminho crítico afetada pelo problema da CPU.
Aplique a predefinição Utilização por processo e Thread .
Adicione a coluna Pilha à exibição e arraste-a para a direita de ID do Thread (à esquerda da barra).
Expanda o processo e o thread para exibir as árvores de pilha.
As linhas na pilha são classificadas em ordem decrescente por % de peso do uso da CPU. Isso coloca as pilhas mais interessantes no topo. À medida que você expande as pilhas, observe a coluna % Peso para garantir que seu foco permaneça nas linhas que têm o uso mais alto.
Para extrair uma cópia da pilha, selecione todas as linhas, clique com o botão direito do mouse e clique em Copiar Seleção.
Resolução
Você pode aplicar soluções nos níveis de configuração e componente para resolver o alto uso da CPU.
O uso direto da CPU tem maior impacto em computadores com processadores de baixo custo. Nesses casos, você pode adicionar mais poder de processamento ao computador. Ou você pode remover os módulos problemáticos do caminho crítico ou do sistema. Se você puder alterar os componentes, considere um esforço de redesign para obter um dos seguintes resultados:
Remova o código com uso intensivo de CPU do caminho crítico
Use algoritmos mais eficientes em termos de CPU
Adiar ou armazenar em cache o trabalho
Interferência de rosca
O uso da CPU por threads que não estão no caminho crítico (e que podem não estar relacionados à atividade) pode fazer com que os threads que estão no caminho crítico sejam atrasados. O modelo de estado de thread mostra que esse problema é caracterizado por threads no caminho crítico que passam uma quantidade incomum de tempo no estado Pronto.
Identificação do problema
Muitas avaliações usam heurísticas para identificar problemas relacionados à interferência. Estes são relatados em uma das duas formas a seguir:
O processo P está faminto. A fome causa um atraso na atividade afetada A de x ms.
O processo P é preemptado. A preempção causa um atraso na atividade A impactada de x ms.
Onde P é o processo, A é a atividade e x é o tempo em ms.
A primeira forma reflete a interferência de threads no mesmo nível de prioridade que o thread no caminho crítico. A segunda forma reflete a interferência de threads que estão em um nível de prioridade mais alto do que o thread no caminho crítico.
Se esses tipos de problemas forem relatados para uma atividade atrasada, a interferência de thread poderá ser a causa. Você pode usar o gráfico Uso da CPU (Preciso) para identificar manualmente o problema.
Identificar problemas de interferência de thread
Amplie o intervalo e aplique a predefinição Utilização por CPU . Uma utilização de 100% em todas as CPUs indica um problema de interferência.
Aplique a predefinição Utilização por processo, Thread e classifique pela primeira coluna Pronto (us). (Esta é a coluna que inclui o Agregação de soma .)
Expanda o processo da atividade afetada e examine o tempo Pronto para threads no caminho crítico. Esse valor é o tempo máximo que o atraso pode ser reduzido resolvendo qualquer problema de interferência de thread. Um valor com uma magnitude significativa em relação ao atraso que está sendo investigado indica que existe um problema de interferência de thread.
A Figura 39 A utilização da CPU está próxima de 100% e a Figura 40 Problema de interferência de thread representam este cenário:

Figura 39 A utilização da CPU está próxima de 100%
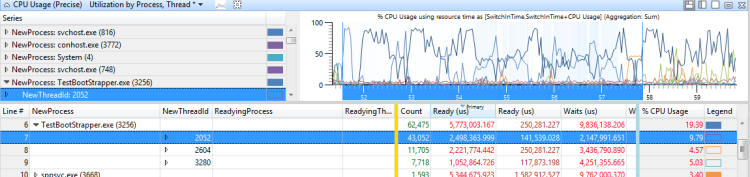
Figura 40 Problema de interferência de thread
Investigação
Depois que o problema for identificado, você deverá determinar por que o thread afetado passou tanto tempo no estado Pronto.
Técnica: Determinar por que um thread passou algum tempo no estado pronto
Você pode usar o gráfico Uso da CPU (Preciso) para determinar por que um thread passou algum tempo no estado Pronto. Primeiro, você deve determinar se o thread é restrito a determinados processadores. Embora você não possa obter essas informações diretamente, você pode examinar o histórico de uso da CPU de um thread durante períodos de alta utilização da CPU. Este é o período em que os threads tendem a alternar frequentemente entre os processadores.
Determinar as restrições do processador de um thread
Amplie a região afetada.
Adicione o gráfico Uso da CPU (Preciso) e aplique a predefinição Utilização por Processo, Thread .
Use a caixa de diálogo Avançado para adicionar uma coluna Cpu que tenha um modo de agregação de Contagem Exclusiva à direita de NewThreadId.
Filtre o gráfico para mostrar apenas os threads nos quais você está interessado.
O valor na coluna Cpu reflete o número de processadores nos quais o thread foi executado durante o intervalo de tempo atual. Durante períodos de 100% de utilização da CPU, esse número se aproxima do número de processadores nos quais esse thread pode ser executado. Se o valor for menor que o número de processadores disponíveis, o thread provavelmente será restrito a determinadas CPUs.
A Figura 41 Threads Restritos fornece um exemplo deste gráfico:
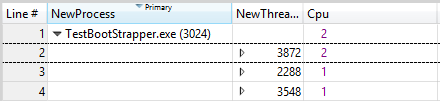
Figura 41 Threads restritos
Depois de conhecer as restrições do processador de um thread, você pode determinar o que preemptou ou privou o thread. Para fazer isso, você deve identificar os intervalos que o thread passou no estado Pronto e, em seguida, examinar quais outros threads ou processos estavam em execução durante esses intervalos.
Determine o que antecipou ou deixou o thread sem receita
Construa um gráfico que mostre quando o thread estava no estado Pronto e aplique a predefinição Utilização por Processo, Thread .
Abra o Editor de Exibição, clique em Avançado e selecione a guia Configuração do Gráfico.
Defina a Hora de Início como ReadyTime (s) e defina a Duração como Pronto (us), conforme mostrado na Figura 42 Colunas de Tempo Pronto. Clique em OK.

Figura 42 Colunas de tempo de prontidão
No Editor de Exibição, substitua a coluna Uso da CPU (%) pela coluna Pronto (us) [Soma].
Selecione o thread de interesse para produzir um gráfico semelhante ao Gráfico de Tempo Pronto da Figura 43:

Figura 43 Gráfico de tempo de prontidão
Nesse caso, o thread passou um tempo significativo no estado Pronto. Para determinar sua prioridade típica, adicione uma agregação Average à coluna NewInPri .
Nesse caso, a prioridade média do thread é exatamente 8. Esse número indica que provavelmente é um thread em segundo plano que nunca recebe elevações de prioridade.
Depois que a prioridade média for conhecida, examine a atividade da CPU para as CPUs nas quais o thread pode ser executado.
Nesse caso, o thread foi determinado como tendo afinidade apenas com a CPU 1.
Adicione outro gráfico de Uso da CPU (Preciso) e aplique a predefinição Utilização por CPU . Selecione as CPUs relevantes.
Abra o modo de exibição Avançado e adicione um filtro para a prioridade que você encontrou anteriormente para filtrar esse thread. Esse cenário é mostrado na Figura 44 Filtro de thread:
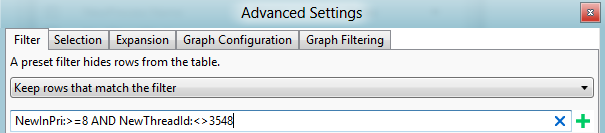
Figura 44 Filtro de rosca
Na Figura 45 Uso da CPU, Tempo de Preparação e Outras Atividades de Thread, o gráfico superior mostra o uso da CPU do thread 3548. O gráfico do meio mostra a hora em que o thread estava pronto e o gráfico inferior mostra a atividade nas CPUs nas quais o thread foi autorizado a ser executado (neste caso, Cpu1).
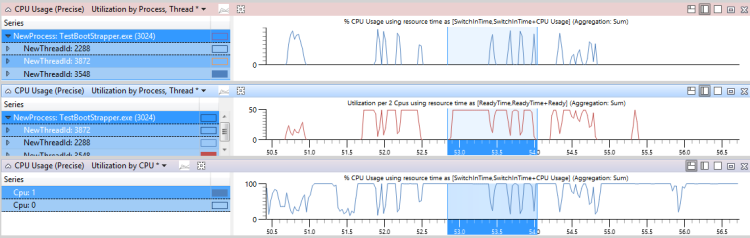
Figura 45 Uso da CPU, tempo de prontidão e outras atividades de thread
Amplie uma região em que o thread estava pronto, mas não foi executado, na maior parte do tempo durante esse intervalo.
No gráfico Uso da CPU, adicione NewInPri à esquerda da barra e examine os resultados.
Threads ou processos que têm prioridades iguais à prioridade do thread de destino mostram o tempo em que o thread ficou sem energia. Threads ou processos que têm prioridade mais alta do que a prioridade do thread de destino mostram a hora em que o thread foi preemptado. Você pode calcular o tempo total em que o thread foi preemptado adicionando os tempos de todos os threads e ações preemptivas.
A Figura 46 Uso por prioridade quando o thread de destino estava pronto mostra que 730 ms do tempo do thread foram preemptados e 300 ms do tempo do thread foram perdidos. (Esta figura é ampliada para um intervalo de 1192ms.)
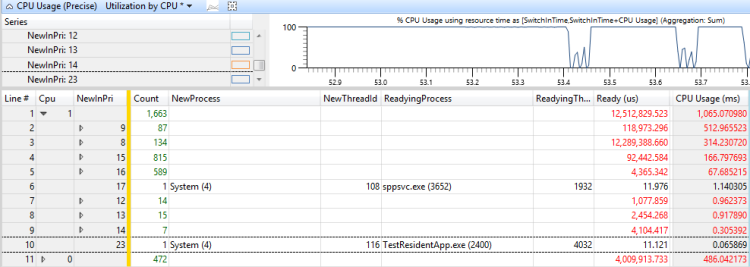
Figura 46 Uso por prioridade quando o thread de destino estava pronto
Para determinar quais threads são responsáveis pela preempção e privação desse thread, adicione a coluna NewProcess à direita da coluna NewInPri e examine os níveis de prioridade nos quais os processos estavam em execução. Nesse caso, a preempção e a fome foram causadas principalmente por outro fio no mesmo processo e por TestResidentApp.exe. Você pode supor que esses processos recebem elevações de prioridade periódicas acima de sua prioridade básica.
Resolução
Você pode resolver problemas de preempção ou privação alterando a configuração ou os componentes. Considere as seguintes correções:
Remova os processos problemáticos do sistema.
Ajuste a prioridade básica dos processos problemáticos...
Altere o horário em que os processos problemáticos são executados; por exemplo, atrase a hora de início para ocorrer quando o computador for reinicializado.
Se os componentes problemáticos puderem ser alterados, reprojete-os para serem menos intensivos em CPU ou para serem executados em uma prioridade mais baixa.
Interferência DPC/ISR
Quando o tempo excessivo do processador é consumido pela execução de DPCs e ISRs, pode não haver tempo de CPU disponível suficiente para executar threads. Essa situação pode causar atrasos semelhantes à interferência de thread. Quando os threads devem concluir as operações em uma taxa regular de alta frequência, como na reprodução de vídeo ou animação, a interferência de DPCs e ISRs pode causar problemas operacionais.
Identificação do problema
Muitas avaliações usam heurísticas para identificar problemas relacionados a DPC/ISR. A atividade DPC/ISR é identificada como suspeita quando é relatada como um problema da seguinte forma:
DPC D excede o limite de m milissegundos x vezes durante P. As n instâncias desse DPC são executadas por um total combinado de t milissegundos.
Onde D é o DPC, m é o número de milissegundos que define o limite, x é o número de vezes que o DPC excedeu o limite, P é o processo atual, n é o número de instâncias que o DPC executou e t é o tempo total em milissegundos que o DPC executou acima do limite.
Por exemplo, o seguinte problema é relatado por uma avaliação:
DPC sdbus.sys! SdbusWorkerDpc excede a meta de 3,0 milissegundos 153 vezes durante o tempo de vida do mecanismo de mídia. As 153 instâncias desse DPC são executadas por um total combinado de 864 milissegundos
Se esse problema for relatado para uma atividade que exibe eventos de problema ou atrasos, a atividade DPC/ISR poderá ser a causa.
Identifique manualmente a interferência DPC/ISR
Para identificar manualmente a interferência DPC/ISR, abra um rastreamento no WPA e identifique os eventos problemáticos de interesse. Esses são eventos genéricos específicos da avaliação, como Microsoft-Windows-Dwm-Core:SCHEDULE_GLITCH ou Microsoft-Windows-MediaEngine:DroppedFrame.
Ao lado do gráfico de eventos, adicione o gráfico DPC/ISR Duration by CPU . Se os picos no gráfico DPC/ISR Duration by CPU se alinharem com os eventos do problema, os DPC/ISRs poderão ser um fator que causa os problemas.
Para obter dados adicionais, amplie o período de tempo que ocorre 100 ms antes que vários eventos de problema sejam exibidos. Se uma atividade significativa de DPC/ISR for exibida em um ou mais processadores na região de 100 ms antes da ocorrência dos eventos do problema, você poderá concluir que os eventos do problema foram causados pela atividade DPC/IRS.
Para determinar se a interferência DPC/ISR está causando atrasos, amplie uma região que mostre um thread em execução. Anote a CPU ou CPUs nas quais esse thread está sendo executado.
No gráfico DPC/ISR, aplique a predefinição DPC/ISR Duration by CPU e exiba a atividade DPC/ISR nas CPUs relevantes nesse intervalo de tempo.
A Figura 47 Eventos de Problema e Atividade DPC/ISR mostra que o thread 864 de iexplore.exe é relevante para a atividade afetada. O thread 864 está no estado Running na CPU2 por 10,65% do intervalo de tempo em exibição. No entanto, o gráfico DPC/ISR mostra que a CPU2 estava ocupada executando DPC/ISRs por 10% desse tempo.
Observação A maioria dos DPC/ISRs não tem um impacto tão alto quanto o mostrado neste exemplo.
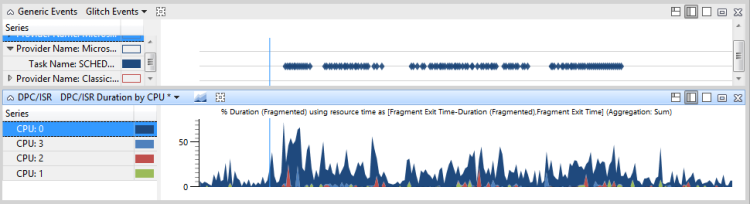
Figura 47 Eventos de problema e atividade DPC/ISR
Na Figura 48 DPC/ISR não relacionado a eventos de problema, os DPC/ISRs não estão relacionados a problemas de desempenho:
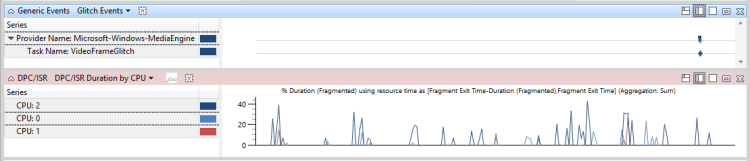
Figura 48 DPC/ISR não relacionado a eventos de problema
Na Figura 49 Atraso causado por interferência DPC/ISR, os DPC/ISRs são mostrados como causadores de problemas de desempenho:
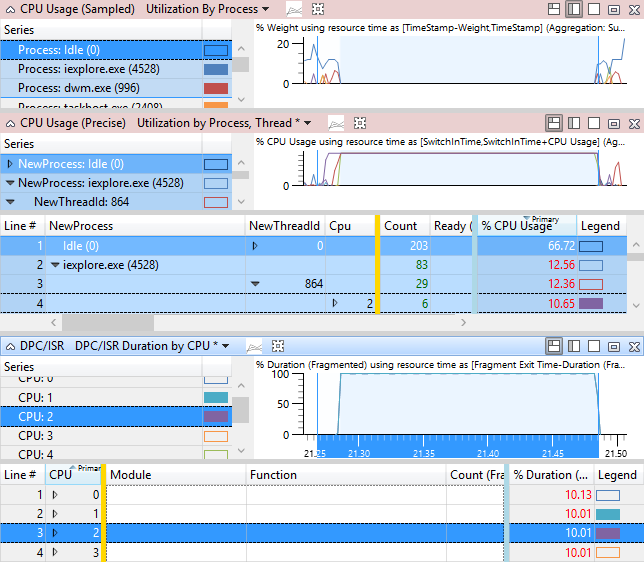
Figura 49 Atraso causado por interferência DPC/ISR
Investigação
Depois de determinar que os DPCs/ISRs estão relacionados a problemas ou atrasos, você deve determinar quais DPCs/ISRs específicos estão envolvidos e por que eles ocorrem com frequência ou são executados por um período de tempo excessivo.
Técnica: Revisar um problema de DPC/ISR relatado pela avaliação
Em problemas de DPC/ISR relatados pela avaliação, você pode expandir o problema que exibe os principais processos que são preemptados pelo DPC ou ISR. Expanda a pilha para exibir a atividade DPC para o processo mais relacionado à atividade afetada, conforme mostrado em expandir a pilha para entender o que o DPC estava fazendo. A Figura 50 Pilha DPC expandida mostra a pilha expandida:
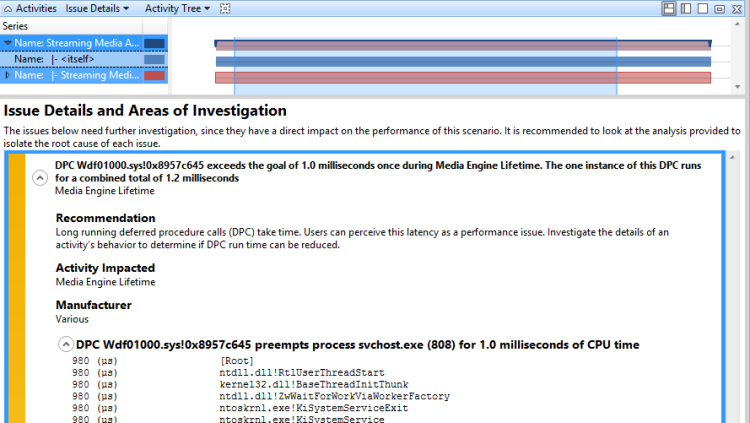
Figura 50 Pilha DPC expandida
Técnica: Encontre os DPCs/ISRs de maior duração e revise as pilhas
Se uma avaliação não relatar que o DPC/ISR é um problema, você poderá usar os gráficos DPC/ISR e Uso da CPU (Amostrado) para obter informações de pilha para os DPCs mais relevantes. Recomendamos que você encontre um DPC/ISR de interesse, observe seu módulo e função e, em seguida, encontre os exemplos no gráfico Uso da CPU (Amostrado) para obter informações completas da pilha.
Encontre os DPCs/ISRs de maior duração e revise as pilhas
Amplie o intervalo de interesse.
No gráfico DPC/ISR, selecione a predefinição DPC/ISR Duration by Module, Function.
Se os símbolos forem carregados, os eventos DPC/ISR serão classificados por duração total e, em seguida, divididos por Módulo e Função. As linhas superiores da lista contêm os eventos DPC/ISR que provavelmente causaram os problemas de evento. Anote os nomes dos módulos e das funções.
No gráfico Uso da CPU (Amostrado), selecione a predefinição Utilização por Processo . Por padrão, essa predefinição oculta a atividade DPC/ISR.
Abra o Editor de Exibição e clique em Avançado.
Na guia Filtro , altere a configuração Ocultar linhas que correspondem ao filtro para Manter linhas que correspondem ao filtro. Isso permitirá que as atividades DPC/ISR sejam exibidas.
Remova a coluna Processo e adicione a coluna Pilha para exibir DPCs/ISRs classificados por pilha.
Desmarque a seleção de linha atual.
Clique com o botão direito do mouse em uma célula na coluna Pilha e clique em Localizar nesta coluna.
Insira um módulo e uma função que você anotou na Etapa 2 deste procedimento.
Marque Adicionar à seleção atual e clique em Localizar tudo para selecionar todas as instâncias da função.
Depois que todas as linhas forem selecionadas, clique com o botão direito do mouse e clique em Borboleta/Exibir Receptores.
Essa exibição mostra as atividades dessa função específica, classificadas por duração total. A exibição é semelhante a uma exibição de pilhas na exibição detalhada de um problema relatado pela avaliação. A coluna Peso aproxima o tempo inclusivo gasto por cada função na pilha, em milissegundos.
Essa exibição é mostrada na Figura 51 Receptores de um DPC classificados por duração aproximada:

Figura 51 Receptores de um DPC classificados por duração aproximada
Técnica: Revisar DPCs/ISRs de longa duração
A duração total dos DPCs/ISRs é importante, mas os DPCs/ISRs individuais de longa duração têm maior probabilidade de causar atrasos. No gráfico DPC/ISR, a coluna Duração Inclusiva (ms), classificada em ordem decrescente, exibe as durações máximas de DPC/ISRs individuais. Os DPCs/ISRs longos predefinidos disponíveis em alguns perfis de avaliação permitem filtrar essa exibição para exibir apenas DPCs/ISRs que têm uma duração inclusiva maior que 1 ms.
Observação Se essa predefinição não estiver disponível, você poderá abrir a seção Editor de Exibição, Avançado , para adicionar um filtro.
Resolução
A atividade DPC/ISR geralmente reflete um problema de hardware ou software que deve ser corrigido no nível do hardware ou do componente. Em um nível de configuração, você pode substituir o hardware ou atualizar o driver relacionado para uma versão fixa. Em um nível de componente, o hardware e os drivers devem seguir as práticas recomendadas para DPCs/ISRs do MSDN e devem usar DPCs threaded quando possível. Os DPCs encadeados não são executados no nível de expedição em edições de cliente do Windows. Para obter mais informações sobre as práticas recomendadas para DPCs/ISRs, consulte Diretrizes sobre comportamento de ISR e DPC e Introdução a DPCs encadeados.
Tópicos relacionados
Introdução aos DPCs encadeados
Gerenciamento de energia e ACPI - Suporte a arquitetura e driver
PPM no Windows Vista e no Windows Server 2008
Agendamento, contexto de thread e IRQL