Ter um problema com nós sendo removidos da associação de cluster de failover ativo
Este artigo apresenta como resolver os problemas nos quais os nós são aleatoriamente removidos da associação de cluster de failover ativo.
Sintomas
Quando o problema ocorre, você está vendo eventos como este registrado no log de eventos do sistema:
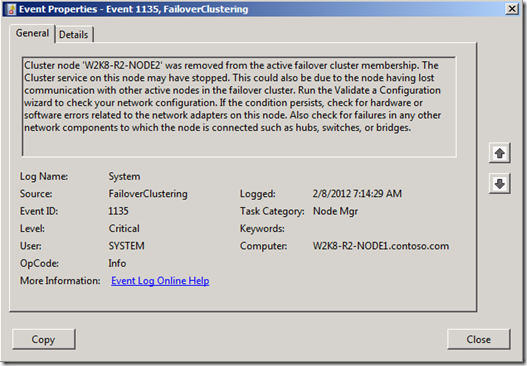
Esse evento é registrado em todos os nós do cluster, exceto no nó que foi removido. O motivo desse evento é porque um dos nós no Cluster marcou esse nó como inativo. Em seguida, ele notifica todos os outros nós do evento. Quando os nós são notificados, eles descontinuam e derrubam suas conexões de pulsação com o nó derrubado.
O que fez com que o nó fosse marcado como inoperante
Todos os nós em um Cluster de Failover do Windows Server se comunicam entre si pelas redes definidas para permitir a comunicação de rede de cluster nessa rede. Os nós enviam pacotes de pulsação por essas redes para todos os outros nós. Esses pacotes devem ser recebidos pelos outros nós e, em seguida, uma resposta é enviada de volta. Cada nó no Cluster tem suas próprias pulsações que serão monitoradas para garantir que a rede esteja ativa e os outros nós estejam ativos. O exemplo a seguir deve ajudar a esclarecer esse comportamento:
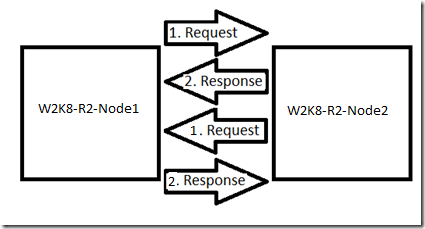
Se qualquer um desses pacotes não for retornado, a pulsação específica será considerada com falha. Por exemplo, W2K8-R2-NODE2 envia uma solicitação e recebe uma resposta de W2K8-R2-NODE1 para um pacote de pulsação, então determina que a rede e o nó estão em atividade. Se W2K8-R2-NODE1 enviar uma solicitação para W2K8-R2-NODE2 e W2K8-R2-NODE1 não obtiver a resposta, ela será considerada uma pulsação perdida e W2K8-R2-NODE1 a acompanhará. Essa resposta perdida pode fazer com que W2K8-R2-NODE1 mostre a rede como inativa até que outra solicitação de pulsação seja recebida.
Por padrão, os nós de cluster têm um limite de cinco falhas em 5 segundos antes que a conexão seja marcada como inativa. Portanto, se W2K8-R2-NODE1 não receber a resposta cinco vezes no período de tempo, ele considerará que a rota específica para W2K8-R2-NODE2 está inativa. Se outras rotas ainda forem consideradas ativas, W2K8-R2-NODE2 permanecerá como um membro ativo.
Se todas as rotas estiverem marcadas para W2K8-R2-NODE2, ele será removido da associação de cluster de failover ativo e o Evento 1135 que você vê na primeira seção será registrado. No W2K8-R2-NODE2, o Serviço de Cluster será encerrado e reiniciado para que ele possa tentar reencontrar o Cluster.
Para obter mais informações sobre como lidamos com rotas específicas desativadas com três ou mais nós, consulte o blog Redes de Cluster "Particionado" que foi escrito por Jeff Hughes.
Agora que sabemos como o processo de pulsação funciona, quais são algumas das causas conhecidas para o processo falhar
Falhas reais de hardware de rede. Se o pacote for perdido no fio em algum lugar entre os nós, as pulsações falharão. Um rastreamento de rede de ambos os nós envolvidos revelará isso.
O perfil para suas conexões de rede pode estar saltando de Domínio para Público e, novamente, de volta para Domínio. Durante a transição dessas alterações, a E/S da rede pode ser bloqueada. Você pode verificar se esse é o caso examinando o log operacional do Perfil de Rede. Você pode encontrar esse log abrindo o Visualizador de Eventos e navegando até Logs de Aplicativos e Serviços\Microsoft\Windows\NetworkProfile\Operational. Examine os eventos neste log no nó que foi mencionado na ID do Evento 1135 e veja se o perfil estava sendo alterado neste momento. Em caso afirmativo, consulte O perfil do local de rede muda de "Domínio" para "Público" no Windows 7 ou no Windows Server 2008 R2.
Você tem o IPv6 habilitado nos servidores, mas tem as duas regras a seguir desabilitadas para Entrada e Saída no Firewall do Windows:
- Rede principal – Anúncio de descoberta de vizinhos
- Rede principal – Solicitação de descoberta de vizinhos
O software antivírus também pode estar interferindo nesse processo. Se você suspeitar disso, teste desabilitar ou desinstalar o software. Faça isso por sua conta e risco, porque você está desprotegido contra vírus neste momento.
A latência na rede também pode causar problemas. Os pacotes podem não ser perdidos entre os nós, mas podem não chegar aos nós com rapidez suficiente antes que o período de tempo limite expire.
IPv6 é o protocolo padrão que o Clustering de Failover usará para suas pulsações. A pulsação em si é um pacote de rede unicast UDP que se comunica pela Porta 3343. Se houver comutadores, firewalls ou roteadores não configurados corretamente para permitir esse tráfego, você poderá enfrentar problemas como este.
As atualizações de política de segurança do IPsec também podem causar esse problema. O problema específico é que, durante uma atualização de política de grupo IPSec, todas as Associações de Segurança IPsec (SAs) são interrompidas pelo Firewall do Windows com WFAS (Segurança Avançada). Enquanto isso está acontecendo, toda a conectividade de rede é bloqueada. Ao renegociar as Associações de Segurança, se houver atrasos na execução da autenticação com o Active Directory, esses atrasos (em que toda a comunicação de rede é bloqueada) também impedirão a passagem de pulsações do cluster e farão com que o monitoramento da integridade do cluster detecte nós como inativos se eles não responderem dentro do limite de 5 segundos.
Drivers de placa de rede e/ou firmware antigos ou desatualizados. Às vezes, uma simples configuração incorreta da placa de rede ou do switch também pode causar perda de heartbeats.
Placas de rede modernas e placas de rede virtuais podem estar enfrentando perda de pacotes. Isso pode ser rastreado abrindo o Monitor de Desempenho e adicionando o contador "Interface de Rede\Pacotes Recebidos Descartados". Esse contador é cumulativo e só aumenta até que o servidor seja reinicializado. Ver um grande número de pacotes descartados aqui pode ser um sinal de que os buffers de recebimento na placa de rede estão muito baixos ou que o servidor está funcionando lentamente e não consegue lidar com o tráfego de entrada. Cada fabricante de cartão de rede escolhe se deseja expor essas configurações nas propriedades do cartão de rede, portanto, você precisa consultar o site do fabricante para saber como aumentar esses valores e os valores recomendados devem ser usados. Se você estiver executando no VMware, o blog a seguir fala sobre isso com um pouco mais de detalhes, incluindo como saber se esse é o problema, além de apontar para o artigo da VMware sobre as configurações a serem alteradas.
Nós sendo removidos da associação do Cluster de Failover no VMware ESX
Esses são os motivos mais comuns pelos quais esses eventos são registrados, mas também pode haver outras razões. O objetivo deste blog era fornecer-lhe algumas informações sobre o processo e também dar ideias do que procurar. Alguns aumentarão os valores a seguir para seus valores máximos para tentar fazer com que esse problema pare.
| Parâmetro | Padrão | Intervalo |
|---|---|---|
| SameSubnetDelay | 1000 milissegundos | 250 a 2000 milissegundos |
| CrossSubnetDelay | 1000 milissegundos | 250 a 4000 milissegundos |
| SameSubnetThreshold | 5 | 3 – 10 |
| CrossSubnetThreshold | 5 | 3 – 10 |
Aumentar esses valores ao máximo pode fazer com que o evento e a remoção do nó desapareçam, apenas mascara o problema. Não conserta nada. A melhor coisa a fazer é descobrir a causa raiz das falhas de batimentos cardíacos e corrigi-la. A única necessidade real de aumentar esses valores é em um cenário de vários sites em que os nós residem em locais diferentes e a latência da rede não pode ser superada.