Solucionar problemas de desempenho de UPDATE com planos estreitos e largos no SQL Server
Aplica-se a: SQL Server
Uma UPDATE declaração pode ser mais rápida em alguns casos e mais lenta em outros. Há muitos fatores que podem levar a essa variação, incluindo o número de linhas atualizadas e o uso de recursos no sistema (bloqueio, CPU, memória ou E/S). Este artigo abordará um motivo específico para a variação: a escolha do plano de consulta feita pelo SQL Server.
O que são planos estreitos e largos?
Quando você executa uma UPDATE instrução em uma coluna de índice clusterizado, o SQL Server atualiza não apenas o índice clusterizado em si, mas também todos os índices não clusterizados, pois os índices não clusterizados contêm a chave de índice clusterizado.
O SQL Server tem duas opções para fazer a atualização:
Plano restrito: faça a atualização do índice não clusterizado junto com a atualização da chave do índice clusterizado. Essa abordagem direta é fácil de entender; Atualize o índice clusterizado e, em seguida, atualize todos os índices não clusterizados ao mesmo tempo. O SQL Server atualizará uma linha e passará para a próxima até que todas sejam concluídas. Essa abordagem é chamada de atualização de plano restrito ou atualização por linha. No entanto, essa operação é relativamente cara porque a ordem dos dados de índice não clusterizados que serão atualizados pode não estar na ordem dos dados de índice clusterizados. Se muitas páginas de índice estiverem envolvidas na atualização, quando os dados estiverem no disco, poderá ocorrer um grande número de solicitações de E/S aleatórias.
Plano amplo: para otimizar o desempenho e reduzir a E/S aleatória, o SQL Server pode escolher um plano amplo. Ele não faz com que os índices não clusterizados sejam atualizados junto com a atualização do índice clusterizado juntos. Em vez disso, ele classifica todos os dados de índice não clusterizados na memória primeiro e, em seguida, atualiza todos os índices nessa ordem. Essa abordagem é chamada de plano amplo (também chamado de atualização por índice).
Aqui está uma captura de tela de planos estreitos e largos:

Quando o SQL Server escolhe um plano amplo?
Dois critérios devem ser atendidos para que o SQL Server escolha um plano amplo:
- O número de linhas afetadas é maior que 250.
- O tamanho do nível folha dos índices não clusterizados (contagem de páginas de índice * 8 KB) é pelo menos 1/1000 da configuração de memória máxima do servidor.
Como funcionam os planos estreitos e largos?
Para entender como os planos estreitos e largos funcionam, siga estas etapas no seguinte ambiente:
- SQL Server 2019 CU11
- Memória máxima do servidor = 1.500 MB
Execute o script a seguir para criar uma tabela
mytable1com 41.501 linhas, um índice clusterizado na colunac1e cinco índices não clusterizados no restante das colunas, respectivamente.CREATE TABLE mytable1(c1 INT,c2 CHAR(30),c3 CHAR(20),c4 CHAR(30),c5 CHAR(30)) GO WITH cte AS ( SELECT ROW_NUMBER() OVER(ORDER BY c1.object_id) id FROM sys.columns CROSS JOIN sys.columns c1 ) INSERT mytable1 SELECT TOP 41000 id,REPLICATE('a',30),REPLICATE('a',20),REPLICATE('a',30),REPLICATE('a',30) FROM cte GO INSERT mytable1 SELECT TOP 250 50000,c2,c3,c4,c5 FROM mytable1 GO INSERT mytable1 SELECT TOP 251 50001,c2,c3,c4,c5 FROM mytable1 GO CREATE CLUSTERED INDEX ic1 ON mytable1(c1) CREATE INDEX ic2 ON mytable1(c2) CREATE INDEX ic3 ON mytable1(c3) CREATE INDEX ic4 ON mytable1(c4) CREATE INDEX ic5 ON mytable1(c5)Execute as três instruções T-SQL
UPDATEa seguir e compare os planos de consulta:UPDATE mytable1 SET c1=c1 WHERE c1=1 OPTION(RECOMPILE)- uma linha é atualizadaUPDATE mytable1 SET c1=c1 WHERE c1=50000 OPTION(RECOMPILE)- 250 linhas são atualizadas.UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE)- 251 linhas são atualizadas.
Examine os resultados com base no primeiro critério (o limite do número afetado de linhas é 250).
A captura de tela a seguir mostra os resultados com base no primeiro critério:

Como esperado, o otimizador de consulta escolhe um plano restrito para as duas primeiras consultas porque o número de linhas afetadas é menor que 250. Um plano amplo é usado para a terceira consulta porque a contagem de linhas afetadas é 251, que é maior que 250.
Examine os resultados com base no segundo critério (a memória do tamanho do índice folha é pelo menos 1/1000 da configuração de memória máxima do servidor).
A captura de tela a seguir mostra os resultados com base no segundo critério:
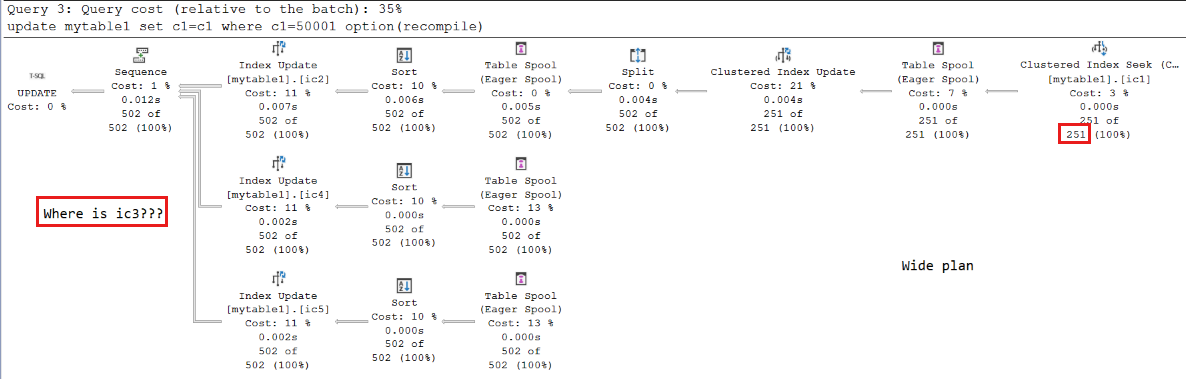
Um plano amplo é selecionado para a terceira
UPDATEconsulta. Mas o índiceic3(na colunac3) não é visto no plano. O problema ocorre porque o segundo critério não é atendido - tamanho do índice de páginas folha em comparação com a configuração de memória máxima do servidor.O tipo de dados da coluna , e é , enquanto o tipo de dados da coluna
c3échar(20).char(30)c4c4c2O tamanho de cada linha de índiceic3é menor do que outras, portanto, o número de páginas folha é menor do que outras.Com a ajuda da função de gerenciamento dinâmico (DMF),
sys.dm_db_database_page_allocationsvocê pode calcular o número de páginas para cada índice. Para osic2índices ,ic4, eic5, cada índice tem 214 páginas, e 209 delas são páginas folha (os resultados podem variar um pouco). A memória consumida pelas páginas folha é de 209 x 8 = 1.672 KB. Portanto, a proporção é 1672/(1500 x 1024) = 0,00108854101, que é maior que 1/1000. No entanto, oic3único tem 161 páginas; 159 delas são páginas folhas. A proporção é 159 x 8/(1500 x 1024) = 0,000828125, que é menor que 1/1000 (0,001).Se você inserir mais linhas ou reduzir a memória máxima do servidor para atender ao critério, o plano será alterado. Para tornar o tamanho do nível folha do índice maior que 1/1000, você pode diminuir a configuração máxima de memória do servidor um pouco para 1.200 executando os seguintes comandos:
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'max server memory', 1200; GO RECONFIGURE GO UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE) --251 rows are updated.Neste caso, 159 x 8/(1200 x 1024) = 0,00103515625 > 1/1000. Após essa alteração, o
ic3aparece no plano.Para obter mais informações sobre
show advanced optionso , consulte Usar Transact-SQL.A captura de tela a seguir mostra que o plano amplo usa todos os índices quando o limite de memória é atingido:




Um plano amplo é mais rápido do que um plano estreito?
A resposta é que depende se os dados e as páginas de índice estão armazenados em cache no buffer pool ou não.
Os dados são armazenados em cache no pool de buffers
Se os dados já estiverem no pool de buffers, a consulta com o plano amplo não oferecerá necessariamente benefícios extras de desempenho em comparação com planos estreitos porque o plano amplo foi projetado para melhorar o desempenho de E/S (leituras físicas, não leituras lógicas).
Para testar se um plano amplo é mais rápido do que um plano estreito quando os dados estão em um buffer pool, siga estas etapas no seguinte ambiente:
SQL Server 2019 CU11
Memória máxima do servidor: 30.000 MB
O tamanho dos dados é de 64 MB, enquanto o tamanho do índice é de cerca de 127 MB.
Os arquivos de banco de dados estão em dois discos físicos diferentes:
- I:\sql19\dbWideplan.mdf
- H:\sql19\dbWideplan.ldf
Crie outra tabela,
mytable2, executando os seguintes comandos:CREATE TABLE mytable2(C1 INT,C2 INT,C3 INT,C4 INT,C5 INT) GO CREATE CLUSTERED INDEX IC1 ON mytable2(C1) CREATE INDEX IC2 ON mytable2(C2) CREATE INDEX IC3 ON mytable2(C3) CREATE INDEX IC4 ON mytable2(C4) CREATE INDEX IC5 ON mytable2(C5) GO DECLARE @N INT=1 WHILE @N<1000000 BEGIN DECLARE @N1 INT=RAND()*4500 DECLARE @N2 INT=RAND()*100000 DECLARE @N3 INT=RAND()*100000 DECLARE @N4 INT=RAND()*100000 DECLARE @N5 INT=RAND()*100000 INSERT mytable2 VALUES(@N1,@N2,@N3,@N4,@N5) SET @N+=1 END GO UPDATE STATISTICS mytable2 WITH FULLSCANExecute as duas consultas a seguir para comparar os planos de consulta:
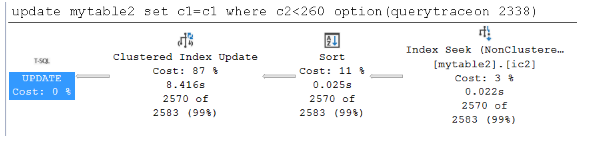
update mytable2 set c1=c1 where c2<260 option(querytraceon 8790) --trace flag 8790 will force Wide plan update mytable2 set c1=c1 where c2<260 option(querytraceon 2338) --trace flag 2338 will force Narrow planPara obter mais informações, consulte o sinalizador de rastreamento 8790 e o sinalizador de rastreamento 2338.
A consulta com o plano amplo leva 0,136 segundos, enquanto a consulta com o plano estreito leva apenas 0,112 segundos. As duas durações são muito próximas e a atualização por índice (plano amplo) é menos benéfica porque os dados já estão no buffer antes da execução da
UPDATEinstrução.A captura de tela a seguir mostra planos largos e estreitos quando os dados são armazenados em cache no pool de buffers:


Os dados não são armazenados em cache no pool de buffers
Para testar se um plano amplo é mais rápido do que um plano restrito quando os dados não estão no pool de buffers, execute as seguintes consultas:
Observação
Ao fazer o teste, verifique se a sua é a única carga de trabalho no SQL Server e se os discos são dedicados ao SQL Server.
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 seconds
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 8790) --force Wide plan
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 SECONDS
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 2338) --force Narrow plan
A consulta com um plano amplo leva 3,554 segundos, enquanto a consulta com um plano estreito leva 6,701 segundos. A consulta de plano amplo é executada mais rápido desta vez.
A captura de tela a seguir mostra o plano amplo quando os dados não são armazenados em cache no pool de buffers:

A captura de tela a seguir mostra o plano estreito quando os dados não são armazenados em cache no pool de buffers:
Uma consulta de plano amplo é sempre mais rápida do que um plano de consulta restrita quando os dados não estão no buffer?
A resposta é "nem sempre". Para testar se a consulta de plano amplo é sempre mais rápida do que o plano de consulta restrita quando os dados não estão no buffer, siga estas etapas:
Crie outra tabela,
mytable2, executando os seguintes comandos:SELECT c1,c1 AS c2,c1 AS C3,c1 AS c4,c1 AS C5 INTO mytable3 FROM mytable2 GO CREATE CLUSTERED INDEX IC1 ON mytable3(C1) CREATE INDEX IC2 ON mytable3(C2) CREATE INDEX IC3 ON mytable3(C3) CREATE INDEX IC4 ON mytable3(C4) CREATE INDEX IC5 ON mytable3(C5) GOO
mytable3é o mesmo quemytable2, exceto pelos dados.mytable3tem todas as cinco colunas com o mesmo valor, o que faz com que a ordem dos índices não clusterizados siga a ordem do índice clusterizado. Essa classificação dos dados minimizará a vantagem do plano amplo.Execute os seguintes comandos para comparar os planos de consulta:
CHECKPOINT GO DBCC DROPCLEANBUFFERS go UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 8790) --tf 8790 will force Wide plan CHECKPOINT GO DBCC DROPCLEANBUFFERS GO UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 2338) --tf 2338 will force Narrow planA duração de ambas as consultas é reduzida significativamente! O plano amplo leva 0,304 segundos, o que é um pouco mais lento do que o plano estreito desta vez.
A captura de tela a seguir mostra a comparação do desempenho quando largo e estreito são usados:


Cenários em que os planos amplos são aplicados
Aqui estão os outros cenários em que os planos amplos também são aplicados:
A coluna de índice clusterizado tem uma chave exclusiva ou primária e várias linhas são atualizadas
Aqui está um exemplo para reproduzir o cenário:
CREATE TABLE mytable4(c1 INT primary key,c2 INT,c3 INT,c4 INT)
GO
CREATE INDEX ic2 ON mytable4(c2)
CREATE INDEX ic3 ON mytable4(c3)
CREATE INDEX ic4 ON mytable4(c4)
GO
INSERT mytable4 VALUES(0,0,0,0)
INSERT mytable4 VALUES(1,1,1,1)
A captura de tela a seguir mostra que o plano amplo é usado quando o índice de cluster tem uma chave exclusiva:

Para obter mais detalhes, examine Mantendo índices exclusivos.
A coluna de índice do cluster é especificada no esquema de partição
Aqui está um exemplo para reproduzir o cenário:
CREATE TABLE mytable5(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS1')
DROP PARTITION SCHEME PS1
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF1')
DROP PARTITION FUNCTION PF1
GO
CREATE PARTITION FUNCTION PF1(INT) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS1 AS
PARTITION PF1 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable5(c1) ON PS1(c1)
CREATE INDEX c2 ON mytable5(c2)
CREATE INDEX c3 ON mytable5(c3)
CREATE INDEX c4 ON mytable5(c4)
GO
UPDATE mytable5 SET c1=c1 WHERE c1=1
A captura de tela a seguir mostra que o plano largo é usado quando há uma coluna clusterizada no esquema de partição:

A coluna de índice clusterizado não faz parte do esquema de partição e a coluna do esquema de partição é atualizada
Aqui está um exemplo para reproduzir o cenário:
CREATE TABLE mytable6(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS2')
DROP PARTITION SCHEME PS2
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF2')
DROP PARTITION FUNCTION PF2
GO
CREATE PARTITION FUNCTION PF2(int) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS2 AS
PARTITION PF2 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable6(c1) ON PS2(c2) --on c2 column
CREATE INDEX c3 ON mytable6(c3)
CREATE INDEX c4 ON mytable6(c4)
A captura de tela a seguir mostra que o plano amplo é usado quando a coluna de esquema de partição é atualizada:

Conclusão
O SQL Server escolhe uma atualização de plano amplo quando os seguintes critérios são atendidos ao mesmo tempo:
- O número afetado de linhas é maior que 250.
- A memória do índice folha é pelo menos 1/1000 da configuração de memória máxima do servidor.
Os planos amplos aumentam o desempenho às custas do consumo de memória extra.
Se o plano de consulta esperado não for usado, pode ser devido a estatísticas obsoletas (não relatando o tamanho correto dos dados), configuração máxima de memória do servidor ou outros problemas não relacionados, como planos sensíveis a parâmetros.
A duração das declarações usando um plano amplo depende de
UPDATEvários fatores e, em alguns casos, pode levar mais tempo do que planos estreitos.O sinalizador de rastreamento 8790 forçará um plano amplo; o sinalizador de rastreamento 2338 forçará um plano estreito.