Solução de problemas de enfileiramento de recuperação em um grupo de disponibilidade Always On
Este artigo fornece resoluções para problemas relacionados ao enfileiramento de recuperação.
O que é enfileiramento de recuperação?
As alterações feitas na réplica primária em um banco de dados de grupo de disponibilidade são enviadas a todas as réplicas secundárias definidas no mesmo grupo de disponibilidade. Depois que essas alterações chegam às réplicas secundárias, elas são gravadas primeiro no arquivo de logs de transações do banco de dados do grupo de disponibilidade. Em seguida, o Microsoft SQL Server usa a operação de recuperação ou refazer para atualizar os arquivos de banco de dados.
Se as alterações em um grupo de disponibilidade chegarem e forem protegidas no arquivo de log de transações do banco de dados mais rapidamente do que podem ser recuperadas, uma fila de recuperação será formada. Essa fila é composta por transações de logs de transações protegidas que não foram recuperadas e restauradas no banco de dados.
Sintomas e efeito do enfileiramento de recuperação (refazer)
A consulta de réplicas primárias e secundárias retorna resultados diferentes
As cargas de trabalho somente leitura que consultam réplicas secundárias podem consultar dados obsoletos. Se ocorrer enfileiramento de recuperação, as alterações nos dados no banco de dados de réplica primária poderão não ser refletidas no banco de dados secundário quando você consultar os mesmos dados.
Embora as alterações cheguem ao banco de dados secundário e sejam gravadas no arquivo de log do banco de dados, as alterações não serão consultadas até que sejam recuperadas e restauradas nos arquivos de banco de dados. A operação de recuperação é o que torna essas alterações legíveis.
Para obter mais informações, consulte a seção Latência de dados na réplica secundária de "Diferenças entre os modos de disponibilidade para um grupo de disponibilidade Always On".
O tempo de failover é maior ou o RTO é excedido
O RTO (Recovery Time Objective, objetivo de tempo de recuperação) é o tempo máximo de inatividade do banco de dados que uma organização pode manipular. O RTO também descreve a rapidez com que a organização pode recuperar o acesso ao banco de dados após uma interrupção. Se houver um enfileiramento de recuperação substancial em uma réplica secundária quando ocorrer um failover, a recuperação poderá demorar mais. Após a recuperação, o banco de dados fará a transição para a função primária e representará o estado do banco de dados que existia antes do failover. Um tempo de recuperação mais longo pode atrasar a rapidez com que a produção é retomada após um failover.
Vários recursos de diagnóstico relatam o enfileiramento de recuperação do grupo de disponibilidade
No caso de enfileiramento de recuperação, o painel Always On no SQL Server Management Studio (SSMS) pode relatar um grupo de disponibilidade não íntegro.
Como verificar se há enfileiramento de recuperação (refazer)
A fila de recuperação é uma medida por banco de dados que pode ser verificada usando o painel Always On na réplica primária ou usando a DMV (Exibição de Gerenciamento Dinâmico) sys.dm_hadr_database_replica_states na réplica primária ou secundária. Os contadores do Monitor de Desempenho verificam o enfileiramento de recuperação e a taxa de recuperação. Esses contadores devem ser verificados em relação à réplica secundária.
As próximas seções fornecem métodos para monitorar ativamente a fila de recuperação de banco de dados do grupo de disponibilidade.
Consulta sys.dm_hadr_database_replica_states
A sys.dm_hadr_database_replica_states DMV relata uma linha para cada banco de dados do grupo de disponibilidade. Uma coluna no relatório é redo_queue_size. Esse valor é o tamanho da fila de recuperação medido em kilobytes. Você pode configurar uma consulta semelhante à consulta a seguir para monitorar qualquer tendência no tamanho da fila de recuperação a cada 30 segundos. A consulta é executada na réplica primária. Ele usa o predicado is_local=0 para relatar os dados da réplica secundária, onde redo_queue_size e redo_rate são relevantes.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Aqui está a aparência da saída.

Examinar a fila de recuperação no Painel Always On
Para revisar a fila de recuperação, siga estas etapas:
Abra o Painel Always On no SSMS clicando com o botão direito do mouse em um grupo de disponibilidade no Pesquisador de Objetos do SSMS.
Selecione Mostrar painel.
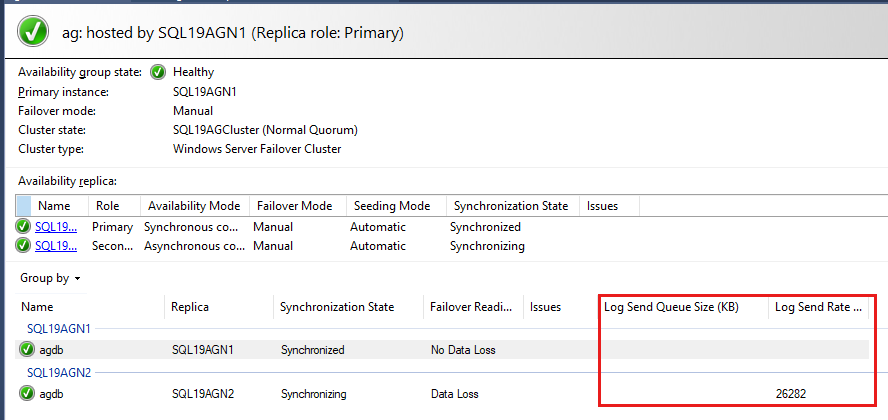
Os bancos de dados do grupo de disponibilidade são listados por último e há alguns dados relatados nos bancos de dados. Embora o Tamanho da Fila de Redo (KB) e a Taxa de Redo (KB/s) não estejam listados por padrão, você pode adicioná-los a esse modo de exibição, conforme mostrado na captura de tela na próxima etapa.
Para adicionar esses contadores, clique com o botão direito do mouse no cabeçalho acima dos relatórios do banco de dados e selecione na lista de colunas disponíveis.
Para adicionar o Tamanho da Fila de Redo (KB) e a Taxa de Redo (KB/s), clique com o botão direito do mouse no cabeçalho mostrado como realçado em vermelho na captura de tela a seguir.
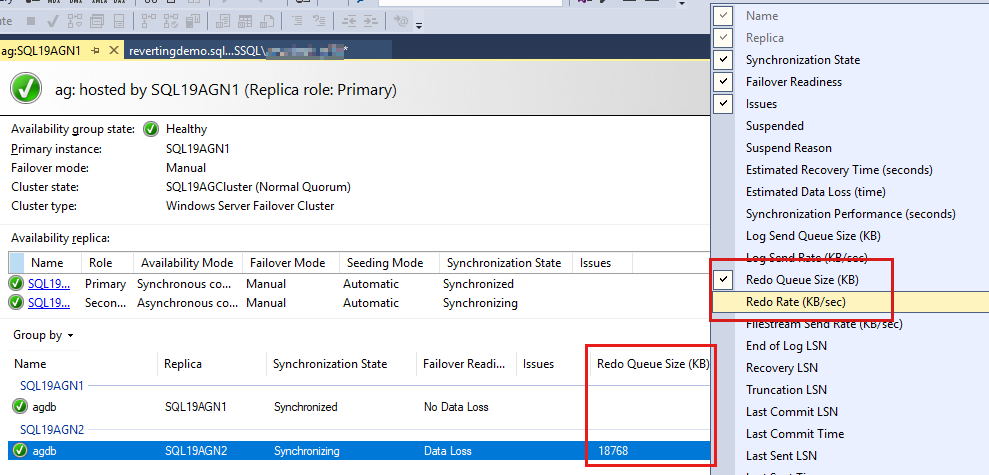
Por padrão, o painel Always On atualiza automaticamente o Tamanho da Fila de Redo (KB) e a Taxa de Redo (KB/s) a cada 60 segundos.


Examinar a fila de recuperação no Monitor de Desempenho
O tamanho da fila de recuperação é exclusivo para cada réplica secundária e banco de dados. Portanto, para examinar a fila de recuperação de um banco de dados de grupo de disponibilidade, siga estas etapas:
Abra o Monitor de Desempenho na réplica secundária.
Selecione o botão Adicionar (contador).
Em Contadores disponíveis, selecione SQLServer:Réplica de Banco de Dados e, em seguida, selecione Fila de Recuperação e Bytes refeitos
Na caixa de listagem Instância , selecione o banco de dados do grupo de disponibilidade que você deseja monitorar para enfileiramento de recuperação.
Selecione Adicionar>OK.
Veja como pode ser o aumento do enfileiramento de recuperação.
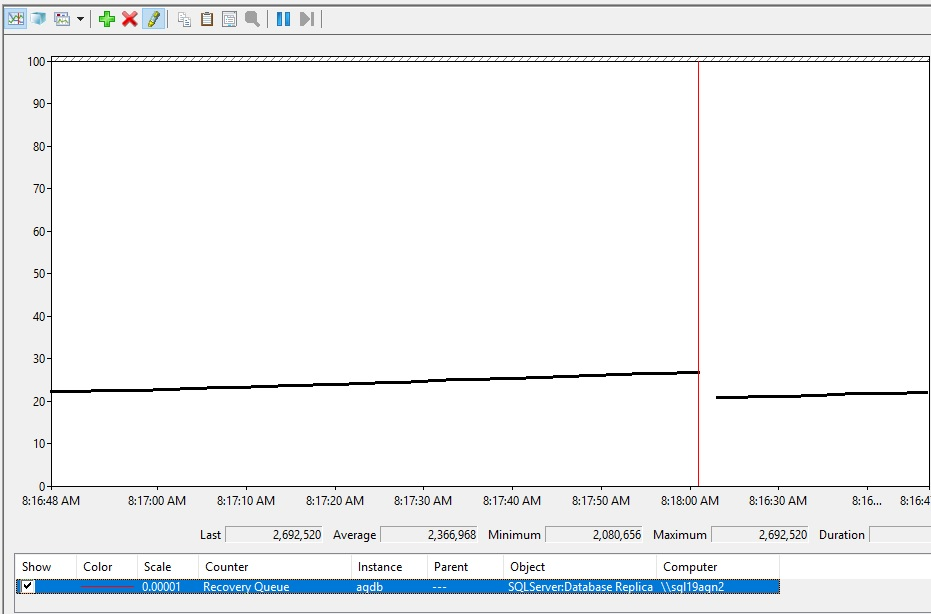

Interpretando Valores de Enfileiramento de Recuperação
Esta seção explica como você pode interpretar os valores relacionados ao enfileiramento de recuperação que você determinou na seção anterior.
Quando o enfileiramento de recuperação é um problema? Quanta fila de recuperação você deve tolerar?
Você pode supor que, se a fila de recuperação estiver relatando um valor de 0, isso significa que nenhum enfileiramento de recuperação está ocorrendo no momento desse relatório. No entanto, quando seu ambiente de produção está ocupado, você deve esperar observar a fila de recuperação relatar com frequência um valor diferente de zero, mesmo em um ambiente AlwaysOn íntegro. Durante a produção típica, você deve esperar observar esse valor flutuar entre 0 e um valor diferente de zero.
Se você observar um aumento no enfileiramento de recuperação ao longo do tempo, uma investigação mais aprofundada será necessária. Essa atividade extra indica que algo mudou. Se você observar um crescimento repentino na fila de recuperação, as seguintes medidas serão úteis para a solução de problemas:
- Taxa de restauração de log (KB/s) (painel AlwaysOn)
- Redo_rate no sys.dm_hadr_database_replica_states do DMV
Obter taxas de linha de base para taxa de refazer
Durante o desempenho íntegro do AlwaysOn, monitore a taxa de restauração em seus bancos de dados de grupo de disponibilidade ocupados. Como eles se parecem durante o horário comercial normalmente movimentado? Quais são essas taxas durante os períodos de manutenção, quando grandes transações (reconstruções de índices, processos de ETL) geram maior taxa de transferência de transações no sistema? Você pode comparar esses valores ao observar o crescimento da fila de recuperação para ajudar a determinar o que mudou. A carga de trabalho pode ser maior do que o normal. Se a taxa de restauração for menor, uma investigação mais aprofundada pode ser necessária para determinar o motivo.
Os volumes de carga de trabalho são importantes
Quando você tem cargas de trabalho grandes (como uma instrução UPDATE em um milhão de linhas, uma recompilação de índice em uma tabela de 1 terabyte ou até mesmo um lote ETL que está inserindo milhões de linhas), você deve esperar ver algum crescimento da fila de recuperação, imediatamente ou ao longo do tempo. Isso é esperado quando um grande número de alterações é feito repentinamente no banco de dados do grupo de disponibilidade.
Como diagnosticar o enfileiramento de recuperação (refazer)
Depois de identificar o enfileiramento de recuperação para um banco de dados de grupo de disponibilidade de réplica secundária específico, conecte-se à réplica secundária e consulte sys.dm_exec_requests para determinar o wait_type e wait_time para threads de recuperação. Aqui está uma consulta que pode ser executada em um loop. Você está procurando uma alta frequência de um ou mais tipos de espera e até mesmo tempos de espera para esses tipos de espera. Aqui está um exemplo de consulta que é executado a cada segundo e relata os tipos de espera e os tempos de espera para o grupo de disponibilidade, "agdb":
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Importante
Para uma saída de tipo de espera significativa, deve-se observar que o enfileiramento de recuperação está aumentando quando você usa um dos métodos descritos anteriormente para monitorar essa condição.
Neste exemplo, alguns tipos de espera relacionados a E/S são relatados (PAGEIOLATCH_UP, PAGEIOATCH_EX). Monitore para verificar se esses tipos de espera continuam a ter os maiores wait_times valores, conforme relatado na próxima coluna.

Tipos de espera de refazer do SQL Server
Quando um tipo de espera for identificado, examine o seguinte artigo SQL Server 2016/2017: Modelo e desempenho de restauração de réplica secundária do grupo de disponibilidade – Microsoft Tech Community como uma referência cruzada para tipos de espera comuns que causam enfileiramento de recuperação e para obter ajuda para resolver o problema.
Threads de restauração bloqueados em servidores de relatórios secundários
Se sua solução direcionar relatórios (consultas) em bancos de dados de grupos de disponibilidade na réplica secundária, essas consultas somente leitura adquirirão bloqueios de estabilidade de esquema (Sch-S). Esses bloqueios Sch-S podem impedir que threads de restauração adquiram bloqueios Sch-M (modificação de esquema) (também conhecidos como "bloqueios de modificação de esquema" ou LCK_M_SCH_M) para fazer alterações DDL (linguagem de definição de dados), como ALTER TABLE ou ALTER INDEX. Um thread de restauração bloqueado não pode aplicar registros de log até que seja desbloqueado. Isso pode causar enfileiramento de recuperação.
Para verificar se há evidências históricas de uma refazer bloqueada, abra os arquivos de rastreamento do AlwaysOn_health Xevent na réplica secundária usando o SSMS. lock_redo_blocked Procure eventos.

Use o Monitor de Desempenho para monitorar ativamente o impacto de restauração bloqueada na fila de recuperação. Adicione os contadores SQL Server::D atabase Replica::Redo blocked/sec e SQL Server::D atabase Replica::Recovery Queue . A captura de tela a seguir mostra um ALTER TABLE ALTER COLUMN comando que é executado na réplica primária enquanto uma consulta de execução longa é executada na mesma tabela na réplica secundária. O contador Redo blocked/sec indica que o ALTER TABLE ALTER COLUMN comando foi executado. Enquanto a consulta de execução longa estiver em execução na mesma tabela na réplica secundária, todas as alterações subsequentes na primária causarão um aumento na fila de recuperação.

Monitore o tipo de espera de bloqueio de modificação de esquema que o thread de restauração tenta adquirir. Para fazer isso, use a consulta descrita anteriormente para verificar os tipos de espera relatados para operações de refazer em relação sys.dm_exec_requestsao . Você pode observar o aumento do tempo de espera para o LCK_M_SCH_M bloqueio de refazer em andamento.

Refazer de thread único
O SQL Server introduziu a recuperação paralela para bancos de dados de réplica secundária no Microsoft SQL Server 2016. Se você estiver enfrentando enfileiramento de recuperação ao executar o SQL Microsoft Server 2012 ou o Microsoft SQL Server 2014, poderá atualizar para uma versão posterior do programa para melhorar o desempenho de refazer em seu ambiente de produção.
Uma restauração de thread único pode ocorrer em versões ainda mais avançadas do SQL Server nas quais a arquitetura de recuperação paralela é usada. Nessas versões, uma instância do SQL Server pode usar até 100 threads para uma restauração paralela. Dependendo do número de processadores e bancos de dados do grupo de disponibilidade, os threads de restauração paralelos são alocados até um máximo de 100 threads no total. Se o limite de restauração de 100 threads for atingido, alguns bancos de dados no grupo de disponibilidade receberão um único thread de restauração.
Para determinar se o banco de dados do grupo de disponibilidade está usando a recuperação paralela, conecte-se à réplica secundária e use a consulta a seguir para determinar o número de linhas (threads) que aplicam a recuperação ao banco de dados do grupo de disponibilidade. No exemplo a seguir, se o banco de dados "agdb" for um único thread e seu comando for DB STARTUP, a carga de trabalho de recuperação poderá se beneficiar da recuperação paralela.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

Se você verificar se o banco de dados usa uma restauração de thread único, examine o algoritmo descrito anteriormente para determinar se o SQL Server está excedendo o número de 100 threads de trabalho dedicados à recuperação paralela. Essa condição pode ser o motivo pelo qual o banco de dados "agdb" está usando apenas um único thread para recuperação.
O SQL Server 2022 agora usa um novo algoritmo de recuperação paralela para que os threads de trabalho sejam atribuídos para recuperação paralela com base na carga de trabalho. Isso elimina a chance de que um banco de dados ocupado permaneça em uma recuperação de thread único. Para obter mais informações, consulte a seção Uso de thread por grupos de disponibilidade de "Pré-requisitos, restrições e recomendações para grupos de disponibilidade AlwaysOn".