Solucionar problemas de failover de Grupos de Disponibilidade AlwaysOn
Observação
Para automatizar a análise manual descrita neste artigo, consulte Usar o AGDiag para diagnosticar eventos de integridade do grupo de disponibilidade.
Este artigo fornece etapas de solução de problemas para ajudá-lo a determinar por que o grupo de disponibilidade fez failover.
Efeitos de problemas de integridade ou failover Always On
O Always On implementa o monitoramento de integridade robusto por meio de diferentes mecanismos para garantir a integridade da instância do Microsoft SQL Server que hospeda a réplica primária, o cluster subjacente e a integridade do sistema. A carga de trabalho de produção é interrompida momentaneamente quando um cluster do Windows ou um problema de integridade Always On é identificado.
Quando uma condição de saúde é detectada, geralmente ocorre a seguinte sequência de eventos. Ao longo desta solução de problemas, os eventos de integridade são mencionados em referência aos seguintes eventos:
As réplicas do grupo de disponibilidade e os bancos de dados fazem a transição da função primária para a função de resolução.
Os bancos de dados do grupo de disponibilidade fazem a transição para offline e não estão mais acessíveis.
O Cluster do Windows marca o recurso clusterizado do grupo de disponibilidade como falha.
O Cluster do Windows tenta colocar a função do grupo de disponibilidade online novamente (na réplica do parceiro de failover original ou automático).
A função de grupo de disponibilidade fica online com êxito se for detectada como íntegra pelo monitoramento de integridade do Always On e do Cluster do Windows.
Se for bem-sucedido, as réplicas e os bancos de dados do grupo de disponibilidade farão a transição para a função primária e os bancos de dados do grupo de disponibilidade ficarão online e poderão ser acessados pelo aplicativo.
Os aplicativos não podem acessar os bancos de dados do grupo de disponibilidade
Quando uma condição de integridade é detectada, a réplica do grupo de disponibilidade e os bancos de dados fazem a transição para a função Resolvendo e os bancos de dados do grupo de disponibilidade são colocados offline. Depois que a réplica fica online na função primária (no servidor de réplica original ou no servidor de réplica do parceiro de failover), a réplica e os bancos de dados fazem a transição novamente para online. Enquanto a réplica e os bancos de dados estão sendo resolvidos e offline, todos os aplicativos que tentam acessar esses bancos de dados do grupo de disponibilidade falham e geram uma mensagem de "Erro 983": Unable to access availability database.... Esse erro também será registrado no log de erros do Microsoft SQL Server se o SQL Server estiver configurado para registrar tentativas de logon com falha:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
O período durante o qual o grupo de disponibilidade está na função Resolvendo antes de voltar a ficar online na função primária normalmente dura apenas alguns segundos ou até menos de um segundo.
Identificar e diagnosticar eventos de integridade do grupo de disponibilidade Always On ou failover
1. Identifique as tendências de saúde Always On
Você pode investigar um único evento de integridade Always On ou pode haver uma tendência recente ou contínua de problemas de integridade que estão interrompendo intermitentemente a produção. As perguntas a seguir podem ajudá-lo a restringir e correlacionar as alterações recentes em seu ambiente de produção que podem estar relacionadas a esses problemas de integridade:
- Quando a tendência Always On ou eventos de integridade do cluster começou?
- Os eventos de saúde ocorrem em um determinado dia?
- Os eventos de saúde ocorrem em uma determinada hora do dia?
- Os eventos de saúde ocorrem em um determinado dia ou semana do mês?
Se você detectar uma tendência, verifique a manutenção agendada no sistema (o sistema host em um ambiente virtual), lotes de ETL e outros trabalhos que podem se correlacionar com esses eventos de integridade. Se o sistema for uma máquina virtual, investigue o sistema host em busca de alterações que possivelmente foram introduzidas no momento das interrupções.
Considere cargas de trabalho de produção ad hoc ocupadas que podem se correlacionar com o tempo dos problemas de integridade (por exemplo, quando os usuários fazem logon no sistema pela primeira vez ou depois que os usuários retornam do almoço).
Observação
Este é um bom momento para considerar um plano para coletar dados de desempenho ao longo da semana e do mês. Para entender melhor quando o sistema está mais ocupado, você pode medir os contadores do monitor de desempenho do Windows, como Processor Information::% Processor Time, Memory::Available MBytese MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Examinar o log do cluster
O log do Cluster do Windows é o log mais abrangente a ser usado para identificar o tipo de evento Always On ou de integridade do cluster e também a condição de integridade detectada que causou o evento. Para gerar e abrir o log do cluster, siga estas etapas:
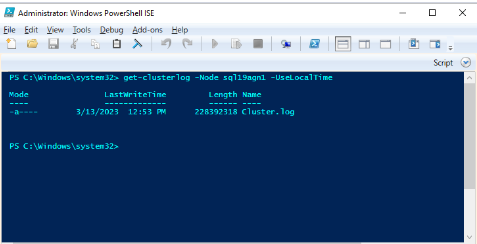
Use o Windows PowerShell para gerar o log do Cluster do Windows no nó do cluster que hospeda a réplica primária no momento do evento de integridade. Por exemplo, execute o seguinte cmdlet em uma janela do PowerShell com privilégios elevados usando 'sql19agn1' como o nome do servidor baseado no SQL Server:
get-clusterlog -Node sql19agn1 -UseLocalTime
Observação
Por padrão, o arquivo de log é criado em %WINDIR%\cluster\reports.
3. Localizar o evento de integridade no log do cluster
O Always On usa vários mecanismos de monitoramento de integridade para monitorar a integridade do grupo de disponibilidade. Além de um evento de integridade do Cluster do Windows (no qual o Cluster do Windows detecta um problema de integridade entre os nós do cluster), o Always On tem quatro tipos diferentes de verificações de integridade:
- O serviço SQL Server não está em execução
- Um tempo limite de concessão do SQL Server
- Um tempo limite de verificação de integridade do SQL Server
- Um problema de integridade interna do SQL Server
Você pode localizar qualquer um desses eventos de integridade específicos do Always On pesquisando no log do cluster a cadeia de caracteres. [hadrag] Resource Alive result 0 Essa cadeia de caracteres é salva no log do cluster quando qualquer um desses eventos é detectado. Por exemplo:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
Você pode usar uma ferramenta para localizar todos os eventos de integridade no log do cluster para que possa gerar um relatório resumido de problemas de integridade do Always On. Isso pode ser útil para identificar tendências cronológicas e determinar se uma determinada condição de saúde Always On é recorrente. A captura de tela a seguir mostra como usar um editor de texto (NotePad++, neste caso) para localizar todas as linhas no log do cluster que contêm a [hadrag] Resource Alive result 0 cadeia de caracteres:

Identificar e resolver o problema de integridade que disparou o failover
Para identificar os problemas de integridade no log de cluster da réplica primária, compare-os com os problemas descritos nas seções a seguir. Os motivos comuns para failover do AG incluem:
- Evento de integridade do cluster
- O serviço SQL Server está inativo (um evento de integridade Always On)
- Tempo limite de concessão (um evento de integridade Always On)
- Tempo limite da verificação de integridade (um evento de integridade Always On)
- Integridade do SQL Server (um evento de integridade Always On)
Eventos de integridade do cluster
O Cluster do Microsoft Windows monitora a integridade dos servidores membros no cluster. Se um problema de integridade for detectado, um servidor membro do cluster poderá ser removido do cluster. Além disso, os recursos de cluster (incluindo a função de grupo de disponibilidade hospedada no servidor membro do cluster removido) serão movidos para a réplica do parceiro de failover do grupo de disponibilidade se ela estiver configurada para failover automático.
Sintomas
Aqui está um exemplo de um evento de integridade do cluster no log do cluster. Para encontrá-lo, você pode pesquisar Lost quorum ou Cluster service has terminated porque pode estar presente durante a alteração ou failover da função do grupo de disponibilidade.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Outra maneira de identificar esse evento é pesquisar o log de eventos do sistema Windows:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Diagnosticar um evento de integridade do cluster
Os erros no log de eventos do Windows (Eventos 1135 e 1177) sugerem que a conectividade de rede é a causa do evento. Esse é o motivo mais comum pelo qual um problema de integridade do cluster é detectado. O exemplo a seguir mostra que outros servidores membros do cluster não puderam se comunicar com esse servidor que hospeda a réplica primária do grupo de disponibilidade e que esse problema disparou a remoção do nó de cluster do cluster:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Você pode pesquisar o log do cluster para obter evidências de uma falha de conexão com o nó. No local no log do cluster em que você encontrou Lost quorum, pesquise de trás para frente por strings como Failed to connect to remote endpoint, unreachablee is broken.
Solução
Certifique-se de que o monitoramento da integridade do cluster seja apropriado para o ambiente do host. Para obter mais informações sobre os grupos de disponibilidade Always On do SQL Server hospedados no Microsoft Azure, consulte Visão geral do Cluster de Failover do Windows Server – SQL Server em VMs do Azure.
Se for necessário, considere entrar em contato com o suporte de alta disponibilidade do Microsoft Windows para abrir um incidente de suporte.
O serviço do SQL Server está inativo: um evento de integridade Always On
O monitoramento de integridade Always On pode detectar se o serviço SQL Server que hospeda a réplica primária do grupo de disponibilidade não está mais em execução.
Sintomas
Aqui está um exemplo do relatório de log do cluster para a função do grupo de disponibilidade 'ag' que indica uma falha porque QueryServiceStatusEx retornou uma ID 0de processo:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Diagnosticar eventos de desligamento do Serviço SQL
Verifique o log de eventos do sistema Windows e o log de erros do SQL Server para um desligamento inesperado do SQL Server.
Se o SQL Server foi desligado por um desligamento do sistema ou um desligamento administrativo, você verá a seguinte entrada no log de erros do SQL Server:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
O log de eventos do sistema Windows mostraria a seguinte entrada de erro:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
O log de eventos do sistema Windows mostra a seguinte entrada de erro se o SQL Server for desligado inesperadamente:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
Verifique o final do log de erros do SQL Server em busca de pistas. Se o log de erros terminar abruptamente, isso significa que ele foi desligado à força. Por exemplo, se o SQL Server foi encerrado usando o Gerenciador de Tarefas, o relatório de erros do SQL Server não revelaria nenhuma informação sobre problemas internos que possam ter causado o desligamento do processo.
Solução
Verifique se os administradores autorizados do banco de dados e do sistema têm acesso ao sistema para minimizar encerramentos inesperados do serviço SQL Server. Depois de examinar os logs de eventos, investigue por que um serviço teve que ser encerrado inesperadamente.
Se um problema de integridade interna do SQL Server fez com que o SQL Server fosse encerrado inesperadamente, pode haver indícios de uma possível exceção fatal (incluindo um arquivo de diagnóstico de despejo de memória sendo gerado) no final do log de erros do SQL. Revise as pistas e tome as medidas necessárias. Se você encontrar um arquivo de despejo, considere entrar em contato com o suporte do Microsoft SQL Server e forneça o log de erros do SQL Server e o conteúdo do arquivo de despejo para uma investigação mais aprofundada.
Tempo limite de concessão: um evento de integridade Always On
O Always On usa um mecanismo de "concessão" para monitorar a integridade do computador no qual o SQL Server está instalado. O tempo limite de concessão padrão é de 20 segundos.
Sintomas
Aqui está um exemplo de saída de um tempo limite de concessão Always On do log do cluster. Você pode pesquisar essas cadeias de caracteres para localizar um tempo limite de concessão no log do cluster.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Para obter mais informações sobre o tempo limite de concessão, consulte a seção Mecanismo de concessão em Mecânica e diretrizes de tempos limite de verificação de concessão, cluster e integridade para grupos de disponibilidade Always On.
Diagnosticar e resolver eventos de tempo limite de concessão Always On
Existem dois problemas principais que podem desencadear um tempo limite de concessão:
Despejo de memória do SQL Server: quando o SQL Server detecta determinados eventos internos de integridade, como uma violação de acesso, uma declaração ou um deadlock do agendador, ele gera um arquivo de despejo de diagnóstico (.mdmp) na pasta \LOG do SQL Server. O processo de geração de um despejo de memória suspende a execução do SQL Server por um breve período. Nesse período, o mecanismo de locação pode detectar a falta de resposta do serviço e acionar a ação. Para obter mais informações, consulte Impacto da geração de despejo.
Um problema de desempenho em todo o sistema: um tempo limite de concessão não indica necessariamente um problema de integridade do SQL Server. Em vez disso, pode indicar um problema de integridade em todo o sistema que também afeta a integridade do servidor baseado em SQL Server.
- Alto uso da CPU no sistema (próximo a 100%).
- Condições de falta de memória - pouca memória virtual e/ou um dos processos está sendo paginado.
- WSFC ficando offline devido à perda de quorum
- Limitação de VM que afeta o desempenho e causa a expiração da concessão.
Solução
Para obter etapas detalhadas de solução de problemas, consulte MSSQLSERVER_19407. Aqui estão os dois problemas mais comuns:
1. SQL Diagnóstico do arquivo de despejo do servidor
O SQL Server pode detectar um problema de integridade interno, como uma violação de acesso, asserção ou agendadores de deadlock. Nessa situação, o programa gera um arquivo de minidespejo (.mdmp) na pasta \LOG do SQL Server do processo do SQL Server para diagnóstico. O processo do SQL Server é congelado por vários segundos enquanto o arquivo de minidespejo é gravado no disco. Durante esse tempo, todos os threads dentro do processo do SQL Server estão em um estado congelado, o que inclui o thread de concessão monitorado pelo monitoramento de integridade Always On. Portanto, o Always On pode detectar um tempo limite de concessão.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Para resolver esse problema, o diagnóstico do arquivo de despejo de memória deve ser examinado quanto à causa raiz. Considere entrar em contato com o suporte do Microsoft SQL Server para fornecer o log de erros do SQL Server e o conteúdo do arquivo de despejo para investigação adicional.
2. Alto uso da CPU ou outro problema de desempenho do sistema
Um tempo limite de concessão indica um problema de desempenho que afeta todo o sistema, incluindo o SQL Server. Para diagnosticar o problema do sistema, o diagnóstico de integridade Always On relata dados do monitor de desempenho no log do cluster e inclui o evento de tempo limite de concessão. Os dados de desempenho abrangem aproximadamente 50 segundos que antecedem o evento de tempo limite de concessão, relatando a utilização da CPU, a memória livre e a latência do disco.
Aqui está um exemplo dos dados de desempenho relatados que mostram um tempo limite de concessão no log do cluster. Neste exemplo de saída, alta utilização geral da CPU que pode estar relacionada ao tempo limite de concessão.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Se os dados de desempenho mostrarem alta utilização da CPU, uma condição de memória baixa ou alta latência de disco no momento de um tempo limite de concessão, comece a coletar dados do Monitor de Desempenho para o dia inteiro na réplica primária para investigar esses sintomas. Ao capturar dados do monitor de desempenho por um período mais longo, você pode identificar melhor os valores de linha de base e pico para esses recursos e monitorar as alterações nesses recursos quando ocorre um tempo limite de concessão. Ao coletar esses dados, considere se há determinadas cargas de trabalho agendadas ou ad hoc no SQL Server que se correlacionam com o tempo desses problemas de recursos e eventos de integridade.
Você também deve capturar contadores que relatam o mesmo uso de recursos do sistema, incluindo o seguinte:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Tempo limite de verificação de integridade: um evento de integridade Always On
O Always On usa um mecanismo de verificação de integridade para monitorar a integridade do SQL Server e a capacidade de aplicativos cliente se conectarem.
Sintomas
Quando uma réplica do grupo de disponibilidade faz a transição para a função primária, o monitoramento de integridade Always On estabelece uma conexão ODBC local com a instância do SQL Server. Enquanto o Always On estiver conectado e monitorando, se o SQL Server não responder pela conexão ODBC dentro do período definido para o tempo limite de verificação de integridade do grupo de disponibilidade (o padrão é 30 segundos), um evento de tempo limite de verificação de integridade será disparado. Nessa situação, o grupo de disponibilidade faz a transição da função primária para a função Resolvendo e inicia o failover, se estiver configurado para fazer isso.
Para obter mais informações sobre tempos limite de verificação de integridade, consulte a seção "Operação de tempo limite de verificação de integridade" em Mecânica e diretrizes de tempos limite de verificação de concessão, cluster e integridade para grupos de disponibilidade Always On.
Aqui está um tempo limite de verificação de integridade Always On, conforme relatado no log do cluster:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Diagnosticar e resolver o evento de tempo limite de verificação de integridade Always On
A seção a seguir ajuda você a examinar os logs do SQL Server em busca de eventos de "trilha de navegação" que você pode encontrar e que se correlacionam com os tempos limite de verificação de integridade Always On detectados e relatados. Os logs que são revisados aqui incluem o log de cluster (onde o tempo limite da verificação de integridade é confirmado), os logs de eventos estendidos e os system_health logs de erros do SQL Server (ambos encontrados na pasta \LOG do SQL Server) e o log de eventos do sistema Windows. Use esses e outros logs para procurar eventos correlacionados que possam ajudá-lo a definir o escopo da causa do tempo limite da verificação de integridade.
1. Verifique se há eventos do agendador não produtivo
O tempo limite de verificação de integridade Always On é frequentemente causado por eventos "não produtivos" no SQL Server. Quando o SQL Server detecta que um thread não foi gerado em um agendador, ele relata que ocorreu um evento de agendador sem rendimento. Se você vir outras tarefas no mesmo agendador que não estão recebendo tempo de CPU, esse é o principal sinal de um agendador que não está produzindo. Esse comportamento pode causar um atraso na execução dessas tarefas e "privar" as cargas de trabalho atribuídas a um determinado agendador de tempo de CPU.
Para verificar se há eventos do agendador não produtivos, siga estas etapas:
Verifique os logs de eventos estendidos do SQL Server
system_healthpara determinar se um evento de agendador não produtivo de algum tipo foi relatado na época do evento de tempo limite de verificação de integridade Always On. Os eventos não produtivos que você pode encontrar incluem o seguinte:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Abra os logs de eventos estendidos de integridade do sistema do SQL Server na réplica primária até o momento do tempo limite da verificação de integridade suspeita.
No SSMS (SQL Server Management Studio), vá para Abrir Arquivo > e selecione Mesclar Arquivos de Eventos Estendidos.
Selecione o botão Adicionar.
Na caixa de diálogo Abrir Arquivo, navegue até os arquivos no diretório \LOG do SQL Server.
Pressione e segure Control e selecione os arquivos cujos nomes começam com
system_health_xxx.xel.Selecione Abrir>OK.
Filtre os resultados. Clique com o botão direito do mouse em um evento na coluna de nome e selecione Filtrar por este valor.
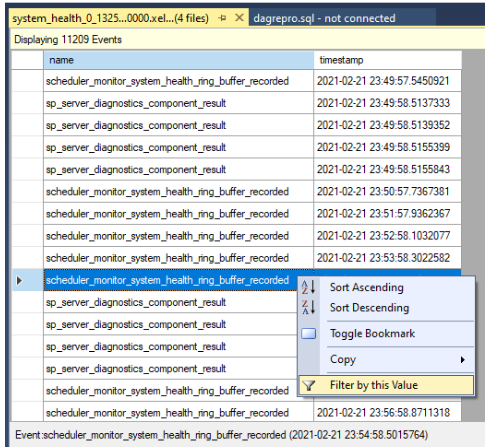
Defina um filtro para classificar linhas nas quais os valores na coluna de nome contêm
yield, conforme mostrado na captura de tela a seguir. Isso retorna todos os tipos de eventos não produtivos que podem ter sido registrados nossystem_healthlogs.
Compare os carimbos de data/hora para ver se houve eventos não produtivos no momento do tempo limite da verificação de integridade. Aqui está o tempo limite da verificação de integridade, conforme relatado no log do cluster:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Você pode ver que houve eventos não produtivos que ocorreram no momento do tempo limite da verificação de integridade.
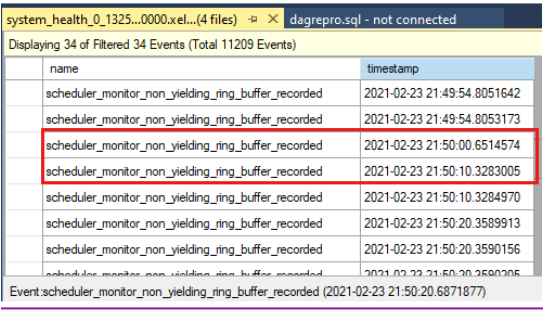
Se forem detectados eventos de não rendimento, verifique a causa do evento de não rendimento. Considere entrar em contato com a equipe de suporte do SQL Server para investigar os eventos de não rendimento.
2. Verifique o log de erros do SQL Server
Verifique o log de erros do SQL Server para eventos correlacionados no momento do tempo limite da verificação de integridade. Esses eventos podem fornecer "migalhas de pão" que sugerem etapas adicionais para definir o escopo da causa raiz dos tempos limite da verificação de integridade.
Por exemplo, a entrada de log a seguir mostra que ocorreu um tempo limite de verificação de integridade no log do cluster:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
No log de erros do SQL Server, segundos após o tempo limite da verificação de integridade, o SQL Server relata que detectou latência de E/S severa:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Examine o log de eventos do sistema para obter possíveis pistas do sistema que possam estar relacionadas ao evento de tempo limite da verificação de integridade. Ao examinar o log de eventos do sistema Windows, você pode encontrar um problema de E/S relatado ao mesmo tempo para o mesmo tempo limite de verificação de integridade:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
Integridade do SQL Server: um evento de integridade Always On
O Always On monitora diferentes tipos de eventos de integridade do SQL Server. Embora hospede uma réplica primária do grupo de disponibilidade, o SQL Server executa continuamente sp_server_diagnostics que relatam a integridade do SQL Server usando componentes diferentes. Quando algum problema de integridade é detectado, sp_server_diagnostics o relata um erro para esse componente específico e envia os resultados de volta para o processo de detecção de integridade Always On. Quando um erro é relatado, a função Grupo de Disponibilidade mostra o estado com falha e o possível failover se o grupo de disponibilidade estiver configurado para fazer isso.
Sintomas
Aqui está um exemplo de um problema de integridade do SQL Server, conforme relatado no sp_server_diagnostics log do cluster. O SQL Server relata um estado de "erro" no componente do sistema para o monitoramento de integridade Always On e o grupo de disponibilidade "contoso-ag" é transferido para um estado de falha.
Observação
Um problema de integridade do SQL Server gera um relatório semelhante ao do tempo limite da verificação de integridade. Ambos os eventos de saúde relatam Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. A distinção para um evento de integridade do SQL Server é que ele relata que o componente do SQL Server foi alterado de "aviso" para "erro".
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Diagnosticar eventos de integridade do SQL Server
O tipo de problema de integridade relatado pela integridade do SQL Server deve ditar a direção da análise da causa raiz.
Por padrão, quando você implanta um grupo de disponibilidade, o FAILURE_CONDITION_LEVEL é definido como três. Isso ativa o monitoramento de alguns, mas não de todos os perfis de integridade do SQL Server. No nível padrão, o Always On dispara um evento de integridade quando o SQL Server produz muitos arquivos de despejo, uma violação de acesso de gravação ou um spinlock órfão. Definir o grupo de disponibilidade até o nível quatro ou cinco expandirá os tipos de problemas de integridade do SQL Server que são monitorados. Para obter mais informações sobre os monitores Always On de integridade do SQL Server, consulte Configurar uma política de failover automático flexível para um grupo de disponibilidade – SQL Server Always On.
Para identificar o problema de integridade específico do Always On, siga estas etapas:
Abra os logs de eventos estendidos de diagnóstico de cluster do SQL Server na réplica primária até o momento em que ocorreu o evento de integridade do SQL Server suspeito.
No SSMS, vá para Abrir Arquivo>e selecione Mesclar Arquivos de Eventos Estendidos.
Selecione Adicionar.
Na caixa de diálogo Abrir Arquivo, navegue até os arquivos no diretório \LOG do SQL Server.
Pressione Control, selecione os arquivos cujos nomes correspondem
<servername>_<instance>_SQLDIAG_xxx.xele selecione Abrir>OK.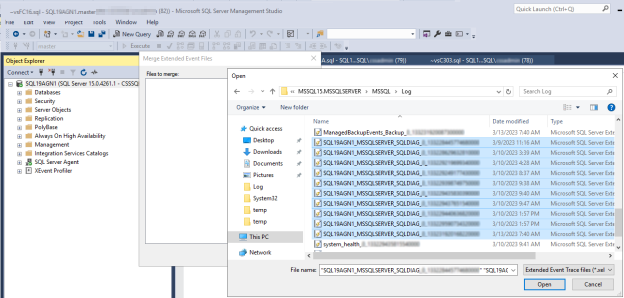
Você verá uma nova janela com guias no SSMS que inclui os eventos estendidos, conforme mostrado na captura de tela a seguir.
Para investigar um problema de integridade do SQL Server, localize o
component_health_resultvalor de cujostate_descvalor éerror. Aqui está um exemplo de um evento de componente do sistema que relatou um erro de volta ao monitoramento de integridade Always On: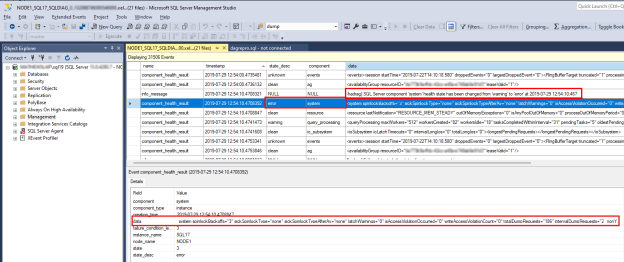
Clique duas vezes na coluna de dados no painel inferior. Isso abre os dados detalhados do componente em um novo painel de janela do SSMS para revisão. Veja como são os dados do componente do sistema:

Observe que os dados 'totalDumprequests=186' indicam que houve muitos eventos de diagnóstico de arquivo de despejo gerados neste SQL Server. Esse é o motivo pelo qual o componente do sistema relatou um estado de erro. Quando o monitoramento de integridade Always On recebe esse estado de erro, ele dispara um evento de integridade do grupo de disponibilidade. Você também pode verificar se nenhuma violação de acesso de gravação ou spinlocks órfãos foram detectados a partir dos dados fornecidos nos dados do componente do sistema.



Solução
Dependendo do tipo de problema que você descobrir, você deve resolvê-lo adequadamente. Como o artigo Configurar uma política de failover automático flexível para um grupo de disponibilidade – SQL Server Always On discute, pode haver vários problemas que levam a isso. Os exemplos incluem:
- O serviço SQL Server está inativo.
- Tempo limite de concessão.
- A réplica de disponibilidade está em estado de falha.
- Despejos de memória gerados por spinlocks órfãos, violações de acesso ou muitos despejos de memória gerados em um curto período de tempo.
- Condição persistente de falta de memória no pool de recursos internos do SQL Server.
- Detecção de deadlock do Agendador.
- Detecção de um deadlock insolúvel.
Se necessário, entre em contato com o suporte do SQL Server para abrir um incidente de suporte para obter mais assistência para encontrar a causa raiz desses problemas internos de integridade do SQL Server