Solucionando problemas de failover automático em ambientes Always On do SQL Server
Este artigo ajuda você a resolver problemas que ocorrem durante o failover automático no Microsoft SQL Server.
Versão original do produto: SQL Server
Número original do KB: 2833707
Resumo
Os grupos de disponibilidade Always On do SQL Server podem ser configurados para failover automático. Se um problema de integridade for detectado na instância do SQL Server que está hospedando a réplica primária, a função primária poderá ser transferida para o parceiro de failover automático (réplica secundária). No entanto, a réplica secundária nem sempre pode ser transferida para a função primária. Em alguns casos, ele pode ser transferido apenas para a RESOLVING função. Nessa situação, nenhuma réplica terá a função primária, a menos que a réplica primária retorne a um estado íntegro. Além disso, os bancos de dados de disponibilidade ficarão inacessíveis.
Este artigo lista algumas causas comuns de failover automático malsucedido e discute as etapas que você pode seguir para diagnosticar a causa dessas falhas.
Sintomas se um failover automático for disparado com êxito
Quando um failover automático é disparado na instância do SQL Server que está hospedando a réplica primária, a réplica secundária faz a transição para a RESOLVING função e, em seguida, para a função primária. Embora o processo seja bem-sucedido, as entradas de erro são registradas no relatório de log do SQL Server que se assemelham ao seguinte texto:
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

Observação
A réplica secundária faz a transição com êxito de um RESOLVING_NORMAL estado para um PRIMARY_NORMAL estado.
Sintomas se um failover automático não for bem-sucedido
Se um evento de failover automático não for bem-sucedido, a réplica secundária não fará a transição com êxito para a função primária. Portanto, a réplica de disponibilidade relatará que essa réplica está em um RESOLVING estado. Além disso, os bancos de dados de disponibilidade relatam que estão em um NOT SYNCHRONIZING estado e os aplicativos não podem acessar esses bancos de dados.
Por exemplo, na imagem a seguir, o SQL Server Management Studio relata que a réplica secundária está em um RESOLVING estado porque o processo de failover automático não pôde fazer a transição da réplica secundária para a função primária.
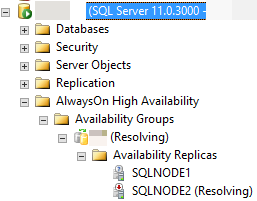
As seções a seguir discutem vários motivos possíveis pelos quais o failover automático pode não ser bem-sucedido e como diagnosticar cada causa.
Caso 1: O valor "Máximo de Falhas no Período Especificado" está esgotado
O grupo de disponibilidade tem propriedades de recurso de cluster do Windows, como a propriedade Máximo de Falhas no Período Especificado . Essa propriedade é usada para evitar o movimento indefinido de um recurso clusterizado quando ocorrem várias falhas de nó.
Para investigar e diagnosticar se essa é a causa do failover malsucedido, examine o log de cluster do Windows (Cluster.log) e verifique a propriedade.
Etapa 1: Examinar os dados no log do cluster do Windows (Cluster.log)
Use o Windows PowerShell para gerar o log de cluster do Windows no nó de cluster que está hospedando a réplica primária. Para fazer isso, execute o seguinte cmdlet em uma janela do PowerShell com privilégios elevados na instância do SQL Server que está hospedando a réplica primária:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15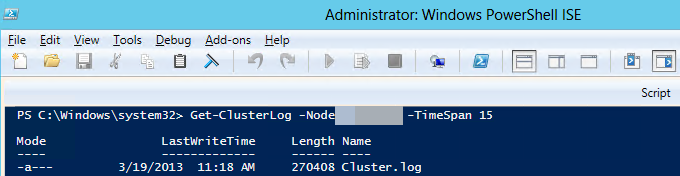
[!NOTES]
- O
-TimeSpan 15parâmetro nesta etapa pressupõe que o problema que está sendo diagnosticado ocorreu durante os 15 minutos anteriores. - Por padrão, o arquivo de log é criado em %WINDIR%\cluster\reports.
- O
Abra o arquivo Cluster.log no Bloco de Notas para revisar o log do cluster do Windows.
No Bloco de Notas, selecione Editar>Localização e pesquise a cadeia de caracteres "failoverCount" no final do arquivo. Nos resultados, você deve encontrar uma mensagem semelhante à seguinte mensagem:
Não há failover do nome do recurso> do grupo<, failoverCount 3, número de configuração <>de failoverThreshold, computedFailoverThreshold 2

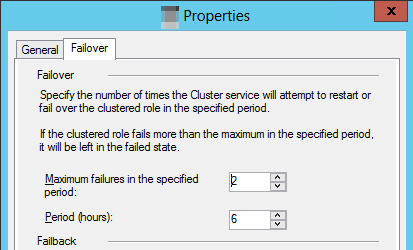
Etapa 2: Verificar o máximo de falhas na propriedade Período especificado
Inicie o Gerenciador de Cluster de Failover.
No painel de navegação, selecione Funções.
No painel Funções, clique com o botão direito do mouse no recurso clusterizado e selecione Propriedades.
Selecione a guia Failover e selecione o valor Máximo de Falhas no Período Especificado .
Observação
O comportamento padrão especifica que, se o recurso clusterizado falhar três vezes em seis horas, ele deverá permanecer no estado de falha. Para um grupo de disponibilidade, isso significa que a réplica é deixada
RESOLVINGno estado.
Conclusão
Depois de analisar o log, você descobre que o valor de failoverCount de 3 é maior que o valor computedFailoverThreshold de 2. Portanto, o cluster do Windows não pode concluir a operação de failover do recurso do grupo de disponibilidade para o parceiro de failover.
Resolução
Para resolver esse problema, aumente o valor Máximo de Falhas no Período Especificado .
Observação
Aumentar esse valor pode não resolver o problema. Pode haver um problema mais crítico que faz com que o grupo de disponibilidade falhe muitas vezes em um curto período. Por padrão, esse período é de 15 minutos. Aumentar esse valor pode simplesmente fazer com que o grupo de disponibilidade falhe mais vezes e permaneça em um estado de falha. Recomendamos que você use a solução de problemas agressiva para determinar por que o failover automático continua ocorrendo.
Caso 2: Permissões de conta NT Authority\SYSTEM insuficientes
A DLL de recurso do Mecanismo de Banco de Dados do SQL Server se conecta à instância do SQL Server que está hospedando a réplica primária usando ODBC para monitorar a integridade. As credenciais de logon usadas para essa conexão são a conta de logon local do SQL Server NT AUTHORITY\SYSTEM . Por padrão, essa conta de logon local recebe as seguintes permissões:
- Alterar qualquer grupo de disponibilidade
- Conectar SQL
- Exibir estado do servidor
Se a NT AUTHORITY\SYSTEM conta de logon não tiver nenhuma dessas permissões no parceiro de failover automático (a réplica secundária), o SQL Server não poderá iniciar a detecção de integridade quando ocorrer um failover automático. Portanto, a réplica secundária não pode fazer a transição para a função primária. Para investigar e diagnosticar se essa é a causa, examine o log de cluster do Windows. Para fazer isso, siga estas etapas:
Use o Windows PowerShell para gerar o log de cluster do Windows no nó do cluster. Para fazer isso, execute o seguinte cmdlet em uma janela do PowerShell com privilégios elevados na instância do SQL Server que está hospedando a réplica secundária que não fez a transição para a função primária:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
Abra o arquivo Cluster.log no Bloco de Notas para revisar o log do cluster do Windows.
Encontre uma entrada de erro semelhante ao seguinte texto:
Falha ao executar o comando diagnostics. O usuário não tem permissão para executar esta ação.
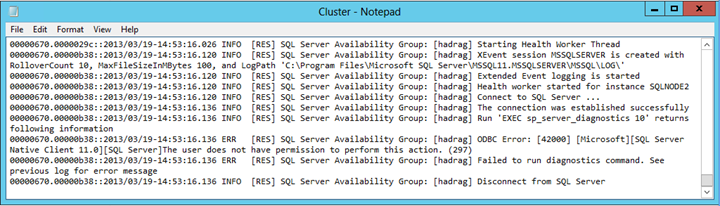
Conclusão
O arquivo Cluster.log relata que existe um problema de permissões quando o SQL Server executa o comando de diagnóstico. Neste exemplo, a falha foi causada pela remoção da permissão Exibir estado do servidor da conta de NT AUTHORITY\SYSTEM logon na instância do SQL Server que está hospedando a réplica secundária de um par de failover automático.
Resolução
Para resolver esse problema, conceda NT AUTHORITY\SYSTEM permissões suficientes à conta de logon para a detecção de integridade da DLL de recurso do Mecanismo de Banco de Dados do SQL Server.
Caso 3: Os bancos de dados de disponibilidade não estão em um estado SYNCHRONIZED
Para fazer failover automaticamente, todos os bancos de dados de disponibilidade definidos no grupo de disponibilidade devem estar em um SYNCHRONIZED estado entre a réplica primária e a réplica secundária. Quando ocorre um failover automático, essa condição de sincronização deve ser atendida para garantir que não haja perda de dados. Portanto, se um banco de dados de disponibilidade no grupo de disponibilidade estiver no estado de sincronização ou NOT SYNCHRONIZED , o failover automático não fará a transição bem-sucedida da réplica secundária para a função primária.
Para obter mais informações sobre as condições necessárias para um failover automático, consulte as Condições necessárias para um failover automático e as réplicas de confirmação síncrona dão suporte a duas seções de configurações de Failover e Modos de failover (Grupos de Disponibilidade AlwaysOn).
Para investigar e diagnosticar se essa é a causa do failover malsucedido, examine o log de erros do SQL Server. Você deve encontrar uma entrada de erro semelhante ao seguinte texto:
Um ou mais bancos de dados não estão sincronizados ou não ingressaram no grupo de disponibilidade.
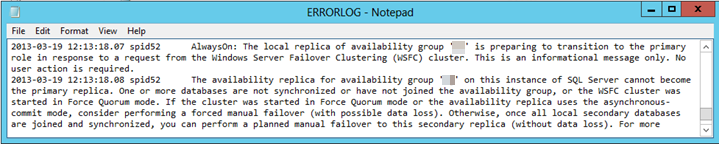
Para verificar se os bancos de dados de disponibilidade estavam no SYNCHRONIZED estado, siga estas etapas:
Conecte-se à réplica secundária.
Execute o script SQL a seguir para verificar o
is_failover_readyvalor de todos os bancos de dados de disponibilidade no grupo de disponibilidade que não fizeram failover.Observação
Um valor zero para qualquer um dos bancos de dados de disponibilidade pode impedir o failover automático. Esse valor indica que o banco de dados de disponibilidade não
SYNCHRONIZEDera .SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)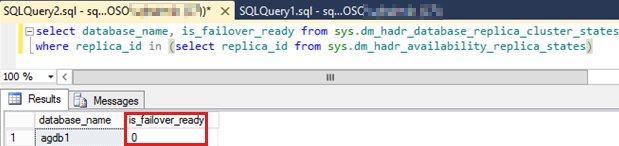
Conclusão
Um failover automático bem-sucedido do grupo de disponibilidade requer que todos os bancos de dados de disponibilidade estejam no SYNCHRONIZED estado. Para obter mais informações sobre modos de disponibilidade, consulte Modos de disponibilidade em Grupos de disponibilidade AlwaysOn.
Caso 4: a configuração "Forçar Criptografia de Protocolo" está selecionada para os protocolos de cliente na réplica secundária (primária de destino), embora a réplica não esteja configurada para criptografia
Durante o failover, quando o servidor primário detecta um problema de integridade, a DLL do cluster no parceiro de failover (réplica secundária) tenta se conectar à réplica local para iniciar o monitoramento de integridade. Isso faz parte da transição para o papel principal. Se a réplica secundária não estiver configurada para criptografia, mas a configuração Forçar Criptografia de Protocolo for definida inadvertidamente na configuração do cliente, a conexão falhará e o failover não poderá ocorrer.
Para verificar essa configuração:
- Inicie o SQL Server Configuration Manager
- No painel esquerdo, clique com o botão direito do mouse na Configuração do SQL Native Client 11.0 e selecione Propriedades.
- Na caixa de diálogo, verifique a configuração Forçar Criptografia de Protocolo . Se estiver definido como Sim, altere o valor para Não.
- Teste novamente o failover.
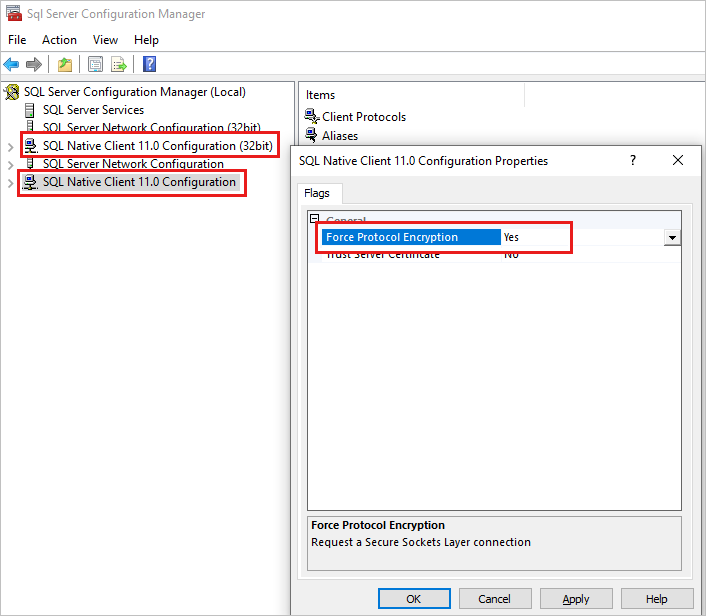
Conclusão
O monitoramento de integridade Always On do SQL Server usa uma conexão ODBC local para monitorar a integridade do SQL Server. A Criptografia de Protocolo Forçado deve ser habilitada na seção Configuração do Cliente do SQL Server Configuration Manager somente se o próprio SQL Server tiver sido configurado para Forçar Criptografias no SQL Server Configuration Manager na seção Configuração de Rede do SQL Server. Para saber mais, confira Habilitar conexões criptografadas para o Mecanismo de Banco de Dados.
Caso 5: problemas de desempenho na réplica secundária ou no nó fazem com que as verificações de integridade Always On falhem
Antes de fazer failover da réplica primária para a réplica secundária, a DLL de recurso do Mecanismo de Banco de Dados do SQL Server se conecta à réplica secundária para verificar a integridade da réplica. Se essa conexão falhar devido a problemas de desempenho na réplica secundária, o failover automático não ocorrerá.
Para investigar e diagnosticar se essa é a causa, siga estas etapas:
Examine o log do cluster na réplica secundária para verificar a mensagem de erro "Não é possível concluir o processo de logon devido ao atraso na abertura da conexão do servidor".
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.Essa situação poderá ocorrer se o failover for feito em uma réplica secundária do SQL Server que tenha uma carga de trabalho existente ocupada. Isso pode atrasar a resposta do SQL Server à tentativa de solicitação de conexão de integridade do HADR e impedir uma tentativa de failover bem-sucedida.
Para determinar se há pressão sobre os agendadores do sistema, use SQL Server Management Studio para executar o seguinte script na réplica secundária:
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' ENDVeja a seguir um exemplo de saída da consulta anterior:
CurrentDate TotalThreads Tópicos atuais Tópicos disponíveis TrabalhadoresEsperandoPCPU RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 26- 21 185 2020-10-06 01:27:29.343 1216 13:46 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 13:46 -130 13 5:39 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 Valores altos relatados e
WorkersWaitingForCpuRequestWaitingForThreadsindicam que a contenção de agendamento está ocorrendo e que o SQL Server não pode atender à carga de trabalho atual em tempo hábil.
Resolução
Se você tiver esse problema, reequilibre a carga de trabalho na réplica secundária ou considere aumentar a capacidade de processamento (adicionar processadores) nos computadores que executam essas cargas de trabalho.
Solucionar problemas de outros eventos de failover com falha
Para monitorar a integridade da nova réplica primária durante o failover, você deve conectar localmente o monitoramento de integridade AlwaysOn à instância do SQL Server que está fazendo a transição para a função primária.
Além dos motivos mais comuns discutidos neste artigo, há muitos outros motivos pelos quais essa tentativa de conexão pode falhar. Para investigar ainda mais uma tentativa de failover com falha, examine o log do cluster no parceiro de failover (a réplica para a qual você não pôde fazer failover):
Use o Windows PowerShell para gerar o log do Cluster do Windows no nó do cluster. Para fazer isso, execute o cmdlet a seguir em uma janela do PowerShell com privilégios elevados na instância do SQL Server que está hospedando a réplica secundária que não fez a transição para a função primária. Um log de cluster será gerado para os últimos 60 minutos de atividade.
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Para revisar o log do Windows Cluster, abra o arquivo Cluster.log no Bloco de Notas.
Pesquise a cadeia de caracteres "Conectar-se ao SQL Server" que cai durante o evento de failover malsucedido.
Examine as mensagens de logon subsequentes usando a ID do thread (consulte a captura de tela a seguir) para correlacionar os eventos relacionados ao evento de logon. O exemplo a seguir mostra uma pesquisa por "Conectar-se ao SQL Server". Ele também mostra o uso da ID do thread (lado esquerdo) para localizar os outros diagnósticos que descrevem por que a tentativa de conexão falhou.


Os exemplos a seguir mostram falhas de conexão com a nova réplica primária.
Exemplo de conjunto 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
Resolução
Inicie o SQL Server Configuration Manager e verifique se a Memória Compartilhada ou TCP/IP está habilitado em Protocolos de Cliente para a Configuração do SQL Native Client.
Exemplo de conjunto 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
Resolução
Inicie o SQL Server Configuration Manager e verifique se a Memória Compartilhada ou TCP/IP está habilitado em Protocolos de Cliente para a Configuração do SQL Native Client.
Exemplo de conjunto 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
Resolução
Examine o caso 2: permissões de conta NT Authority\SYSTEM insuficientes.