Explorar a arquitetura da solução
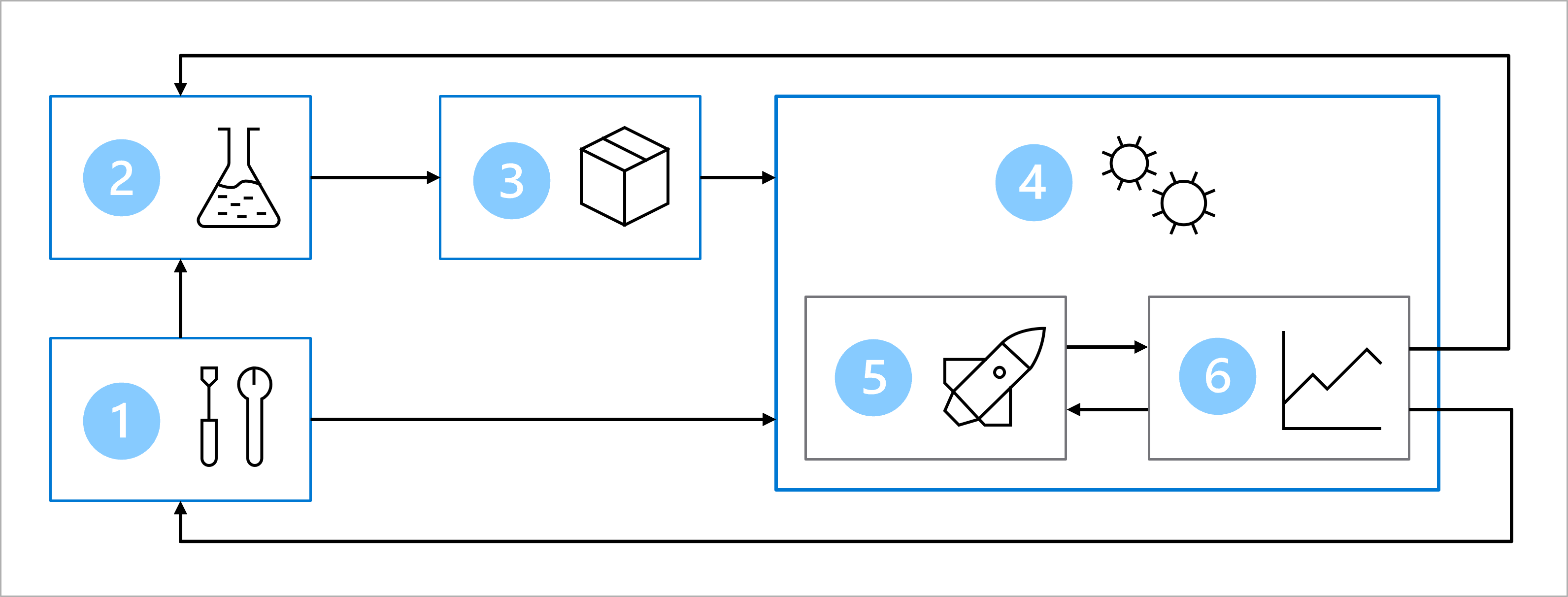
Vamos examinar a arquitetura que você determinou para o fluxo de trabalho de MLOps (Operações de Machine Learning) para entender onde e quando devemos verificar o código.
Observação
O diagrama é uma representação simplificada de uma arquitetura de MLOps. Para ver uma arquitetura mais detalhada, explore os vários casos de uso no acelerador de solução de MLOps (v2).
A principal meta da arquitetura de MLOps é criar uma solução robusta e reproduzível. Para isso, a arquitetura inclui:
- Instalação: criar todos os recursos do Azure necessários para a solução.
- Desenvolvimento de modelo (loop interno): explorar e processar os dados para treinar e avaliar o modelo.
- Integração contínua: empacotar e registrar o modelo.
- Implantação de modelo (loop externo): implantar o modelo.
- Implantação contínua: testar o modelo e promovê-lo ao ambiente de produção.
- Monitoramento: monitorar o desempenho do modelo e do ponto de extremidade.
Para mover um modelo do desenvolvimento para a implantação, você precisará de integração contínua. Durante a integração contínua, você empacotará e registrará o modelo. No entanto, antes de empacotar um modelo, você precisará verificar o código usado para treinar o modelo.
Junto com a equipe de ciência de dados, você concordou em usar o desenvolvimento baseado em tronco. Os branches não apenas protegerão o código de produção, eles também permitirão que você verifique automaticamente as alterações propostas antes de mesclá-las com o código de produção.
Vamos explorar o fluxo de trabalho para um cientista de dados:
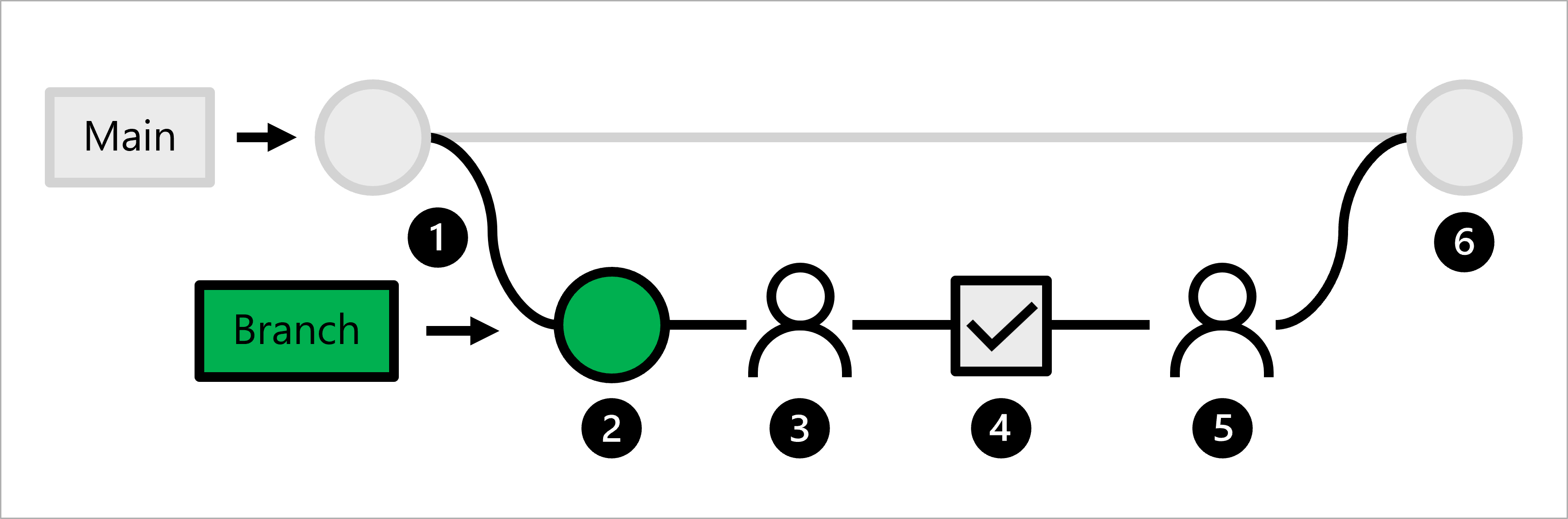
- O código de produção fica hospedado na ramificação principal.
- Um cientista de dados cria um branch de recurso para desenvolvimento do modelo.
- O cientista de dados cria uma solicitação de pull para propor o envio das alterações por push para a ramificação principal.
- Quando a solicitação de pull é criada, um fluxo de trabalho do GitHub Actions é disparado para verificar o código.
- Quando o código é aprovado no lint e no teste de unidade, o cientista de dados líder precisa aprovar as alterações propostas.
- Depois que o cientista de dados líder aprovar as alterações, a solicitação de pull será mesclada e a ramificação principal será atualizada de acordo.
Como engenheiro de machine learning, você precisará criar um fluxo de trabalho do GitHub Actions que verifica o código executando um linter e testes de unidade sempre que uma solicitação pull é criada.
Dica
Saiba mais sobre como trabalhar com o controle do código-fonte em projetos de machine learning, incluindo o desenvolvimento baseado em tronco e a verificação de código localmente.