Compreender o Delta Lake
O Delta Lake é uma camada de armazenamento de código aberto que adiciona semântica de banco de dados relacional ao processamento do data lake baseado em Spark. As tabelas nas lakehouses do Microsoft Fabric são tabelas Delta, representadas pelo ícone Delta triangular (Δ) em tabelas na interface do usuário da lakehouse.
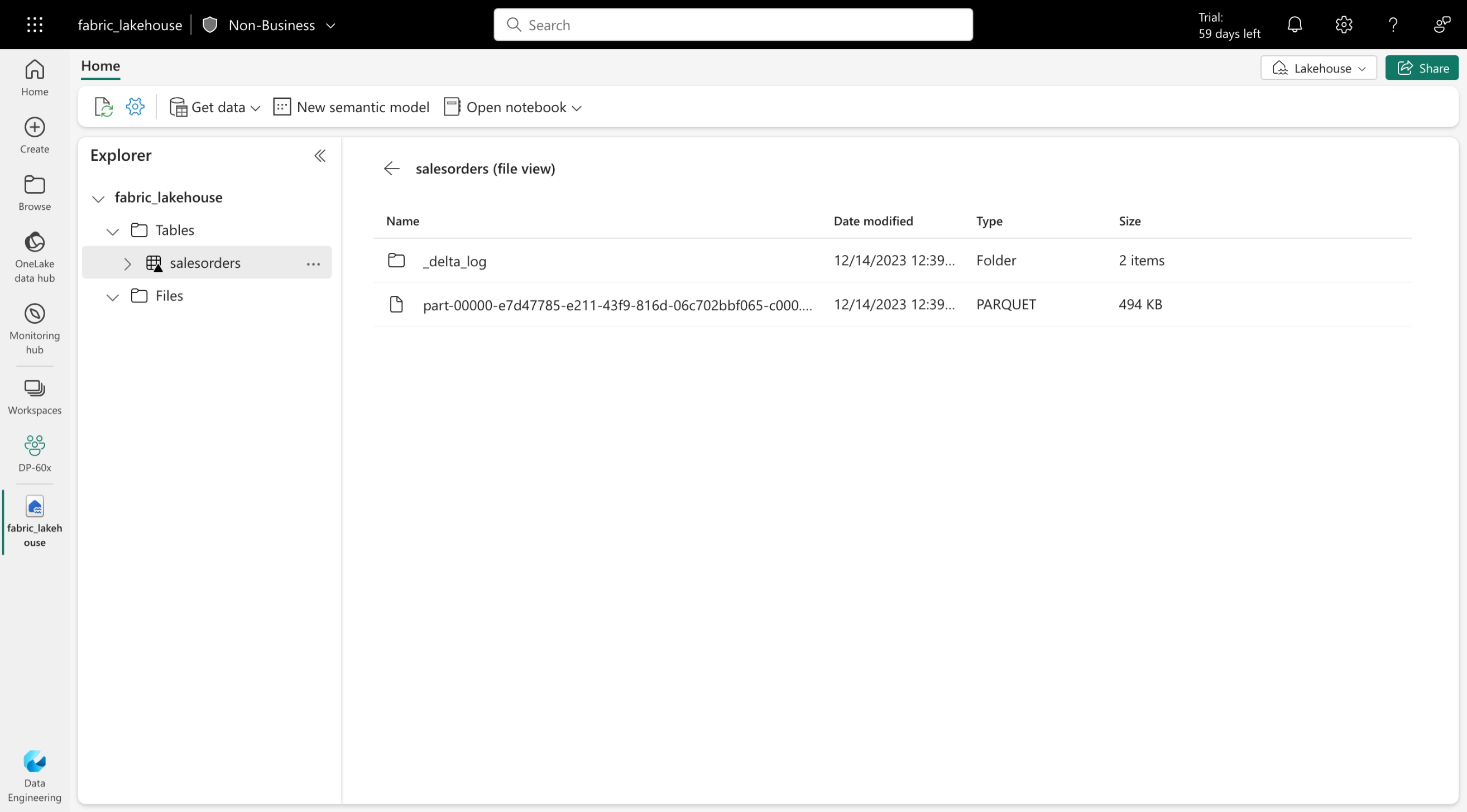
As tabelas Delta são abstrações de esquema em arquivos de dados armazenados no formato Delta. Para cada tabela, o lakehouse armazena uma pasta que contém arquivos de dados Parquet e uma pasta _delta_Log em que os detalhes da transação são registrados no formato JSON.
Os benefícios de usar tabelas Delta incluem o seguinte:
- Tabelas relacionais que dão suporte a consulta e modificação de dados. Com o Apache Spark, é possível armazenar dados em tabelas Delta compatíveis com operações CRUD (criar, ler, atualizar e excluir). Em outras palavras, você pode selecionar, inserir, atualizar e excluir linhas de dados da mesma forma que faria em um sistema de banco de dados relacional.
- Suporte para transações ACID. Os bancos de dados relacionais são projetados para dar suporte a modificações de dados transacionais que fornecem atomicidade (transações concluídas como apenas uma unidade de trabalho), consistência (transações deixam o banco de dados em um estado consistente), isolamento (transações em processo não podem interferir entre si) e durabilidade (quando uma transação é concluída, as alterações feitas são persistentes). O Delta Lake traz esse mesmo suporte transacional ao Spark implementando um log de transações e impondo isolamento serializável para operações simultâneas.
- Controle de versão de dados e viagem no tempo. Como todas as transações estão registradas no log de transações, você pode acompanhar várias versões de cada linha da tabela e até mesmo usar o recurso de viagem no tempo para recuperar uma versão anterior de uma linha em uma consulta.
- Suporte para dados em lote e de streaming. Embora a maioria dos bancos de dados relacionais inclua tabelas que armazenam dados estáticos, o Spark inclui suporte nativo para streaming de dados por meio da API de Streaming Estruturado do Spark. As tabelas do Delta Lake podem ser usadas como coletores (destinos) e origens para dados de streaming.
- Formatos padrão e interoperabilidade. Os dados subjacentes das tabelas Delta são armazenados no formato Parquet, que é comumente usado em pipelines de ingestão de data lake. Além disso, você pode usar o ponto de extremidade de análises de dados do SQL para o lakehouse do Microsoft Fabric para consultar tabelas Delta no SQL.