Escolher o destino de computação apropriado
No Azure Machine Learning, os destinos de computação são computadores físicos ou virtuais nos quais os trabalhos são executados.
Entender os tipos de computação disponíveis
O Azure Machine Learning dá suporte a diversos tipos de computação para experimentação, treinamento e implantação. Com muitos tipos de computação, é possível selecionar o tipo de destino de computação mais apropriado para as necessidades específicas.
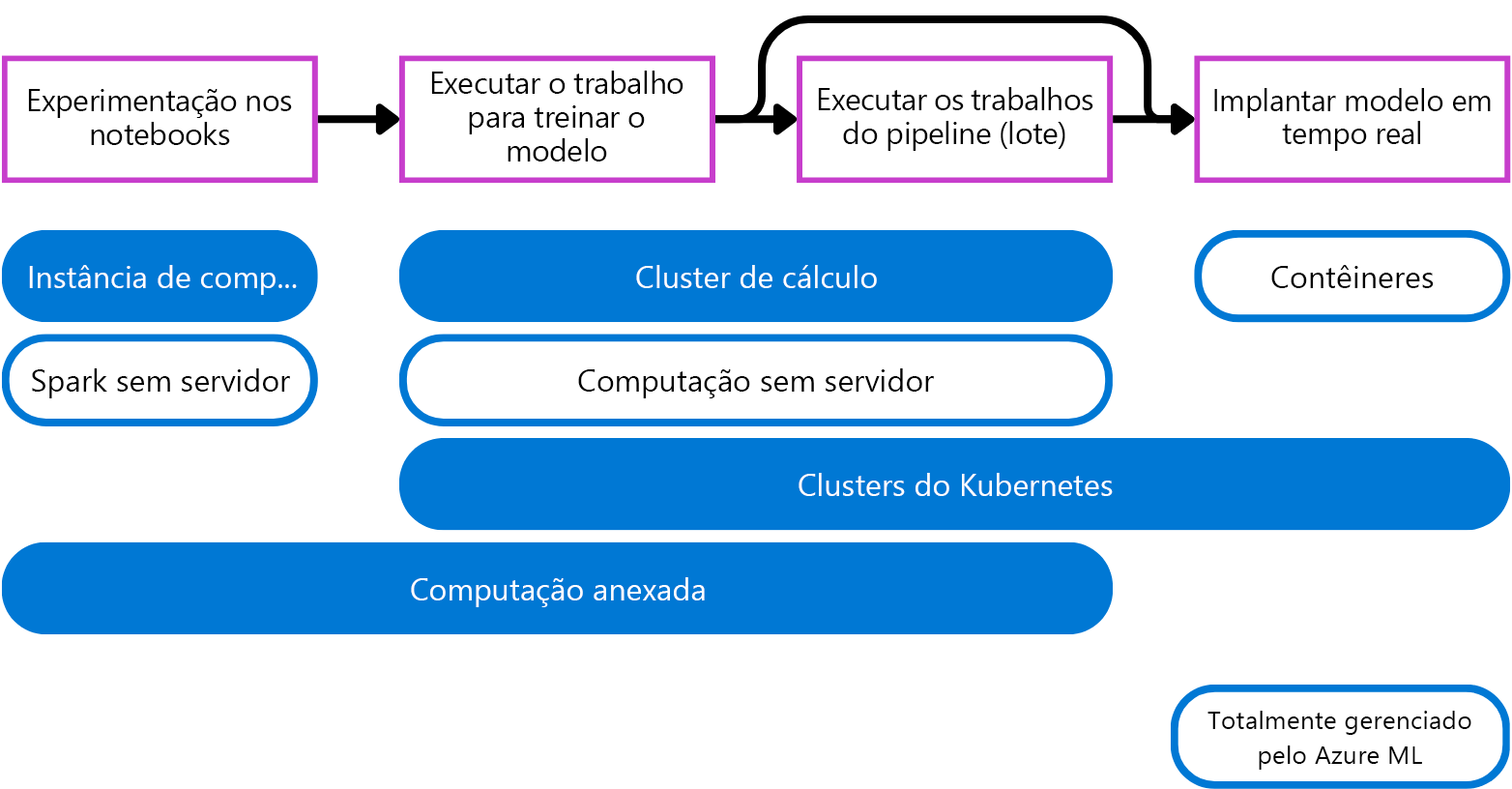
- Instância de computação: comporta-se de maneira semelhante a uma máquina virtual e é usada principalmente para executar notebooks. É ideal para experimentação.
- Clusters de computação: clusters de diversos nós de máquinas virtuais que aumentam ou diminuem a capacidade automaticamente de acordo com a demanda. Uma maneira econômica de executar scripts que precisam processar grandes volumes de dados. Os clusters também permitem usar o processamento paralelo para distribuir a carga de trabalho e reduzir o tempo necessário para executar um script.
- Clusters do Kubernetes: cluster baseado na tecnologia Kubernetes, que fornece mais controle sobre como a computação é configurada e gerenciada. É possível anexar seu cluster autogerenciado do AKS (Azure Kubernetes) para computação em nuvem ou um cluster do Arc Kubernetes para cargas de trabalho locais.
- Computação anexada: Permite que você anexe a computação existente, como máquinas virtuais do Azure ou clusters do Azure Databricks, ao seu workspace.
- Computação sem servidor: Uma computação totalmente gerenciada e sob demanda que você pode utilizar para trabalhos de treinamento.
Observação
O Azure Machine Learning oferece a opção de criar e gerenciar sua própria computação ou usar a computação totalmente gerenciada pelo Azure Machine Learning.
Quando usar cada tipo de computação?
Em geral, há algumas melhores práticas para trabalhar com destinos de computação. Para entender como escolher o tipo apropriado de computação, são fornecidos diversos exemplos. Lembre-se de que o tipo de computação usado sempre depende da especificidade da situação.
Escolher um destino de computação para experimentação
Imagine que você é um cientista de dados e precisa desenvolver um novo modelo de machine learning. Você provavelmente terá um pequeno subconjunto dos dados de treinamento com os quais poderá realizar experimentos.
Durante a experimentação e o desenvolvimento, é possível trabalhar com um Jupyter notebook. Uma experiência de notebook se beneficia mais de uma computação em execução contínua.
Muitos cientistas de dados estão familiarizados com a execução de notebooks em seus dispositivos locais. Uma alternativa de nuvem gerenciada pelo Azure Machine Learning é uma instância de computação. Como alternativa, você também pode optar pela computação sem servidor do Spark para executar o código do Spark em notebooks, se quiser usar o poder de computação distribuído do Spark.
Escolher um destino de computação para produção
Após a experimentação, é possível treinar seus modelos executando scripts Python para se preparar para a produção. Os scripts serão mais fáceis de automatizar e agendar para quando for necessário treinar novamente o modelo de maneira contínua ao longo do tempo. É possível executar scripts como trabalhos (pipeline).
Ao passar para a produção, você deseja que o destino de computação esteja pronto para lidar com grandes volumes de dados. Quanto mais dados forem usados, melhor será o modelo de machine learning.
Ao treinar modelos com scripts, você precisa de um destino de computação sob demanda. Um cluster de cálculo aumentará a capacidade automaticamente quando os scripts precisarem ser executados e a reduzirá automaticamente quando a execução deles terminar. Se você quiser uma alternativa que não precise criar e gerenciar, poderá usar a computação sem servidor do Azure Machine Learning.
Escolher um destino de computação para implantação
O tipo de computação que você precisa ao usar seu modelo para gerar previsões depende se você deseja previsões em lote ou em tempo real.
Para previsões em lote, você pode executar um trabalho de pipeline no Azure Machine Learning. Os destinos de computação, como clusters de computação e a computação sem servidor do Azure Machine Learning, são ideais para trabalhos de pipeline, pois são sob demanda e escalonáveis.
Quando você deseja previsões em tempo real, precisa de um tipo de computação em execução contínua. As implantações em tempo real, portanto, se beneficiam de uma computação mais leve (e, portanto, mais econômica). Os contêineres são ideais para implantações em tempo real. Quando você implanta seu modelo em um ponto de extremidade online gerenciado, o Azure Machine Learning cria e gerencia contêineres para você executar seu modelo. Como alternativa, você pode anexar clusters do Kubernetes para gerenciar a computação necessária para gerar previsões em tempo real.