Configurar o ambiente de execução do notebook Jupyter
Nesta seção, trabalharemos com o Jupyter Notebook que foi carregado em nosso workspace do Jupyter. Executaremos comandos que instalarão dependências para garantir que o nosso ambiente possa executar tarefas de AutoML referenciadas posteriormente. Este processo envolverá fazer upgrade do SDK do Python do Azure Machine Learning e instalar o pacote do Python torchvision.
Configurar o ambiente de execução do notebook Jupyter
Para abrir o notebook do Jupyter, navegue até o workspace do Jupyter e selecione o arquivo AutoMLImage_ObjectDetection.ipynb.
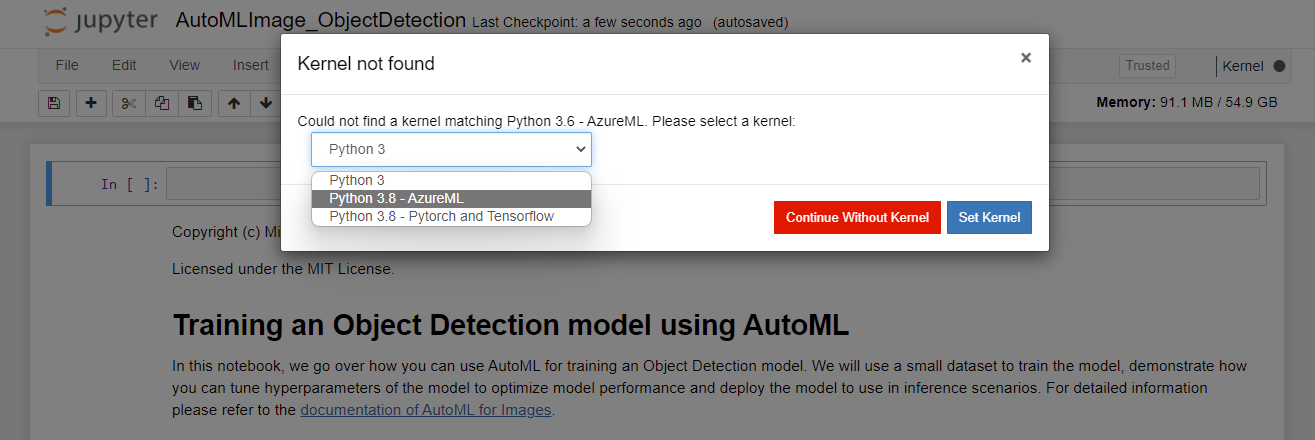
Se receber um prompt de Kernel não encontrado, selecione Python 3.8 – AzureML na lista suspensa, conforme mostrado, e selecione Definir Kernel.
Execute as células na seção Configuração do Ambiente. Isso pode ser feito selecionando a célula e pressionando Shift+Enter no teclado. Repita esse processo para cada célula e pare depois de executar pip install torchvision==0.9.1.
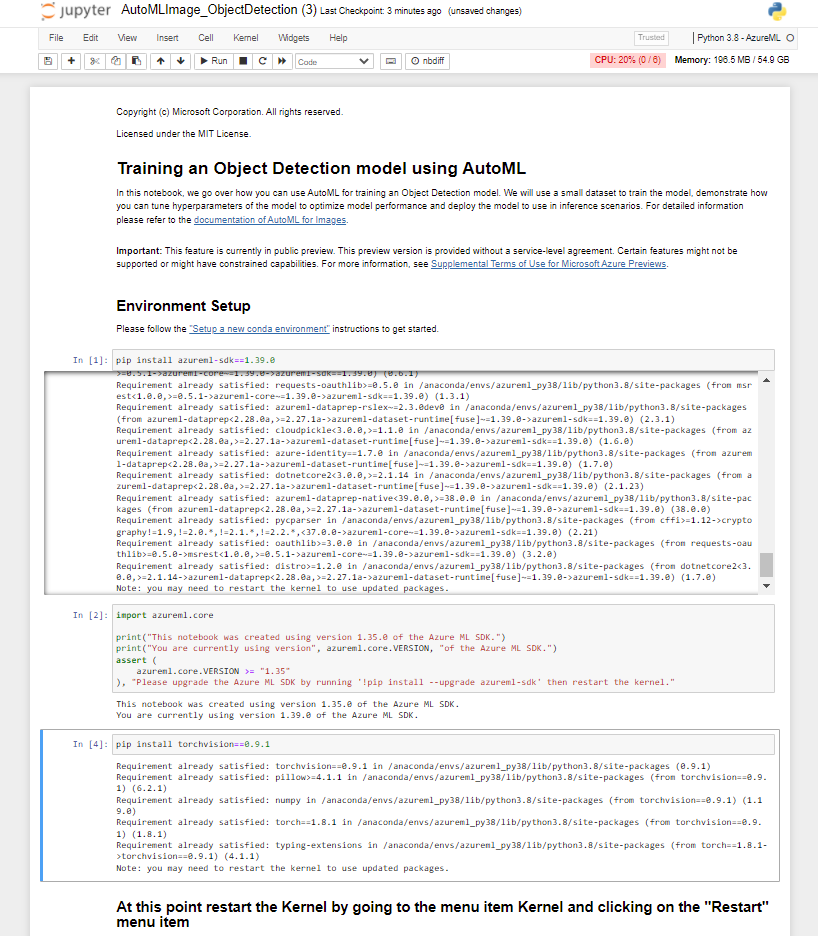
Depois de executar com sucesso a tarefa pip install torchvision==0.9.1, você precisará reiniciar o Kernel. Para reiniciar o kernel, selecione o item de menu Kernel e escolha Reiniciar na lista suspensa.
Execute a célula *pip freeze, que listará todas as bibliotecas do Python instaladas. Em seguida, execute a célula abaixo dela para importar as bibliotecas que serão usadas em outras etapas.
Continue executando as células na seção Configuração do workspace. Esta etapa será lida no arquivo config.json que foi carregado anteriormente e nos permitirá executar tarefas em seu workspace do Azure Machine Learning.
Continue executando as células na seção Configuração do destino de computação. Altere o valor de compute_name de modo a corresponder ao nome da instância de computação existente no workspace do Estúdio do Azure Machine Learning. O script poderá falhar ao criar a instância se uma instância com o mesmo nome já existir na mesma região e criar uma segunda instância. As etapas subsequentes ainda funcionarão, mas não usarão o recurso existente.
Continue executando as células na seção Configuração do experimento. Isso criará um experimento do Azure Machine Learning que nos permitirá acompanhar o status do modelo durante o treinamento.
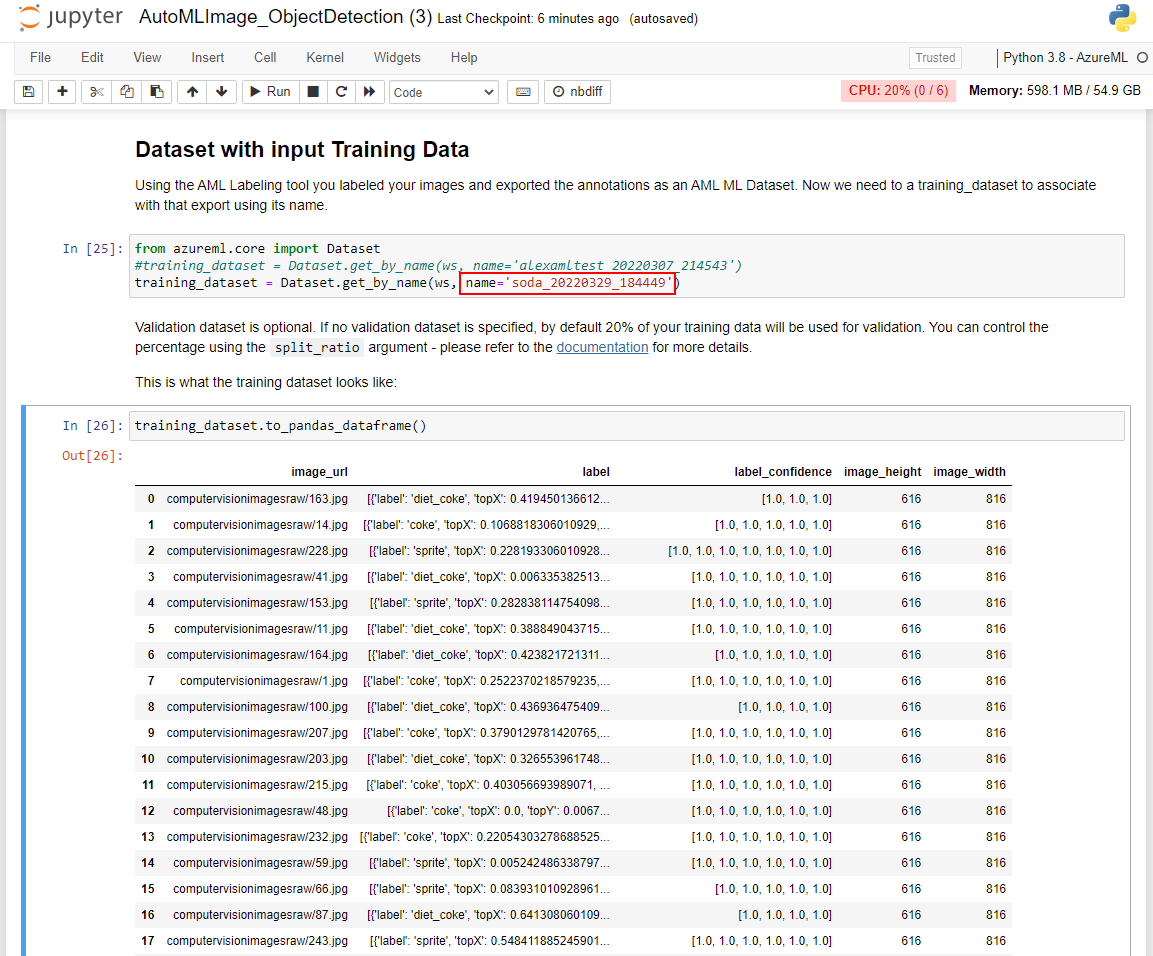
Continue executando as células na seção Conjunto de dados com Dados de Treinamento de entrada. Observe que você precisará substituir a variável de nome pelo nome do conjunto de dados que foi exportado no final do módulo anterior. Este valor pode ser obtido na instância do estúdio do Azure Machine Learning no painel esquerdo. A partir daí, localize a seção Ativos e selecione Conjuntos de dados. Você pode validar se o Conjunto de dados foi importado corretamente exibindo a saída na célula training_dataset.to_pandas_dataframe().