Executar códigos do Spark
Para editar e executar códigos do Spark no Microsoft Fabric, é possível usar notebooks ou definir um trabalho do Spark.
Notebooks
Quando você quiser usar o Spark para explorar e analisar dados interativamente, use um notebook. Os notebooks permitem combinar texto, imagens e código escritos em vários idiomas para criar um item interativo que você pode compartilhar com outras pessoas e no qual você pode colaborar.
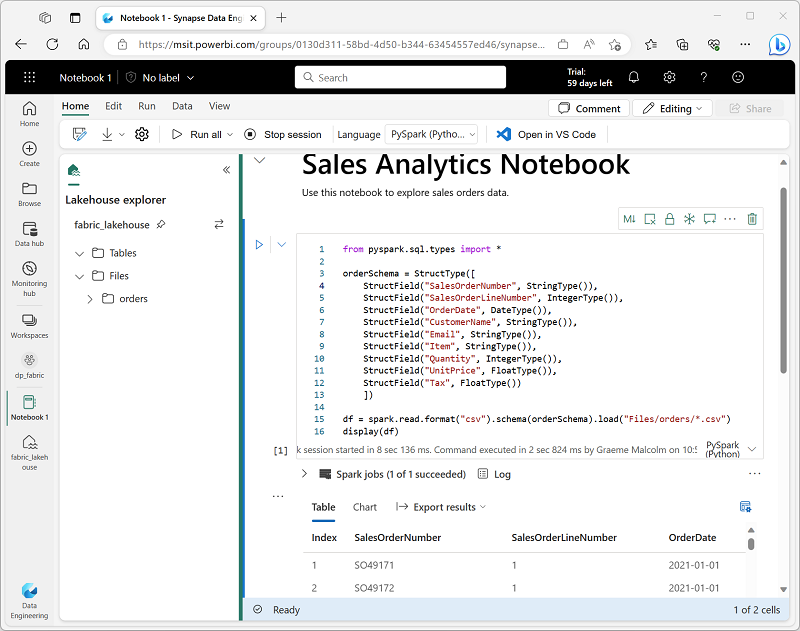
Os notebooks consistem em uma ou mais células, e cada uma delas pode conter conteúdos formatados por markdown ou códigos executáveis. É possível executar o código interativamente no notebook e ver os resultados imediatamente.
Definição de trabalho do Spark
Para usar o Spark a fim de ingerir e transformar dados como parte de um processo automatizado, defina um trabalho do Spark que execute um script sob demanda ou com base em um agendamento.
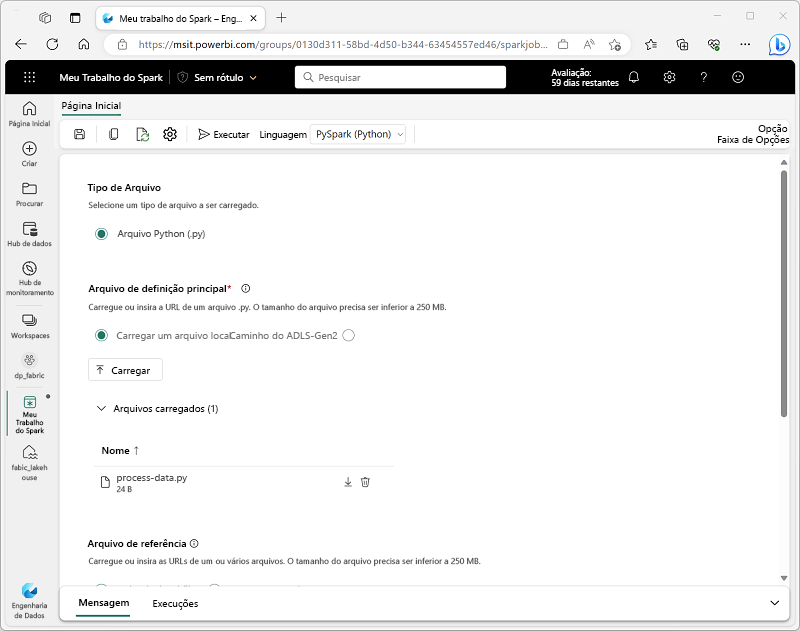
Para configurar um trabalho do Spark, crie uma definição de trabalho do Spark no workspace e especifique o script que ela deve executar. Também é possível especificar um arquivo de referência (por exemplo, um arquivo de código Python que contém definições de funções usadas no script) e uma referência a um lakehouse específico que contém dados que o script processa.