Criar um cluster Spark
Você pode criar um ou mais clusters em seu workspace do Azure Databricks usando o portal do Azure Databricks.
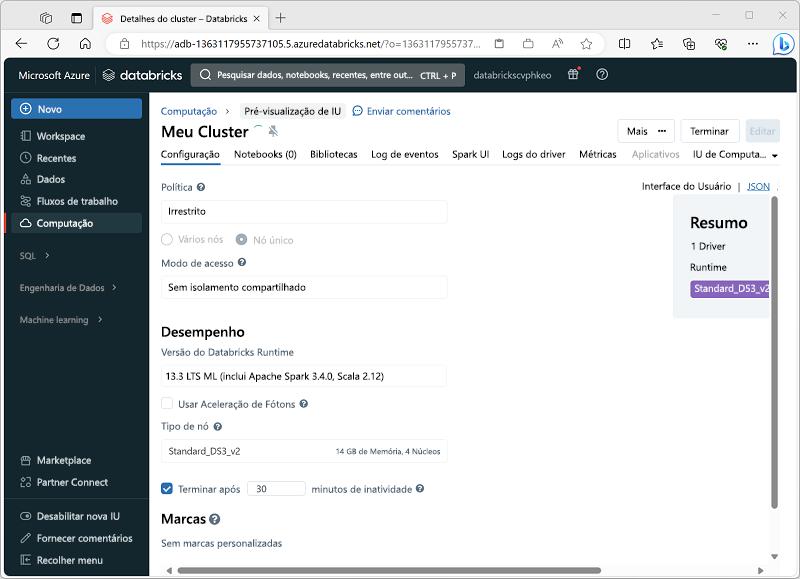
Ao criar o cluster, você pode especificar as configurações, incluindo:
- Um nome para o cluster.
- O modo do cluster, que pode ser:
- Standard: adequado para cargas de trabalho de usuário único que exigem vários nós de trabalho.
- Alta simultaneidade: adequado para cargas de trabalho em que haverá vários usuários operando o cluster simultaneamente.
- Nó único: adequado para cargas de trabalho pequenas ou de teste, que requerem apenas um nó de trabalho.
- A versão do Databricks Runtime a ser usada no cluster; que dita as versões do Spark e de componentes individuais, como Python, Scala e outros que são instalados.
- O tipo de máquina virtual (VM) usada para os nós de trabalho no cluster.
- O número mínimo e máximo de nós de trabalho no cluster.
- O tipo de VM usado para o nó driver do cluster.
- Se o cluster dá suporte ao dimensionamento automático para redimensionar dinamicamente o cluster.
- Quanto tempo o cluster pode permanecer ocioso antes de ser desligado automaticamente.
Como o Azure gerencia recursos de cluster
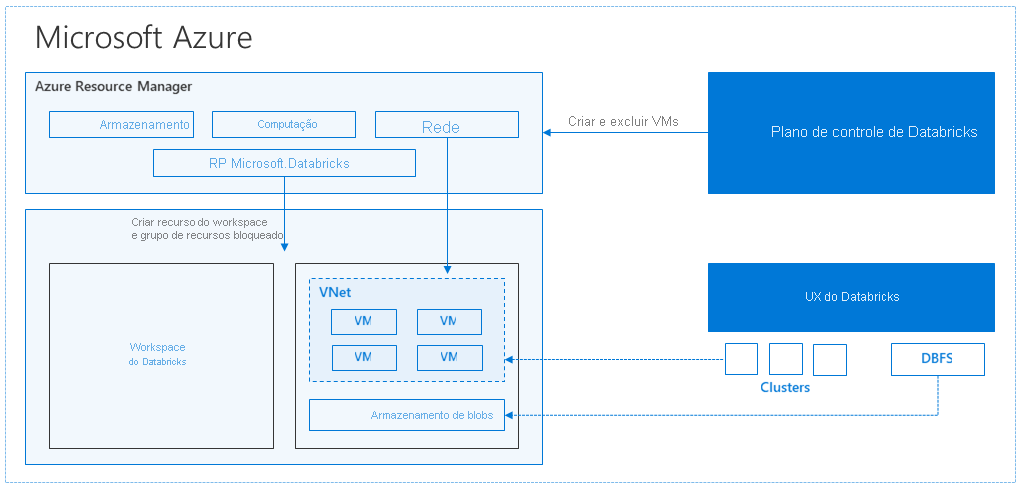
Quando você cria um workspace do Azure Databricks, um dispositivo do Databricks é implantado como um recurso do Azure na sua assinatura. Ao criar um cluster no workspace, você especifica os tipos e tamanhos das VMs (máquinas virtuais) a serem usadas para os nós driver e de trabalho, bem como algumas outras opções de configuração, mas o Azure Databricks gerencia todos os outros aspectos do cluster.
O dispositivo do Databricks é implantado no Azure como um grupo de recursos gerenciado dentro da sua assinatura. Esse grupo de recursos contém as VMs driver e de trabalho para seus clusters, juntamente com outros recursos necessários, incluindo uma rede virtual, um grupo de segurança e uma conta de armazenamento. Todos os metadados de seu cluster, como trabalhos agendados, são armazenados em um Banco de dados do Azure com replicação geográfica para obter tolerância a falhas.
Internamente, o AKS (Serviço de Kubernetes do Azure) é usado para executar o plano de controle e os planos de dados do Azure Databricks por meio de contêineres em execução na última geração de hardware do Azure (VMs Dv3), com SSDs do NvMe capazes de disparar latência de 100us em máquinas virtuais do Azure de alto desempenho com rede acelerada. O Azure Databricks utiliza esses recursos do Azure para melhorar ainda mais o desempenho do Spark. Depois que os serviços em seu grupo de recursos gerenciados estiverem prontos, você poderá gerenciar o cluster do Databricks por meio da interface do usuário do Azure Databricks e por meio de recursos como dimensionamento automático e terminação automática.
Observação
Você também tem a opção de anexar seu cluster a um pool de nós ociosos para reduzir o tempo de inicialização do cluster. Para obter mais informações, confira Pools na documentação do Azure Databricks.