Diagnosticar problemas examinando as configurações e as métricas
O monitoramento do desempenho do Azure Load Balancer pode fornecer um aviso antecipado para possíveis falhas. O Azure Monitor fornece muitas métricas importantes que você usa para examinar as tendências no desempenho do Load Balancer. Você também poderá disparar alertas se uma ou mais VMs (máquinas virtuais) falhar em solicitações de investigação de integridade.
No cenário de exemplo, você monitora o desempenho do sistema com balanceamento de carga para garantir que o ele cumpra os requisitos. Se o desempenho diminuir e as conexões com as VMs começarem a falhar, você deve solucionar problemas do sistema para determinar a causa e corrigir o problema. Ao final desta unidade, você será capaz de:
- Descrever as métricas disponíveis para medir a taxa de transferência e o desempenho de um sistema com balanceamento de carga.
- Usar a página do Resource Health no portal do Azure para monitorar a integridade do sistema.
- Explicar como resolver problemas comuns em um sistema com balanceamento de carga.
Usar o Azure Monitor para solucionar problemas do Load Balancer
Com o Azure Monitor, você pode capturar e examinar os logs de diagnóstico e dados de desempenho para o Load Balancer.
Monitorar a conectividade
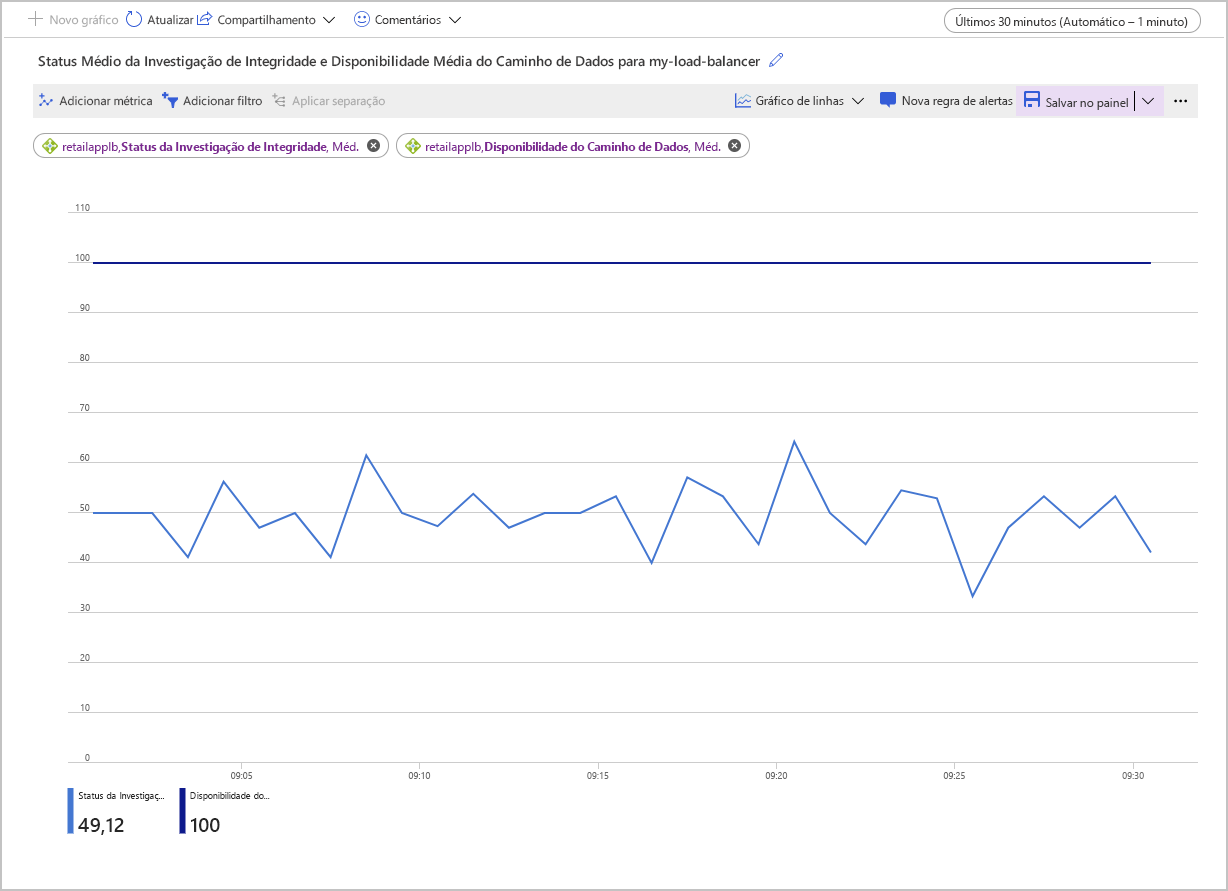
Você pode visualizar as métricas para o Load Balancer usando o painel Métricas no portal do Azure. De uma perspectiva de solução de problemas de conectividade, as métricas mais importantes são Disponibilidade do Caminho de Dados e Status da Investigação de Integridade.

O Load Balancer testa continuamente a disponibilidade do caminho para o endereço IP de front-end por meio das regras de balanceamento de carga e do pool de back-end para os aplicativos em execução em suas VMs. Essas informações são registradas como a métrica Disponibilidade do Caminho de Dados. A aplicação da métrica Média mostra a disponibilidade média de um determinado intervalo de tempo. Essa agregação é um valor entre 0 (sem disponibilidade) e 100, em que há pelo menos um caminho bem-sucedido disponível do endereço IP de front-end para uma VM no pool de back-end.
A métrica Status da Investigação de Integridade é semelhante, mas só se aplica à investigação de integridade para as VMs, em vez de ao caminho completo por meio do Load Balancer. Novamente, a agregação Média para essa métrica fornece um valor entre 0 (todas as VMs não estão íntegras e não respondem) e 100, em que todas as VMs estão respondendo à investigação de integridade.
A captura de tela a seguir mostra o gráfico para média de disponibilidade de caminho de dados e Status da Investigação de Integridade médio para um balanceador de carga com duas VMs no pool de back-end. Uma das máquinas não está respondendo à investigação de integridade. O Status da Investigação de Integridade médio está em torno de 50%.
Outra maneira de examinar essas métricas é usar a agregação Contagem. Essa abordagem pode fornecer outros insights sobre possíveis problemas de configuração. O exemplo a seguir mostra os grafos para a contagem das métricas Status da Investigação de Integridade e Disponibilidade do Caminho de Dados. O grafo mostra quantas investigações bem-sucedidas foram feitas ao longo do tempo.
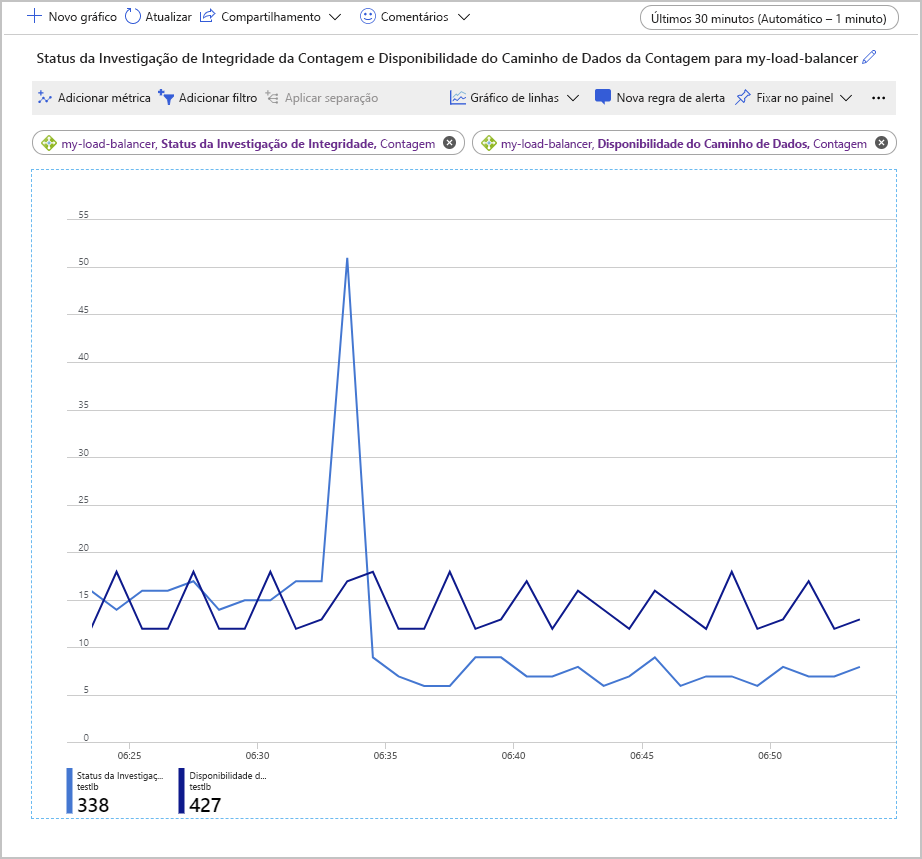
Um ponto interessante nesse gráfico é que o número de investigações bem-sucedidas de disponibilidade do caminho de dados permaneceu em um intervalo consistente. No entanto, o número de verificações bem-sucedidas de Status da Investigação de Integridade atingiu um pico momentâneo e então caiu para cerca de metade do valor anterior ao pico.
Na configuração usada para gerar esse grafo, o pool de back-end continha apenas duas VMs. Uma delas foi interrompida para simular uma falha. A métrica de Disponibilidade do Caminho de Dados mostra que ainda é possível que um aplicativo cliente se conecte ao aplicativo em execução na VM em operação restante. Porém, o Status da Investigação de Integridade indica que a integridade geral do pool de back-end é apenas metade do que era anteriormente.
Exibir integridade do Serviço
A página Resource Health para o Load Balancer relata o estado geral do sistema. Você acessa essa página no portal do Azure Monitor. Selecione Integridade do Serviço, selecione Resource Health e, em seguida, selecione Load Balancer como o tipo de recurso.
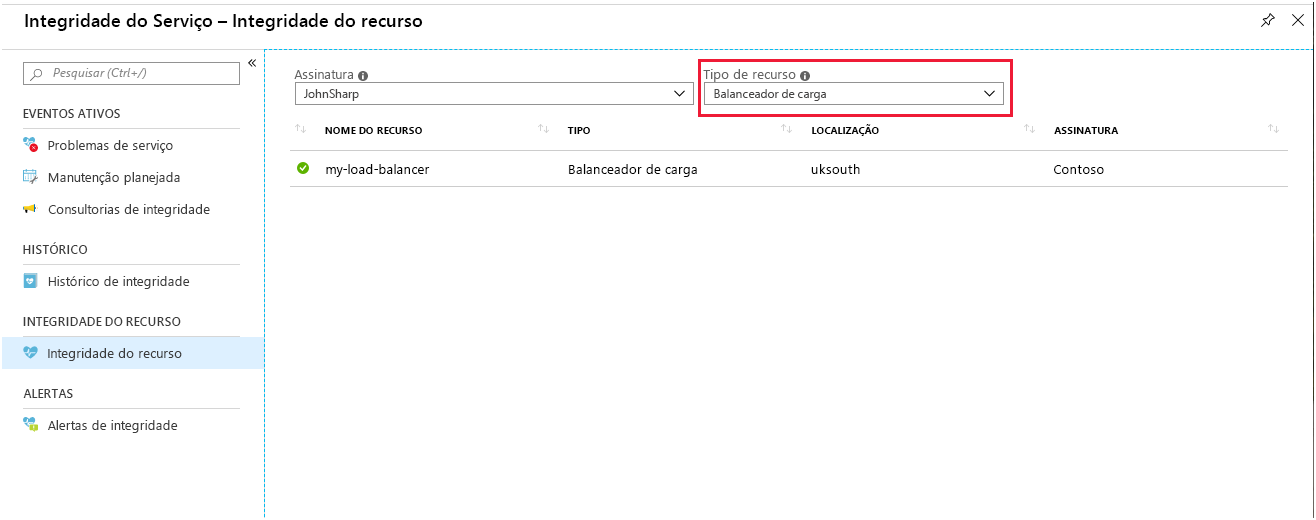
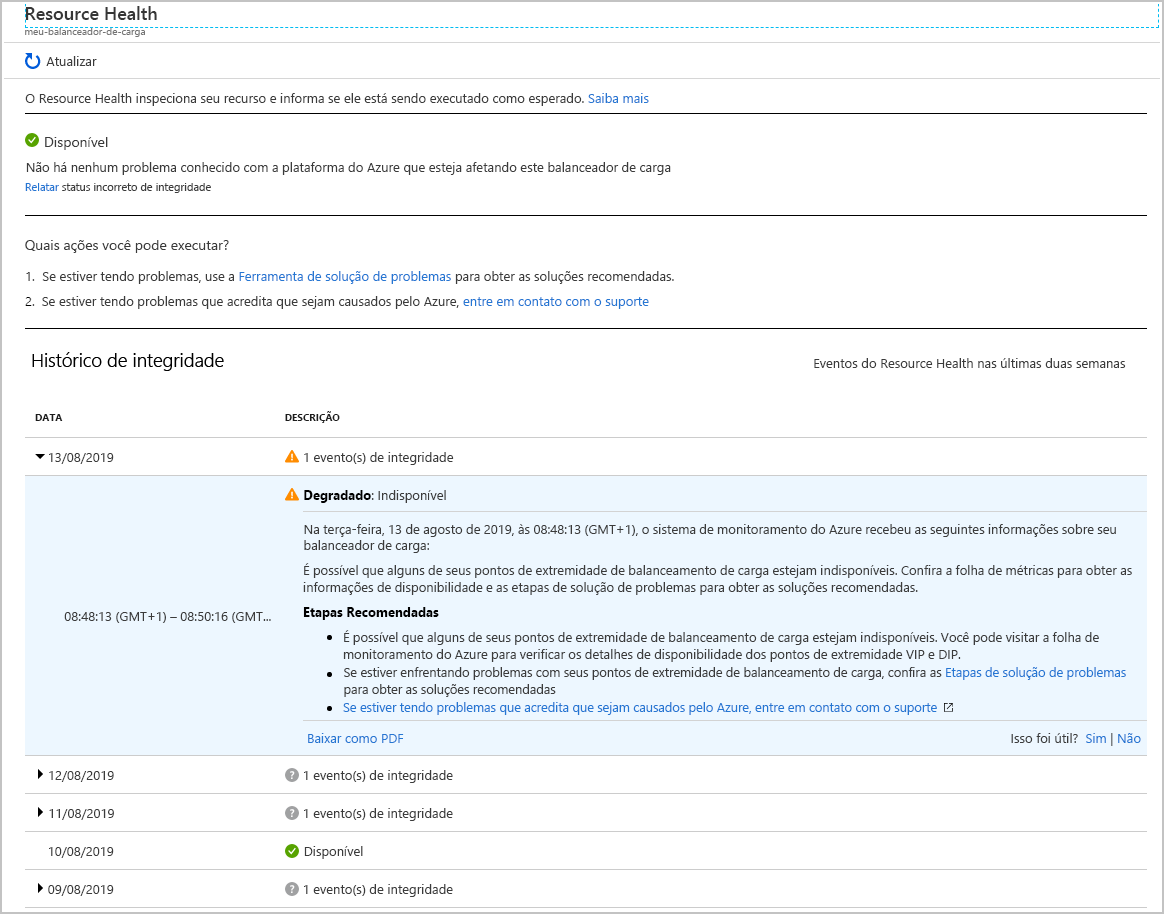
Selecione seu balanceador de carga. Você vê um relatório que detalha o histórico de integridade do serviço. Você pode expandir qualquer item no relatório para ver os detalhes. A imagem a seguir mostra o resumo gerado quando uma das VMs no pool de back-end foi colocada offline.
Monitorar a carga de trabalho por VM
As outras métricas disponíveis para o Load Balancer permitem que você acompanhe o número de bytes e pacotes de rede que passam pelo Load Balancer por front-end. Um front-end é definido como uma combinação do endereço IP do Load Balancer, o protocolo usado para aceitar solicitações de entrada e o número da porta usada pela regra de balanceamento de carga para conectar-se às VMs. Essas métricas podem fornecer uma medida da taxa de transferência do sistema por VM ativa.
O grafo a seguir mostra a contagem média de pacotes que fluem pelo Load Balancer durante a execução de uma carga de trabalho de teste de 500 usuários simultâneos por 2 minutos. A carga de trabalho foi executada duas vezes. Na primeira vez, o pool de back-end continha duas instâncias de VM. Para a segunda execução, uma das VMs foi desligada (simulando uma falha).
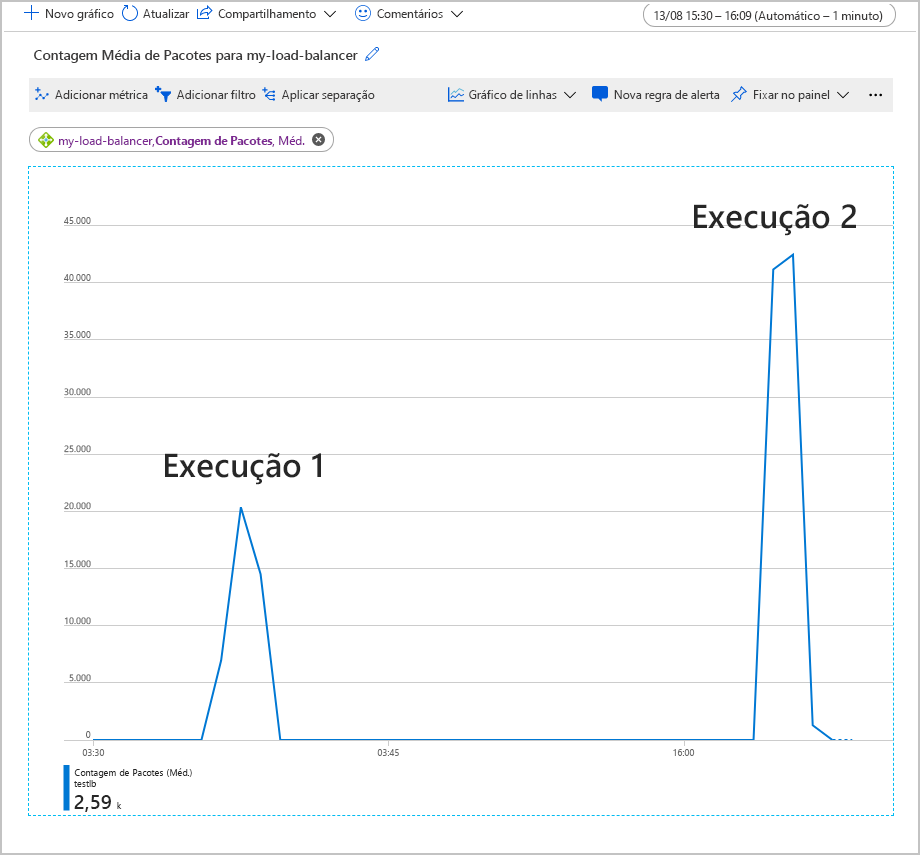
Neste gráfico, a contagem média de pacotes por front-end dobrava quando a VM era desligada. Esse volume de trabalho poderia sobrecarregar a VM restante, o que levaria a maiores tempos de resposta e possíveis tempos limite.
Investigar e corrigir problemas comuns com o Load Balancer
Esta seção aborda alguns cenários comuns de falha que você pode encontrar com o Load Balancer. Cada cenário resume os sintomas de uma falha e como você pode resolver o problema.
As VMs por trás do Load Balancer não estão respondendo ao tráfego na porta de investigação
Esse problema pode ser o resultado dos seguintes problemas:
As VMs no pool de back-end não estão escutando na porta de investigação correta.
Verifique se a investigação de integridade está definida corretamente no Load Balancer. Verifique se o código do aplicativo em execução em cada VM está respondendo adequadamente às solicitações de investigação. Ele deve retornar uma mensagem de resposta HTTP 200 (OK).
O NSG para a sub-rede da rede virtual que hospeda as VMs está bloqueando a porta de investigação.
Verifique a configuração do NSG para a sub-rede da rede virtual que contém as VMs. Verifique se o NSG permite que o tráfego do Load Balancer passe pela porta de investigação de integridade.
Você está tentando acessar o Load Balancer na mesma VM e na placa de rede virtual. Esse problema não está relacionado à investigação, mas é um cenário de caminho de dados sem suporte.
Você está tentando acessar o front-end do Load Balancer em uma VM no pool de back-end.
Esses dois itens são problemas de design de aplicativo. Evite enviar solicitações para a mesma instância do Load Balancer de uma VM no pool de back-end.
Uma VM no pool de back-end não está íntegra
Nesse caso, a maioria das VMs está respondendo normalmente, mas uma ou duas outras não estão. Como algumas VMs aceitam o tráfego, a investigação de integridade provavelmente está configurada corretamente. O NSG para a sub-rede não está bloqueando a porta usada pela investigação de integridade. O problema provavelmente está relacionado às VMs não íntegras. Esse problema pode ocorrer porque as VMs estão inacessíveis ou inativas ou há um problema de aplicativo nessas máquinas.
Use as seguintes etapas para determinar a causa do problema com uma VM não íntegra:
- Entre em uma VM não íntegra para verificar se ela está ativa. Verifique se a VM pode responder a verificações básicas, como solicitações de ping, rdp ou ssh de outra VM no pool de back-end.
- Se a VM estiver ativa e acessível, verifique se o aplicativo está em execução.
- Execute o comando
netstat -ane verifique se as portas usadas pela investigação de integridade e pelo aplicativo estão listadas como OUVINDO.
Configurações incorretas no Load Balancer
O Load Balancer exige que você configure corretamente as regras de roteamento que direcionam o tráfego de entrada do front-end para o pool de back-end. Se uma regra de roteamento estiver faltando ou não estiver configurada corretamente, o tráfego que chega ao front-end será descartado. Depois que o tráfego é descartado, o aplicativo é informado aos clientes como inacessível.
Valide a rota por meio do Load Balancer do pool de front-end para o de back-end. Você pode usar ferramentas como Ping, TCPing e netsh, que estão disponíveis para Windows e Linux. Você também pode usar o psping no Windows. As seções a seguir descrevem como usar essas ferramentas.
Usar o ping
O comando ping testa a conectividade ping por meio de um ponto de extremidade usando o protocolo ICMP. Para verificar se uma rota está disponível de seu cliente para uma VM por meio do Load Balancer, execute o comando a seguir. Substitua <ip address> pelo endereço IP da instância do Load Balancer.
ping -n 10 <ip address>
| Switch | Descrição |
|---|---|
| -n | Essa opção especifica o número de solicitações de ping a serem enviadas. |
A saída típica tem esta aparência:
ping -n 10 nn.nn.nn.nn
Pinging nn.nn.nn.nn with 32 bytes of data:
Reply from nn.nn.nn.nn: bytes=32 time=34ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Ping statistics for nn.nn.nn.nn:
Packets: Sent = 10, Received = 10, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 29ms, Maximum = 34ms, Average = 30ms
Usar PsPing
O comando PsPing testa a conectividade ping por meio de um ponto de extremidade. Esse comando também mede a latência e a disponibilidade da largura de banda para um serviço. Para verificar se uma rota está disponível de seu cliente para uma VM por meio do Load Balancer, execute o comando a seguir. Substitua <ip address> e <port> pelo endereço IP e a porta de front-end da instância do Load Balancer.
psping -n 100 -i 0 -q -h <ip address>:<port>
| Sinalizador | Descrição |
|---|---|
| -n | Especifica o número de pings a serem feitos. |
| -i | Indica o intervalo em segundos entre as iterações. |
| -q | Suprime a saída durante os pings. Apenas um resumo é mostrado no final. |
| -h | Imprime um histograma que mostra a latência das solicitações. |
A saída típica tem esta aparência:
TCP connect to nn.nn.nn.nn:nn:
101 iterations (warmup 1) ping test: 100%
TCP connect statistics for nn.nn.nn.nn:nn:
Sent = 100, Received = 100, Lost = 0 (0% loss),
Minimum = 7.48ms, Maximum = 9.08ms, Average = 8.30ms
Latency Count
7.48 3
7.56 2
7.65 2
7.73 2
7.82 7
7.90 4
7.98 4
8.07 6
8.15 9
8.24 9
8.32 11
8.40 7
8.49 11
8.57 12
8.66 3
8.74 2
8.82 2
8.91 1
8.99 2
9.08 1
Usar tcping
O utilitário tcping é semelhante a ping, exceto porque ele opera por uma conexão TCP em vez de ICMP. Use tcping da seguinte maneira:
tcping <ip address> <port>
A saída típica tem esta aparência:
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.042ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.810ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.266ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.181ms
Ping statistics for nn.nn.nn.nn:nn
4 probes sent.
4 successful, 0 failed. (0.00% fail)
Approximate trip times in milli-seconds:
Minimum = 9.042ms, Maximum = 9.810ms, Average = 9.325ms
Usar netsh
O utilitário netsh é uma ferramenta de configuração de rede de uso geral. Use o comando trace no netsh para capturar o tráfego de rede. Em seguida, faça uma análise usando uma ferramenta como o Wireshark. Use netsh trace para examinar os pacotes de rede enviados e recebidos por psping ao testar a conectividade por meio do Load Balancer da seguinte maneira:
Inicie um rastreamento de rede em um prompt de comando executando como administrador. O exemplo a seguir rastreia o tráfego do cliente da Internet (solicitações HTTP) de e para o endereço IP especificado. Substitua <ip address> pelo endereço da instância de Load Balancer. Os dados de rastreamento são gravados em um arquivo chamado trace.etl.
netsh trace start ipv4.address=<ip address> capture=yes scenario=internetclient tracefile=trace.etlExecute psping para testar a conectividade por meio do Load Balancer.
psping -n 100 -i 0 -q <ip address>:<port>Interrompa o rastreamento.
netsh trace stopA conclusão desse comando leva alguns minutos, pois ele correlaciona e mescla informações durante a criação do arquivo de saída de rastreamento.
Inicie o Wireshark e abra o arquivo de rastreamento.
Adicione o filtro a seguir ao rastreamento. Substitua <nn> pelo número da porta do front-end Load Balancer.
TCP.Port==80 or TCP.Port==<nn>Adicione os campos de origem e destino da solicitação HTTP como campos à saída do rastreamento.
Examine as mensagens de rastreamento:
- Caso não haja nenhum pacote de entrada para o Load Balancer, é provável que haja um problema de segurança de rede ou um problema de roteiros definidos pelo usuário.
- Se nenhum pacote de saída for retornado ao cliente, provavelmente haverá um problema de configuração de aplicativo ou um problema de roteiros definidos pelo usuário.
Firewall da VM ou NSG bloqueando a porta
Se a rede e o Load Balancer estiverem configurados corretamente, a VM estiver ativa e o aplicativo estiver em execução, a configuração do firewall ou do NSG para as VMs poderá estar bloqueando a porta usada pela investigação de integridade ou pelo aplicativo. Use as seguintes etapas para determinar se esse é o caso:
Se houver um firewall na VM, ele poderá estar bloqueando solicitações nas portas usadas pela investigação de integridade e pelo aplicativo. Valide a configuração do firewall no host para garantir que ele permita o tráfego nas portas usadas pela investigação de integridade e o aplicativo.
Verifique se algum NSG para a NIC da VM permite entrada e saída nas portas necessárias. Verifique se há uma regra Negar tudo no NSG na NIC da VM com prioridade mais alta do que a regra padrão.
Importante
Você pode associar um NSG a uma sub-rede e a NICs individuais de VMs na sub-rede. Você pode ter configurado o NSG para uma sub-rede para permitir que o tráfego passe por uma porta. No entanto, se o NSG de uma VM fechar essa mesma porta, as solicitações não passarão para essa VM.
Limitações do Load Balancer
O Load Balancer opera na camada 4 na pilha de rede ISO e não examina nem manipula o conteúdo de pacotes de rede. Você não pode usá-lo para implementar os roteiros baseados em conteúdo.
Todas as solicitações do cliente são encerradas por uma VM no pool de back-end. O Load Balancer é invisível aos clientes. Se nenhuma VM estiver disponível, a solicitação do cliente falhará. Os aplicativos cliente não podem se comunicar de outra forma com o status do Load Balancer ou os componentes dele nem interrogá-los.
Se você precisa implementar o balanceamento de carga com base no conteúdo das mensagens, considere usar o Gateway de Aplicativo do Azure. Outra opção é configurar um servidor Web proxy para lidar com solicitações de entrada de clientes e direcioná-las para VMs específicas.