Particionar arquivos de dados
O particionamento é uma técnica de otimização que permite ao Spark maximizar o desempenho entre os nós de trabalho. Mais ganhos de desempenho podem ser obtidos ao filtrar dados em consultas eliminando a E/S de disco desnecessária.
Particionar o arquivo de saída
Para salvar um dataframe como um conjunto particionado de arquivos, use o método partitionBy ao gravar os dados.
O exemplo a seguir cria um campo Year derivado. Em seguida, ele o usa para particionar os dados.
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
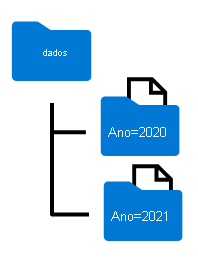
Os nomes de pastas gerados ao particionar um dataframe incluem o nome e o valor da coluna de particionamento em um formato column=value, conforme mostrado aqui:
Observação
Você pode particionar os dados por várias colunas, o que resulta em uma hierarquia de pastas para cada chave de particionamento. Por exemplo, você pode particionar o pedido no exemplo por ano e mês, para que a hierarquia de pastas inclua uma pasta para cada valor de ano, que, por sua vez, contém uma subpasta para cada valor de mês.
Filtrar os arquivos Parquet em uma consulta
Ao ler os dados de arquivos Parquet em um dataframe, você tem a capacidade de extrair dados de qualquer pasta das pastas hierárquicas. Esse processo de filtragem é feito com o uso de valores explícitos e curingas nos campos particionados.
No exemplo a seguir, o código a seguir extrairá os pedidos de vendas que foram feitos em 2020.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
Observação
As colunas de particionamento especificadas no caminho do arquivo são omitidas no dataframe resultante. Os resultados produzidos pela consulta de exemplo não incluirão uma coluna Year: todas as linhas serão de 2020.