Avaliar modelos de classificação
A exatidão do treinamento de um modelo de classificação é muito menos importante do que o desempenho de funcionamento do modelo quando receber novos dados não vistos. Afinal, treinamos modelos para que eles possam ser usados em novos dados que encontramos no mundo real. Por isso depois de treinarmos um modelo de classificação, vamos avaliar o desempenho dele em um conjunto de dados novos e não vistos.
Nas unidades anteriores, criamos um modelo que preveria se um paciente tinha diabetes ou não com base no nível de glicêmia no corpo. Agora, quando aplicados a alguns dados que não fazem parte do conjunto de treinamento, obteremos as seguintes previsões.
| x | a | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
Lembrando que x indica o nível de glicose no sangue, y indica se a pessoa é diabética ou não e ŷ indica a previsão do modelo sobre esses indivíduos serem diabéticos ou não.
Somente calcular quantas previsões estão corretas pode levar a enganos ou em uma representação muito simplista para que possamos entender os tipos de erros que cometeremos no mundo real. Para obter informações mais detalhadas, podemos tabular os resultados em uma estrutura chamada de matriz de confusão, desta forma:
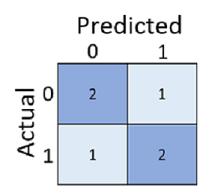
A confusion matrix mostra o número total de casos em que:
- O modelo previu 0, e o rótulo real é 0 (verdadeiros negativos, canto superior esquerdo)
- O modelo previu 1, e o rótulo real é 1 (verdadeiros positivos, canto inferior direito)
- O modelo previu 0, e o rótulo real é 1 (falsos negativos, canto inferior esquerdo)
- O modelo previu 1 e o rótulo real é 0 (falsos positivos, canto superior direito)
As células em uma matriz de confusão geralmente são sombreadas para que os valores mais altos tenham uma tonalidade mais profunda. Isso facilita a visualização de uma tendência diagonal forte da esquerda superior para a direita inferior, realçando as células em que o valor previsto e o valor real são os mesmos.
Com esses valores principais, você pode calcular uma variedade de outras métricas que podem ajudar a avaliar o desempenho do modelo. Por exemplo:
- Exatidão: (VP+VN)/(VP+VN+FP+FN) – de todas as previsões, quantas estavam corretas?
- Recall: VP/(VP+FN) – de todos os casos que são positivos, quantos o modelo identificou?
- Precisão: VP/(VP+FP) – de todos os casos que o modelo previu serem positivos, quantos são realmente positivos?