Indexar qualquer dado usando a API de push da Pesquisa de IA do Azure
A API REST é a maneira mais flexível de efetuar push de dados para um índice da Pesquisa de IA do Azure. Você pode usar qualquer linguagem de programação ou interagir qualquer aplicativo que possa postar solicitações JSON em um ponto de extremidade.
Aqui, você verá como usar a API REST com eficiência e explorará as operações disponíveis. Em seguida, você examinará o código do .NET Core e verá como otimizar a adição de grandes quantidades de dados por meio da API.
Operações da API REST com suporte
Duas APIs REST com suporte são fornecidas pela Pesquisa de IA. APIs de pesquisa e gerenciamento. Este módulo se concentra nas APIs REST de pesquisa que fornecem operações em cinco recursos de pesquisa:
| Recurso | Operations |
|---|---|
| Índice | Criar, excluir, atualizar e configurar. |
| Documento | Obter, adicionar, atualizar e excluir. |
| Indexador | Configurar fontes de dados e agendamento em fontes de dados limitadas. |
| Conjunto de habilidades | Obter, criar, excluir, listar e atualizar. |
| Mapa de sinônimos | Obter, criar, excluir, listar e atualizar. |
Como chamar a API REST de pesquisa
Se você quiser chamar qualquer uma das APIs de pesquisa, precisará:
- Use o ponto de extremidade HTTPS (na porta padrão 443) fornecido pelo serviço de pesquisa. Você deve incluir uma versão de API no URI.
- O cabeçalho da solicitação deve incluir um atributo api-key.
Para localizar o ponto de extremidade, a versão da API e a chave da API, acesse o portal do Azure.

No portal, navegue até o serviço de pesquisa e selecione Gerenciador de pesquisa. O ponto de extremidade da API REST está no campo URL de Solicitação. A primeira parte da URL é o ponto de extremidade (por exemplo, https://azsearchtest.search.windows.net), e a cadeia de consulta mostra o api-version (por exemplo, api-version=2023-07-01-Preview).

Para localizar o api-key à esquerda, selecione Chaves. A chave de administração primária ou secundária poderá ser usada se você estiver usando a API REST para fazer mais do que apenas consultar o índice. Se você precisar apenas pesquisar um índice, poderá criar e usar chaves de consulta.
Para adicionar, atualizar ou excluir dados em um índice, você precisa usar uma chave de administração.
Adicionar dados a um índice
Use uma solicitação HTTP POST usando o recurso de índices neste formato:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
O corpo da solicitação precisa informar ao ponto de extremidade REST a ação a ser tomada no documento, a qual documento aplicar a ação e quais dados usar.
O JSON deve estar neste formato:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Ação | Descrição |
|---|---|
| upload | Semelhante a um upsert no SQL, o documento será criado ou substituído. |
| merge | A mesclagem atualiza um documento existente com os campos especificados. A mesclagem falhará se nenhum documento puder ser encontrado. |
| mergeOrUpload | A mesclagem atualiza um documento existente com os campos especificados e o carrega quando o documento não existe. |
| delete | Exclui todo o documento; você só precisa especificar o key_field_name. |
Se a solicitação for bem-sucedida, a API retornará o código de status 200.
Observação
Para obter uma lista completa de todos os códigos de resposta e mensagens de erro, consulte Adicionar, atualizar ou excluir documentos (API REST da Pesquisa de IA do Azure)
Este exemplo de JSON carrega o registro do cliente na unidade anterior:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
Você poderá adicionar quantos documentos na matriz de valores desejar. No entanto, para obter o desempenho ideal, considere o envio em lote dos documentos em suas solicitações, até um máximo de 1.000 documentos ou 16 MB de tamanho total.
Usar o .NET Core para indexar dados
Para obter o melhor desempenho, use a biblioteca de clientes Azure.Search.Document mais recente, atualmente versão 11. Você pode instalar a biblioteca de clientes com o NuGet:
dotnet add package Azure.Search.Documents --version 11.4.0
O desempenho do índice é baseado em seis fatores principais:
- A camada de serviço de pesquisa e as réplicas e partições que você habilitou.
- A complexidade do esquema de índice. Reduza quantas propriedades (pesquisável, facetável, classificável) cada campo tem.
- O número de documentos em cada lote, o melhor tamanho dependerá do esquema de índice e do tamanho dos documentos.
- O quanto sua abordagem é multithreaded.
- Manipular erros e limitação. Usar uma estratégia de repetição de retirada exponencial.
- Onde seus dados residem, tente indexar os dados o mais próximos possível ao índice de pesquisa. Por exemplo, execute uploads de dentro do ambiente do Azure.
Determinar o tamanho do lote ideal
Como determinar o melhor tamanho do lote é um fator-chave para aprimorar o desempenho, vamos examinar uma abordagem no código.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
A abordagem é aumentar o tamanho do lote e monitorar o tempo necessário para receber uma resposta válida. O código faz loops de 100 a 1000, em etapas de 100 documentos. Para cada tamanho de lote, ele gera o tamanho do documento, o tempo para obter uma resposta e o tempo médio por MB. A execução deste código fornece resultados como este:
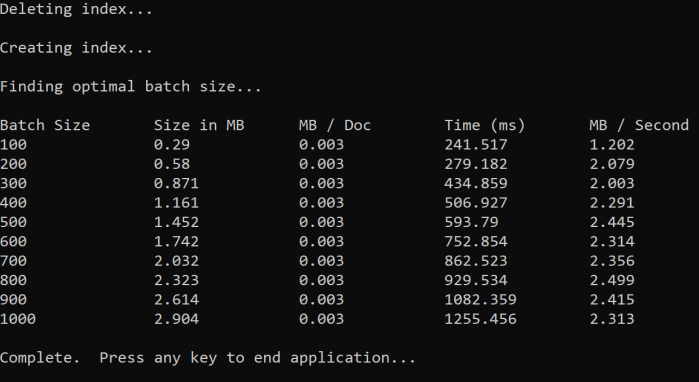
No exemplo acima, o melhor tamanho do lote para a taxa de transferência é de 2.499 MB por segundo, 800 documentos por lote.
Implementa uma estratégia de repetição de retirada exponencial
Se o índice começar a limitar as solicitações devido a sobrecargas, ele responderá com um status 503 (solicitação rejeitada devido à carga pesada) ou 207 (alguns documentos falharam no lote). Você precisa lidar com essas respostas e uma boa estratégia é a retirada. Retirada significa pausar por algum tempo antes de repetir a solicitação novamente. Se você aumentar esse tempo para cada erro, fará a retirada exponencialmente.
Examine este código:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
O código mantém o controle dos documentos com falha em um lote. Se ocorrer um erro, ele aguardará um atraso e, em seguida, dobrará o atraso para o próximo erro.
Por fim, há um número máximo de tentativas e, se esse número máximo for atingido, o programa será encerrado.
Usar threading para aprimorar o desempenho
Você pode concluir o aplicativo de carregamento de documentos combinando a estratégia de retirada acima com uma abordagem de threading. Veja alguns exemplos de código:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Esse código usa chamadas assíncronas para uma função ExponentialBackoffAsync que implementa a estratégia de retirada. Você chama a função usando threads, por exemplo, o número de núcleos que o processador tem. Quando o número máximo de threads for usado, o código aguardará a conclusão de algum thread. Em seguida, ele criará um thread até que todos os documentos sejam carregados.