Indexar dados de fontes de dados externas usando o Azure Data Factory
Adicionar dados externos que não residem no Azure é uma necessidade comum na solução de pesquisa de uma organização. A Pesquisa de IA do Azure é flexível, pois proporciona muitas maneiras de criar e enviar dados por push para índices.
Efetuar push de dados para um índice de pesquisa usando o ADF (Azure Data Factory)
Uma primeira abordagem é uma opção de código zero para efetuar push de dados para um índice usando o ADF. O ADF vem com conexões com quase 100 armazenamentos de dados diferentes. Com conectores como HTTP e REST que permitem conectar um número ilimitado de armazenamentos de dados. Esses armazenamentos de dados são usados como uma origem ou um destino (chamados coletores na atividade de cópia) nos pipelines.
O conector de índice da Pesquisa de IA do Azure pode ser usado como um coletor em uma atividade de cópia.
Criar um pipeline do ADF para efetuar push de dados para um índice de pesquisa
As etapas que você precisa executar para usar um pipeline do ADF para efetuar push de dados para um índice de pesquisa são:
- Criar um índice da Pesquisa de IA do Azure com todos os campos nos quais você deseja armazenar dados.
- Criar um pipeline com uma etapa de cópia de dados.
- Criar uma conexão entre a fonte de dados e onde seus dados residem.
- Criar um coletor para conectar ao índice de pesquisa.
- Mapear os campos dos dados de origem para o índice de pesquisa.
- Executar o pipeline para efetuar push de dados para o índice.
Por exemplo, imagine que você tenha dados do cliente no formato JSON hospedados externamente. Você deseja copiar esses clientes para um índice de pesquisa. O JSON tem este formato:
{
"_id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": 1558
},
"phoneNumbers": [
{
"type": "home",
"number": "+1 (830) 465-2965"
},
{
"type": "home",
"number": "+1 (889) 439-3632"
}
]
}
Criar um índice de pesquisa
Crie um serviço da Pesquisa de IA do Azure e um índice no qual armazenar essas informações. Se você concluiu o módulo Criar uma solução da Pesquisa de IA do Azure, você viu como fazer isso. Siga as etapas para criar o serviço de pesquisa, mas pare no ponto de importação dos dados. Efetuar push de dados para um índice não demanda que você crie um indexador ou um conjunto de habilidades.
Crie um índice e adicione estes campos e propriedades:

No momento, você precisa criar o índice primeiro, pois o ADF não pode criar índices.
Criar um pipeline usando a ferramenta Copiar Dados do ADF
Abra o Azure Data Factory Studio e selecione a assinatura do Azure e o nome do data factory.

Selecione Ingerir.
Selecione Avançar.
Observação
Você poderá optar por agendar o pipeline se os dados estiverem mudando e você precisar manter o índice atualizado. Para este exemplo, você importará os dados uma vez.
Criar o serviço vinculado de origem
Em Tipo de origem, selecione HTTP.
Ao lado de Conexão, selecione + Nova conexão.
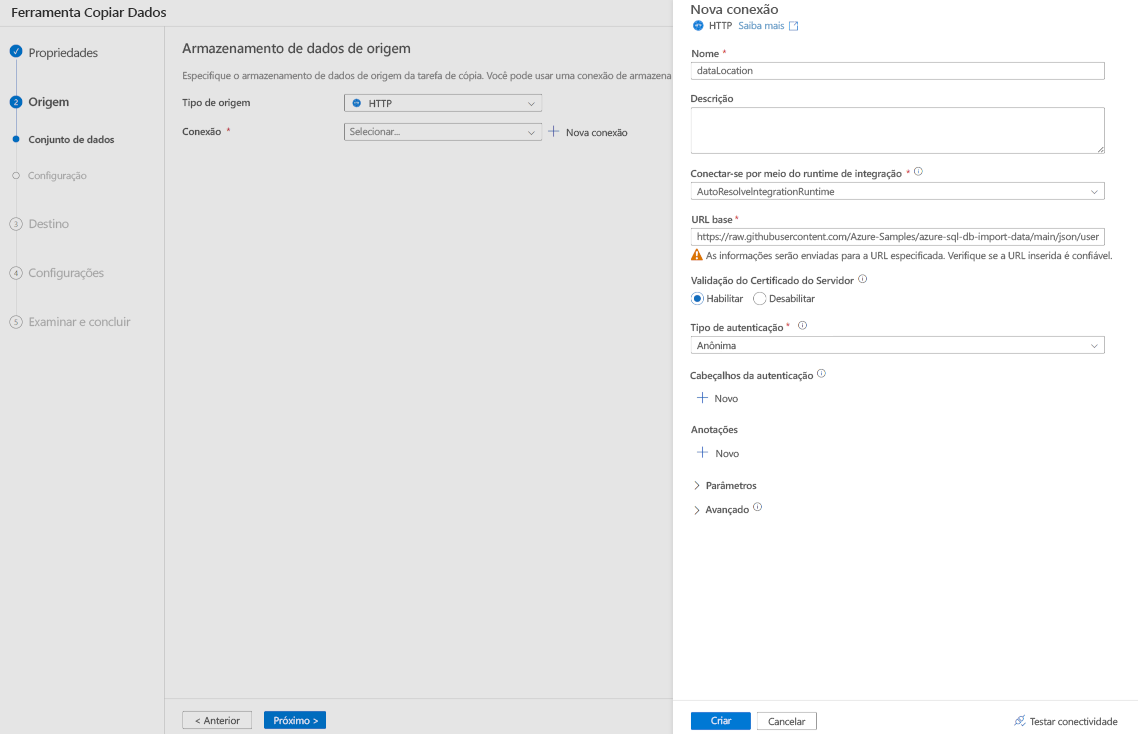
No painel Nova conexão, em Nome insira dataLocation.
Em URL Base, insira onde o arquivo JSON reside, neste exemplo, insira https://raw.githubusercontent.com/Azure-Samples/azure-sql-db-import-data/main/json/user1.json.
Em Tipo de autenticação, selecione Anônimo.
Selecione Criar.
Selecione Avançar.
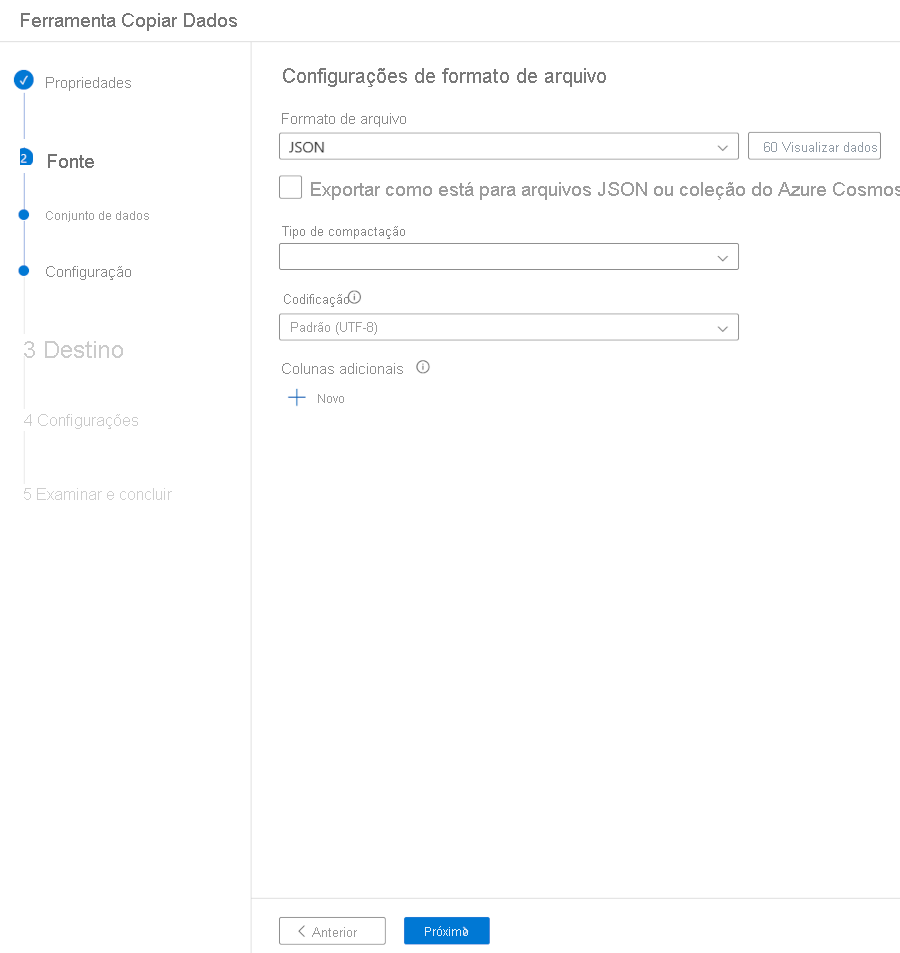
No Formato de arquivo, selecione JSON.
Selecione Avançar.


Criar o serviço vinculado de destino
Em Tipo de destino, selecione Pesquisa do Azure. Em seguida, selecione + Nova conexão.
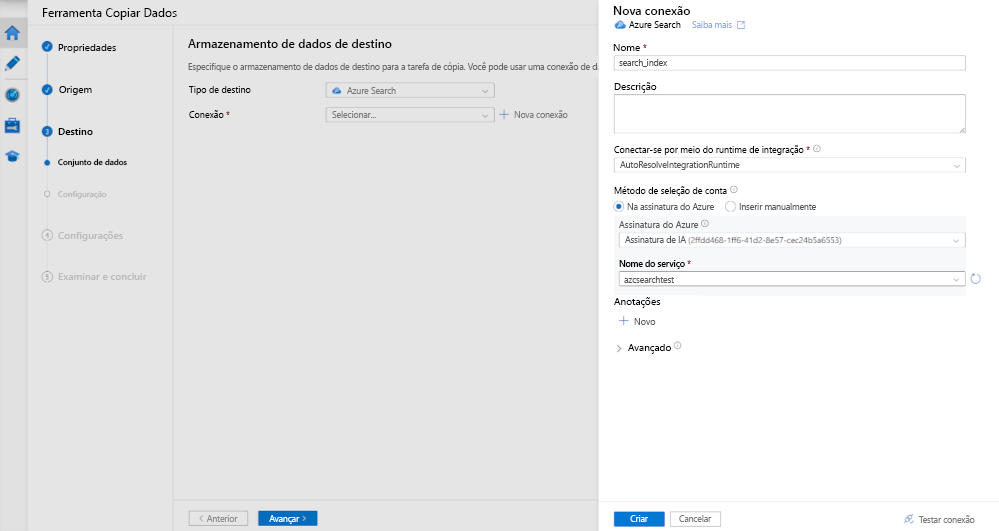
No painel Nova conexão, em Nome insira search_index.
Em Assinatura do Azure, selecione sua assinatura do Azure.
Em Nome do serviço, selecione seu serviço da Pesquisa de IA do Azure.
Selecione Criar.
No painel Armazenamento de dados de destino, em Destino, selecione o índice de pesquisa que você criou.

Mapear campos de origem para campos de destino
Selecione Avançar.
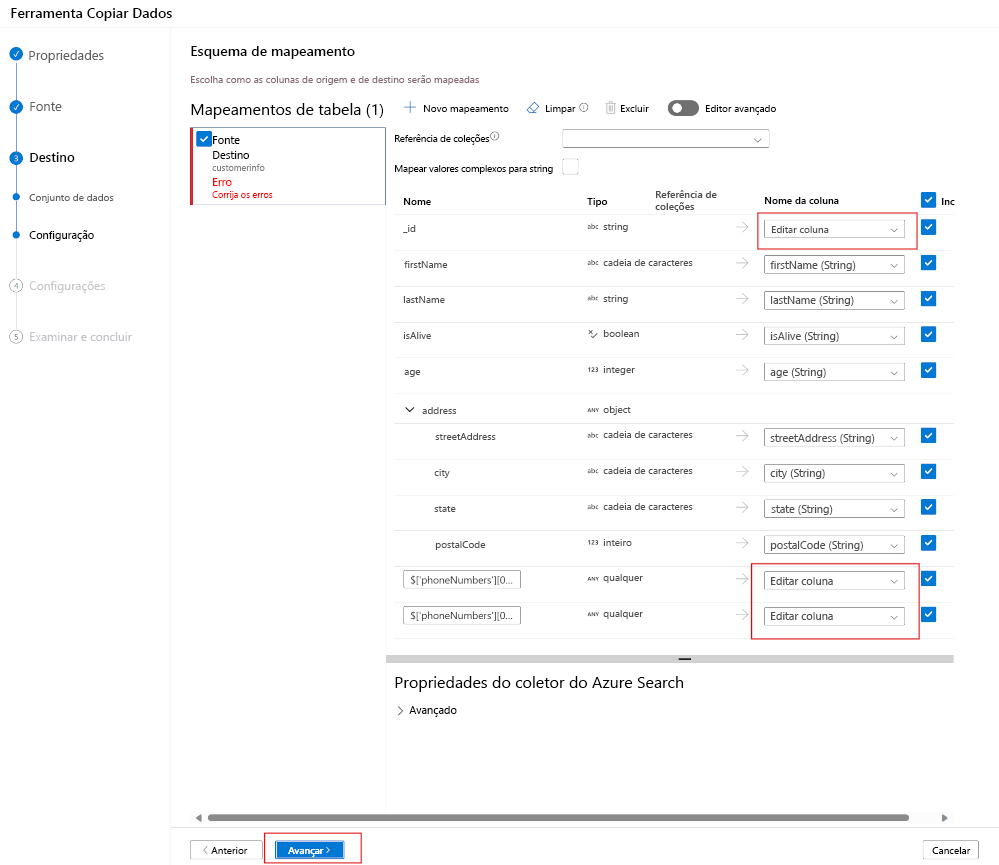
Se você criou um índice com nomes de campo que correspondem aos atributos JSON, o ADF mapeará automaticamente o JSON para o campo no índice de pesquisa.
No exemplo acima, três campos no documento JSON precisam ser mapeados para campos no índice.
Mapeie seus campos e selecione Avançar.
No painel Configurações, em Nome da tarefa, insira jsonToSearchIndex.
Selecione Avançar.

Executar o pipeline para efetuar push de dados para o índice
No painel Resumo, selecione Avançar.
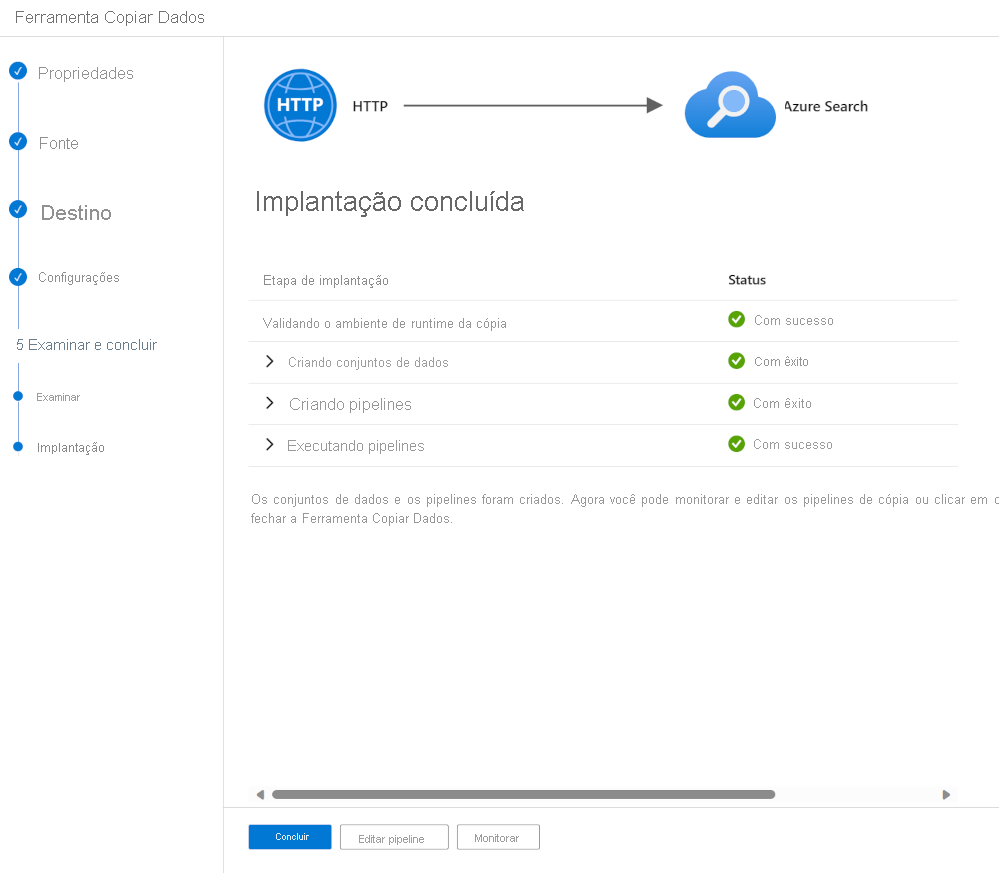
Após o pipeline ser validado e implantado, selecione Concluir.

O pipeline foi implantado e executado. O documento JSON terá sido adicionado ao índice de pesquisa. Você pode usar o portal do Azure e executar uma pesquisa no gerenciador de pesquisa. Você deverá ver os dados JSON importados.

Seguindo estas etapas, você viu como efetuar push de dados para um índice. O pipeline que você criou, por padrão, mescla atualizações no índice. Se você alterasse os dados JSON e executasse o pipeline novamente, o índice de pesquisa seria atualizado. Você poderá alterar o comportamento de gravação para somente carregar se quiser que os dados sejam substituídos sempre que executar o pipeline.
Limitações de usar a Pesquisa de IA do Azure interna como um serviço vinculado
No momento, o serviço vinculado da Pesquisa de IA do Azure como coletor dá suporte apenas a estes campos:
| Tipo de dados do Azure AI Search |
|---|
| String |
| Int32 |
| Int64 |
| Double |
| Booliano |
| DataTimeOffset |
Isso significa que não há suporte para ComplexTypes e matrizes no momento. Examinar o documento JSON acima significa que não é possível mapear todos os números de telefone para o cliente. Somente o primeiro número de telefone foi mapeado.