Visão geral do Azure Site Recovery
O Azure Site Recovery é mais do que apenas uma ferramenta para ajudar você a se recuperar de interrupções do sistema. O Azure Site Recovery replica cargas de trabalho entre um site primário e secundário. O Site Recovery também pode ser usado para migrar VMs da infraestrutura local para o Azure.
Sua primeira tarefa para proteger as cargas de trabalho contra terremotos, por exemplo, é examinar o plano atual de BCDR (continuidade dos negócios e recuperação de desastres) da empresa. É necessário identificar os diferentes objetivos de recuperação e o escopo dos sistemas que precisam de proteção.
Nesta unidade, você investigará como o Azure Site Recovery pode ajudar a alcançar essas metas e possibilitar o failover e a recuperação de recursos se ocorrer um desastre.
Continuidade dos negócios e recuperação de desastres
A perda de serviço pode causar interrupção à sua equipe e aos usuários. Cada segundo em que os sistemas não estão disponíveis pode resultar em perda de receita para sua empresa. Sua empresa também pode sofrer multas financeiras por quebra de contratos de disponibilidade dos serviços prestados.
Os planos BCDR são documentos formais que as empresas elaboram para abranger o escopo e as ações que devem ser tomadas quando ocorre um desastre ou uma interrupção de grande escala. Cada interrupção é avaliada de acordo com seu próprio mérito. Por exemplo, um plano de BCDR entra em ação quando um datacenter inteiro fica sem energia.
Neste exemplo de cenário, ocorreu um terremoto que danificou as linhas de comunicação, inutilizando o datacenter que necessita de reparos. Um desastre dessa proporção pode tornar os serviços inoperantes por dias, não horas; portanto, um plano de BCDR completo precisa ser invocado para colocar o serviço online novamente.
Como parte do plano de BCDR, identifique os RTOs (objetivos de tempo de recuperação) e os RPOs (objetivos de ponto de recuperação) dos aplicativos. Esses dois objetivos, em conjunto, ajudam a identificar o máximo de horas toleráveis durante as quais os negócios podem ficar sem os serviços especificados e indica qual deve ser o processo de recuperação de dados. Vamos examinar mais detalhadamente cada um deles.
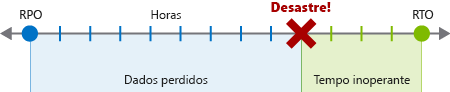
Objetivo de tempo de recuperação
Um RTO é uma medida da quantidade máxima de tempo que sua empresa pode sobreviver após um desastre até que o serviço normal seja restaurado para evitar consequências inaceitáveis associadas a uma quebra de continuidade. Vamos supor que o RTO seja de 12 horas, o que significa que as operações podem continuar por 12 horas sem o funcionamento dos serviços principais dos negócios. Se o tempo de inatividade for maior, os negócios ficariam seriamente prejudicados.
Objetivo de ponto de recuperação
Um RPO é uma medida do volume máximo de perda de dados aceitável após um desastre. Normalmente, uma empresa pode decidir fazer um backup a cada 24 horas, 12 horas ou até mesmo em tempo real. Em caso de desastre, sempre haverá alguma perda de dados.
Por exemplo, se o backup ocorresse à meia-noite a cada 24 horas e um desastre ocorrer às 9h, nove horas de dados seriam perdidas. Se o RPO de sua empresa fosse de 12 horas, não haveria problemas porque apenas nove horas se passaram. No entanto, se o RPO fosse de quatro horas, isso seria um problema e acarretaria danos à empresa.
O que é o Azure Site Recovery?
O Azure Site Recovery pode contribuir com seu plano de BCDR porque pode replicar cargas de trabalho de um site primário para um site secundário. Se ocorrer um problema no site primário, o Site Recovery poderá ser invocado automaticamente para replicar as máquinas virtuais protegidas em outra localização. O failover poderá ser feito do local para o Azure ou de uma região do Azure para outra.
Alguns recursos importantes do Azure Site Recovery são:
- Gerenciamento central: a replicação pode ser configurada e gerenciada, e o failover e o failback podem ser invocados no portal do Azure.
- Replicação de máquina virtual local: As máquinas virtuais locais podem ser replicadas no Azure ou em um datacenter local secundário, se necessário.
- Replicação de máquina virtual do Azure: As máquinas virtuais do Azure podem ser replicadas de uma região para outra.
- Consistência do aplicativo durante o failover: Com o uso de pontos de recuperação e instantâneos consistentes com o aplicativo, as máquinas virtuais são sempre mantidas em um estado consistente durante a replicação.
- Failover flexível: Os failovers podem ser executados sob demanda como um teste ou disparados durante um desastre real. Os testes podem ser executados para simular um cenário de recuperação de desastre sem a interrupção do serviço dinâmico.
- Integração de rede: O Site Recovery pode cuidar do gerenciamento de rede durante um cenário de replicação e recuperação de desastre. Os endereços IP Reservados e os balanceadores de carga estão incluídos, de modo que as máquinas virtuais possam funcionar na nova localização.
Configurar o Azure Site Recovery

Vários componentes precisam ser configurados para habilitar o Azure Site Recovery:
- Rede: Uma rede virtual válida do Azure é necessária para uso das máquinas virtuais replicadas.
- Cofre dos Serviços de Recuperação: Um cofre em sua assinatura do Azure armazena as VMs migradas quando um failover é executado. O cofre também contém a política de replicação e as localizações de origem e destino para replicação e failover.
- Credenciais: As credenciais que você usa para o Azure precisam ter as funções Colaborador da Máquina Virtual e Colaborador do Site Recovery para que a permissão possa modificar a VM e o armazenamento aos quais o Site Recovery está conectado.
- Servidor de configuração: Um servidor VMware local desempenha várias funções durante o processo de failover e replicação. Ele é obtido no portal do Azure como um OVA (dispositivo de máquina virtual aberta) para facilitar a implantação. O servidor de configuração inclui um:
- Servidor de processo: Esse servidor funciona como um gateway para o tráfego de replicação. Ele armazena em cache, compacta e criptografa o tráfego antes de enviá-lo pela WAN para o Azure. O servidor de processo também instala o Serviço de Mobilidade em todas as máquinas virtuais e todos os computadores físicos direcionados para failover e replicação.
- Servidor de destino mestre: Esse computador cuida do processo de replicação durante um failback do Azure.
Importante
Para fazer failback do Azure em um ambiente local, o VMware vCenter com um servidor de configuração precisará estar disponível mesmo se você estiver apenas replicando computadores físicos para o Azure. Não é possível fazer failback para servidores físicos.
Processo de replicação
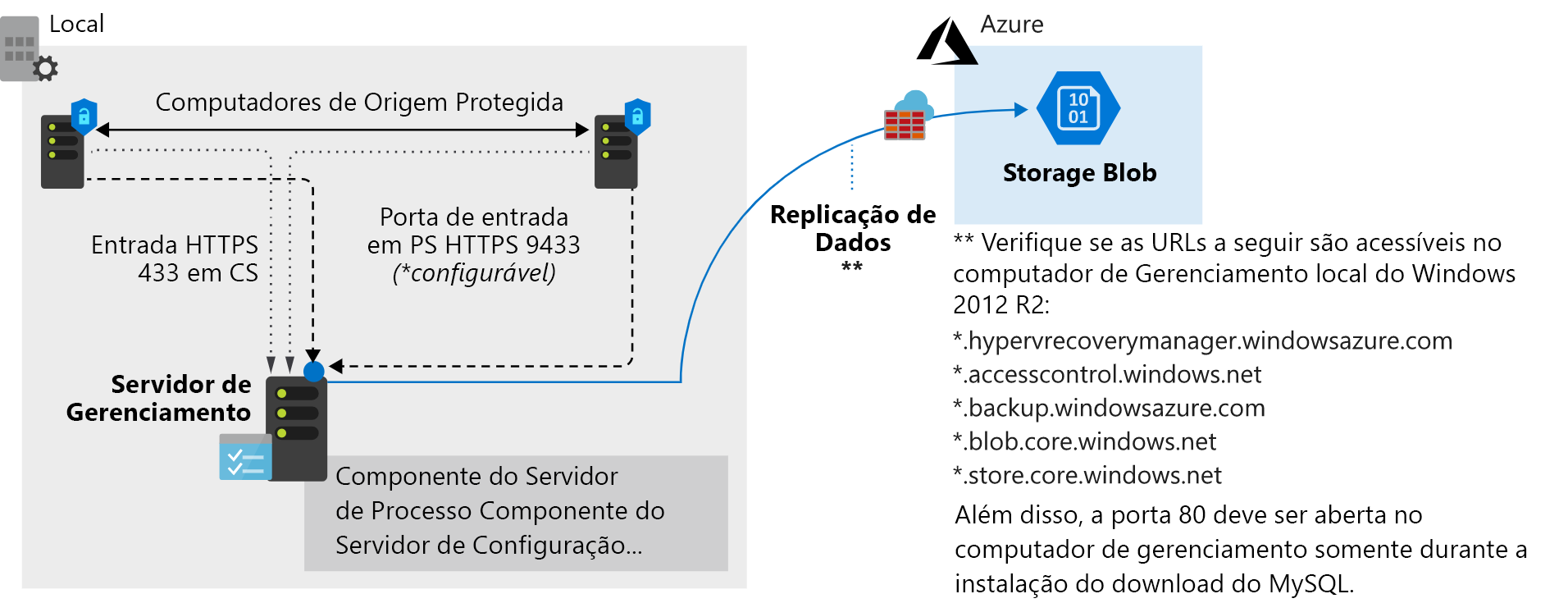
Depois que as tarefas de pré-requisito forem configuradas, a replicação dos computadores poderá ser iniciada. Eles são replicados de acordo com a política de replicação em vigor. Durante os estágios iniciais da primeira cópia, os dados do servidor são replicados para o Armazenamento do Azure. Depois que a replicação inicial for concluída, ocorrerá uma segunda replicação. Desta vez, as alterações delta na máquina virtual são replicadas para o Azure.
Testar e monitorar um failover
Depois que o ambiente estiver configurado para a recuperação de desastre, teste-o para verificar se ele foi configurado corretamente e se tudo funciona conforme esperado. Teste a configuração fazendo uma análise de recuperação de desastre em uma VM isolada. É uma melhor prática usar uma rede isolada para o teste, de modo que os serviços dinâmicos não sejam interrompidos.
A primeira tarefa ao tentar fazer uma análise de recuperação é verificar as propriedades da máquina virtual de teste na seção Itens Protegidos do portal do Azure. Os últimos pontos de recuperação são exibidos no painel Item Replicado. Na seção Computação e Rede, o nome da máquina virtual, o grupo de recursos, o tamanho de destino, o conjunto de disponibilidade e as configurações do disco podem ser ajustados, se necessário.
As análises de recuperação podem ser iniciadas na seção Configurações>Itens Replicados do portal do Azure. Selecione a máquina virtual de destino e, em seguida, o item de menu Failover de Teste do último ponto de recuperação processado. Selecione a rede do Azure no mesmo menu. Para iniciar o trabalho de recuperação, selecione OK na tela de seleção de rede.
O status do trabalho de recuperação e a máquina virtual replicada são acessados por meio da seção Visão Geral do cofre dos Serviços de Recuperação. Os itens replicados têm um status igual a:
- Íntegro: A replicação está funcionando normalmente.
- Aviso: Há um problema que pode afetar a replicação.
- Crítico: Foi detectado um erro de replicação crítico.
Se tudo correr bem, o status da VM replicada será definido como Executado com êxito. Se um teste não tiver sido feito, o status será definido como Teste recomendado. A VM também será definida como Teste recomendado se mais de seis meses tiverem decorrido desde o último teste.