Executar uma análise de recuperação de desastre
Nesta unidade, você aprenderá sobre os exercícios de desastre do Site Recovery: o que você precisa considerar e como executar um teste para verificar se a configuração está correta.
É possível usar análises de DR (recuperação de desastre) para testar a capacidade da organização de se recuperar de uma interrupção sem afetar nenhum serviço de produção.
No exercício anterior, você concluiu a configuração do Azure Site Recovery e agora precisa testar a replicação da infraestrutura. Teste sua configuração executando uma análise de DR. O Azure Site Recovery permite executar essas análises de modo seguro sem afetar o ambiente de produção. Você também executará alguns testes de garantia de qualidade na configuração para garantir que a solução de DR esteja funcionando.
O que é uma análise de recuperação de desastre?
A análise de DR é um modo de verificar se você configurou a solução corretamente. A análise deve dar a você e à sua empresa confiança de que seus dados e serviços estão disponíveis mesmo se ocorrer um desastre. Normalmente, as organizações configuram um RTO (objetivo de tempo de recuperação), que indica quanto tempo será necessário para recuperar a infraestrutura. Sua empresa também deve definir um RPO (objetivo de ponto de recuperação), que determina a quantidade de perda de dados aceitável em função do tempo. Por exemplo, se o RPO da empresa for de um dia, você precisará criar um backup de todos os dados todos os dias. Também será necessário verificar se a restauração desse backup vai demorar menos de um dia.

O Site Recovery envia avisos de modo ativo em seu respectivo painel para garantir que executaremos os testes de DR.
Por que você deve executar uma análise de DR?
Uma análise de DR é essencial para garantir que a solução implementada atenda aos requisitos de BCDR (continuidade dos negócios e recuperação de desastres) e que a replicação funcione corretamente. Sua análise de recuperação de desastre, combinada com RTO e RPO, deve ser testada minuciosamente para garantir que a replicação, o failover e a recuperação ocorram no período necessário.
Por exemplo, vamos supor que o RTO seja de uma hora e o RPO seja de seis horas. Caso os sistemas façam backups a cada hora, isso significará uma hora de dados perdidos, além de uma hora adicional para recuperar seus sistemas.
Imagine que o tempo de recuperação real seja de cinco horas. Seus sistemas estão agora próximos de estarem desatualizados em mais de seis horas, o que significa que você estará violando o objetivo RPO de BCDR. Testar o tempo real necessário para se recuperar de falhas pode oferecer a confiança de que os sistemas seguem seus planos de BCDR.
Failover de teste de computadores individuais
Um teste de failover permite que você simule um desastre e veja seus efeitos. Você pode iniciar um teste de failover no painel do Site Recovery ou diretamente no menu de recuperação de desastre em uma VM específica. Você começará escolhendo um ponto de recuperação. É possível escolher entre o ponto processado pela última vez, o ponto mais recente e consistente com o aplicativo ou um ponto de recuperação personalizado.
Criar um teste de failover
Crie uma rede virtual isolada para que a infraestrutura de produção não seja afetada. Para fazer isso, siga estas etapas:
Abra a VM de destino chamada patient-records. Uma forma fácil de descobrir isso é filtrar todos os recursos para mostrar apenas o Tipo = Máquina virtual. Selecione patient-records na lista de resultados.
No menu de recursos, role até Operações e selecione Recuperação de desastre.
Um novo painel de Itens replicados será exibido. Selecione Atualizar até ver Protegido no campo de status. Em seguida, na barra de menus superior, escolha Failover de Teste.
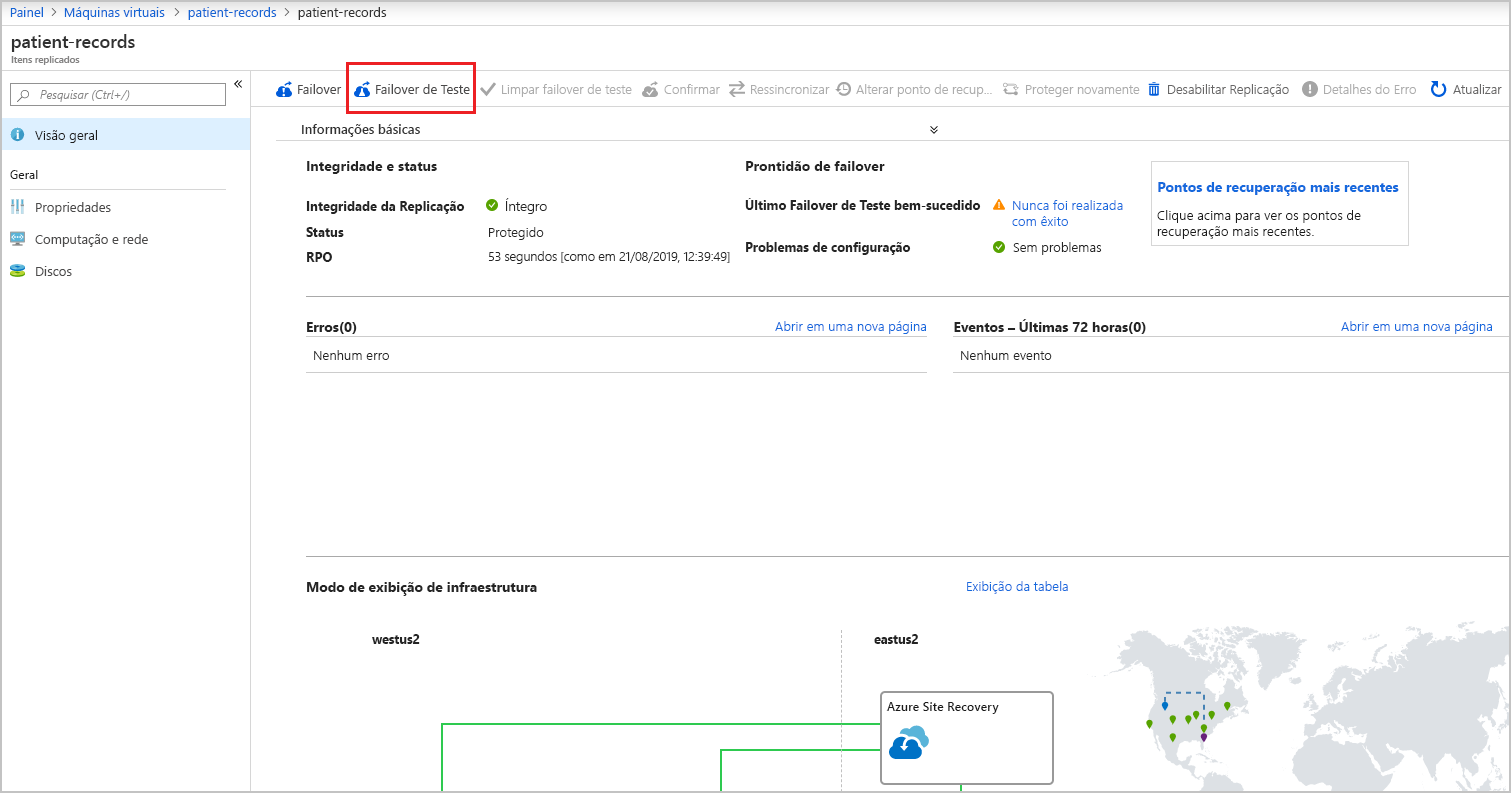
Depois que a validação for bem-sucedida, selecione sua rede virtual na lista suspensa da rede virtual do Azure e selecione o botão Failover de teste. Essa opção executa um failover de teste da VM e permite que você acompanhe seu progresso por meio da página de trabalhos do Site Recovery selecionando o ícone Notificações e selecionando o link Iniciar a tarefa para executar o failover de teste da máquina virtual.
Após a conclusão, a VM com failover aparecerá no portal em Máquinas Virtuais, na região de recuperação. Será possível verificar se a VM está em execução, foi dimensionada e conectada de modo correto e se está espelhando a VM de origem, porém em uma região do Azure diferente.
Depois de validar que tudo funcionou conforme o esperado, você pode excluir a VM replicada selecionando Limpeza do failover de teste no painel Recuperação de desastre. Neste ponto, recomendamos adicionar anotações sobre o resultado do teste. Marque a caixa ao lado de Testes concluídos para excluir a máquina virtual de failover de teste e selecione OK.


Failover flexível de vários computadores
O Site Recovery oferece a flexibilidade de executar um cenário de teste de DR completo para todas as VMs. É possível criar planos de recuperação que incluem uma ou mais VMs. Os failovers podem ser executados quantas vezes você desejar. Além disso, eles permitem obter uma política flexível para testar diferentes combinações de infraestruturas.

Assim como testar as VMs únicas, a mesma limpeza de teste está disponível para tudo incluído no plano de recuperação.

Diferença entre um failover de análise e de produção
Executar um failover de produção no Site Recovery é semelhante a uma análise de teste. No entanto, há algumas exceções. A primeira delas é que o Failover será selecionado, em vez do Failover de teste. É possível optar por desligar a VM de origem antes de iniciar o failover para que nenhum dado seja perdido durante a mudança. O Site Recovery não limpará o ambiente de origem após a conclusão do failover.
Após a conclusão do failover, verifique se a VM está funcionando conforme o esperado. O Site Recovery permite que você altere o ponto de recuperação neste estágio. Caso esteja satisfeito com o funcionamento do failover, será necessário Fazer commit dele. O Azure Site Recovery excluirá todos os pontos de recuperação da VM de origem e concluirá o failover. Com a infraestrutura replicada e os dados na região secundária, lembre-se de que a nova VM na região secundária também precisa de proteção.